作者 | 程茜
编辑 | 心缘
智东西10月31日消息,今天凌晨,大模型独角兽月之暗面开源混合线性注意力架构Kimi Linear,该架构首次在短上下文、长上下文、强化学习扩展机制等各种场景中超越了Transformer架构的全注意力机制(Full Attention)。
Kimi Linear的核心是线性注意力模块Kimi Delta Attention(KDA),通过更细粒度的门控机制扩展了Gated DeltaNet,从而能够更有效地利用有限状态RNN内存。论文中指出,Kimi Linear既可以满足Agent对效率和测试时扩展的需求,同时也不会牺牲模型质量。Kimi在社交平台X发布帖子称,Kimi Linear随时可以作为全注意力的直接替代品。
研究人员基于KDA和多头潜在注意力(MLA)的逐层混合,预训练了具有30亿个激活参数和480亿个总参数的Kimi Linear模型。
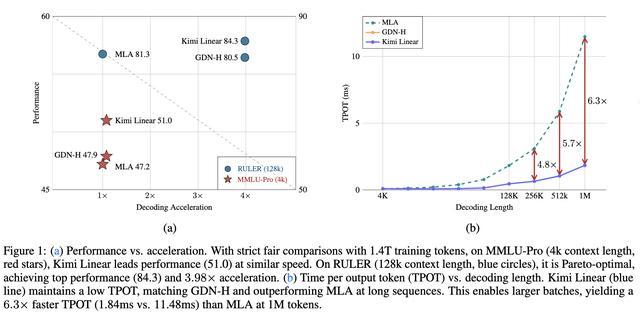
其实验表明,在相同的训练方案下,Kimi Linear在所有评估任务中均显著优于全注意力机制,同时将KV缓存使用率降低75%,并在100万个Token的上下文中解码吞吐量提升6倍。
论文提到,这些结果表明,Kimi Linear可以作为全注意力架构的直接替代方案,并具有更优异的性能和效率。
Kimi开源了KDA内核和vLLM的实现,并发布了预训练和指令调优的模型检查点。
Kimi Linear的Hugging Face开源主页
一、剑指标准注意力机制两大瓶颈,解码吞吐量最高提升6倍
随着Agent热潮涌起,尤其是在长时域和强化学习场景下的推理计算需求正成为核心瓶颈。这种向强化学习测试时扩展的转变,使得模型必须在推理时处理扩展轨迹、工具使用交互以及复杂的决策空间,从而暴露了标准注意力机制的根本性缺陷。
传统Transformer架构的softmax注意力机制,存在计算复杂度高、KV缓存占用大两大瓶颈。
在此基础上,Kimi提出了混合线性注意力架构Kimi Linear,可以满足Agent的效率需求和测试时间扩展性,同时又不牺牲模型质量。
其核心是Kimi Delta Attention(KDA),这是一个硬件高效的线性注意力模块,它在Gated DeltaNet的基础上扩展了一种更细粒度的门控机制。与GDN采用粗粒度的头部遗忘门控不同,KDA引入通道级对角门控,其中每个特征维度都保持着独立的遗忘率。
这种细粒度设计能够更精确地控制有限状态RNN的记忆,从而释放混合架构中RNN类模型的潜力。
至关重要的是,KDA使用Diagonal-Plus-LowRank(DPLR)矩阵的特殊变体对其转移动态进行参数化,从而实现定制的分块并行算法,该算法相对于一般的DPLR公式大幅减少了计算量,同时保持与经典delta规则的一致性。
Kimi Linear将KDA与周期性的全注意力层以3:1的均匀比例交错排列。这种混合结构在生成长序列时,通过全注意力层保持全局信息流,同时将内存和键值缓存的使用量降低高达75%。
通过匹配规模的预训练和评估,Kimi Linear在短上下文、长上下文和强化学习风格的后训练任务中,始终能够达到或超越强大的全注意力基线模型的性能,同时在100万上下文长度下,解码吞吐量最高可提升到完整MLA的6倍。
Kimi研究团队的主要贡献包括:
1、线性注意力机制KDA,改进了门控delta规则,提高了循环内存管理和硬件效率;
2、Kimi线性架构采用3:1 KDA与全局注意力比率的混合设计,在减少内存占用的同时超越了完全注意力质量;
3、大规模的公平经验验证:通过1.4T个token的训练运行,Kimi Linear在短、长上下文和RL风格的评估中优于完整的注意力机制和其他基线,并完全开源了内核、vLLM集成和检查点。
二、通过细粒度门控改进Delta规则,多个组件提升表达能力
论文中介绍了KDA的分块并行化,展示了如何在对角门控下保持稳定性的同时,将一系列秩为1的矩阵变换压缩成稠密表示,在输出阶段,研究人员采用块间递归和块内并行策略来最大化矩阵乘法吞吐量,从而充分利用张量核心的计算潜力。
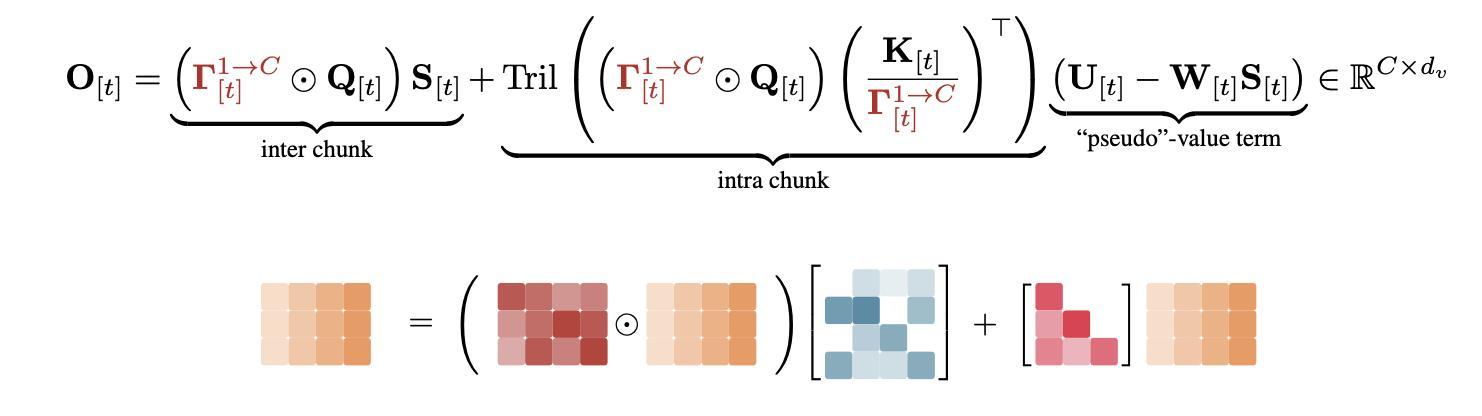
输出阶段
在表达能力方面,KDA与广义DPLR公式一致,两者都表现出细粒度的衰减行为,然而这种细粒度的衰减会在除法运算期间引入数值精度问题。
通过将变量a和b都绑定到k,KDA有效地缓解了这一瓶颈,将二级分块矩阵计算的次数从四次减少到两次,并进一步消除了三次额外的矩阵乘法。因此,与DPLR公式相比,KDA的算子效率提高了约100%。
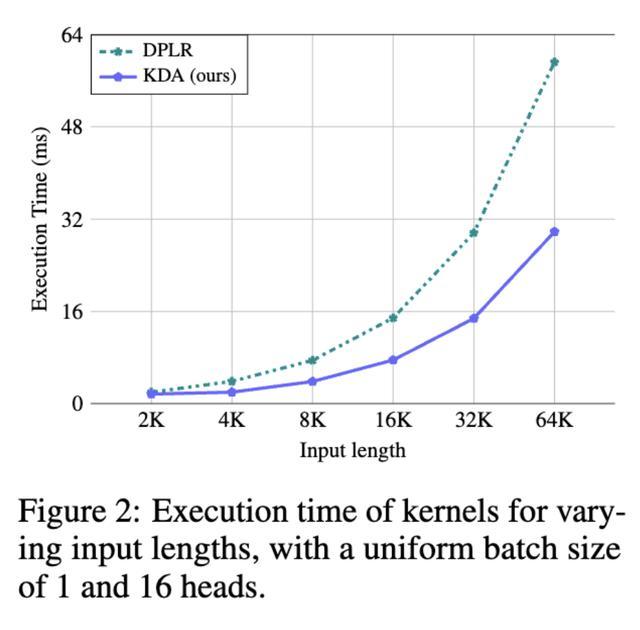
KDA算子效率情况
此外,KDA模型架构主要基于Moonlight,除了细粒度的门控之外,研究人员还利用了多个组件来进一步提升Kimi Linear的表达能力。
神经参数化:输出门采用类似于遗忘门的低秩参数化方法,以确保参数比较的公平性,同时保持与全秩门控相当的性能,并缓解注意力陷阱问题;
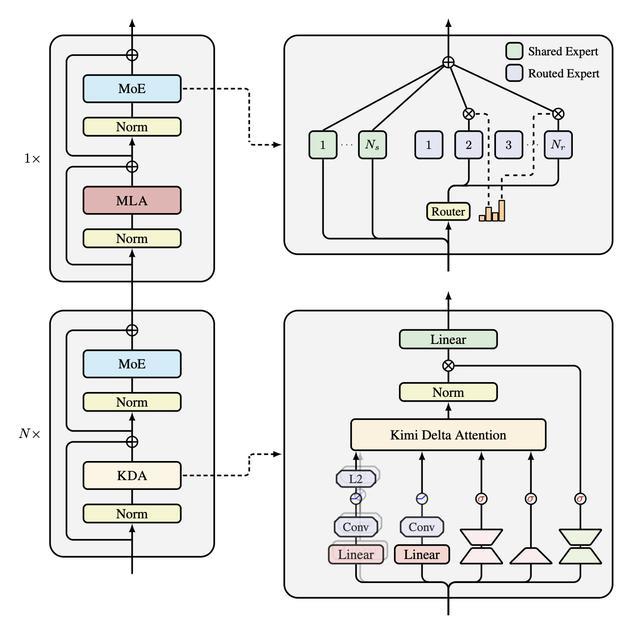
Kimi Linear模型架构示意图
混合模型架构:研究人员将KDA与少量全局注意力层混合。经验表明,3:1的统一比例,即3个KDA层对应1个全MLA层,能够提供最佳的质量-吞吐量平衡。
MLA层不采用位置编码(NoPE):研究人员对所有MLA层应用了NoPE。其发现与先前的研究结果一致,用专门的位置感知机制来补充全局NoPE注意力机制,可以获得具有竞争力的长上下文性能。
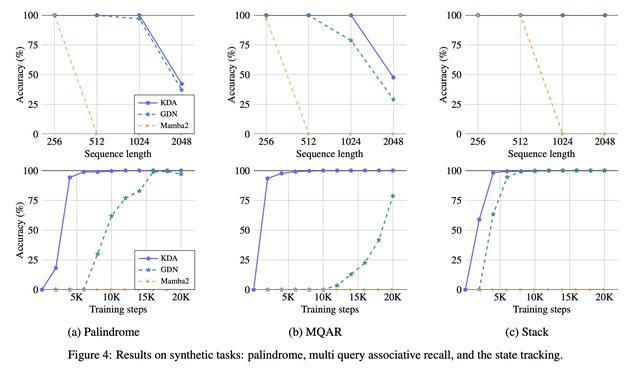
Kimi Linear合成任务的结果
三、性能评估整体优于MLA,通用知识、推理、中文任务得分第一
研究人员评估了Kimi Linear模型与全注意力MLA基线、混合门控DeltaNet(GDN-H)基线的性能,所有基线均采用相同的架构、参数数量和训练设置。
研究人员使用1.4T预训练语料库将Kimi Linear模型与两个基线模型(MLA和混合GDN-H)进行了比较,评估主要集中在三个方面:通用知识、推理(数学和编程)以及中文任务,Kimi Linear在几乎所有类别中都始终优于两个基线模型。
在常识方面:Kimi Linear在BBH、MMLU和HellaSwag等所有关键基准测试中得分最高;推理能力方面:Kimi Linear在数学和大多数编程任务方面领先,与GDN-H相比,其在EvalPlus上的得分略低;中文任务上:Kimi Linear在CEval和CMMLU上取得了最高分。
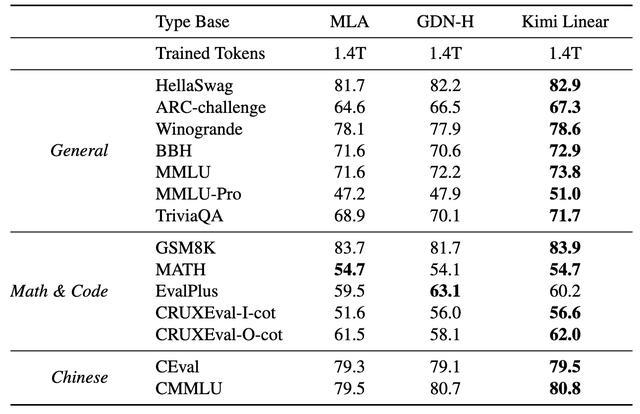
Kimi Linear与全注意力MLA基线、混合GDN基线的性能比较
研究人员称,Kimi Linear可以成为短上下文预训练中全注意力架构的有力替代方案。
在经过相同的监督式微调流程后,研究人员测试发现,Kimi Linear在通用任务和数学与代码任务中均表现出色,始终优于MLA和GDN-H。
在通用任务中,Kimi Linear在各种MMLU基准测试、BBH和GPQA-Diamond上均取得了最高分。
在数学与编程任务中,它在AIME 2025、HMMT 2025、PolyMath-en和LiveCodeBench等高难度基准测试中超越了所有基线模型。
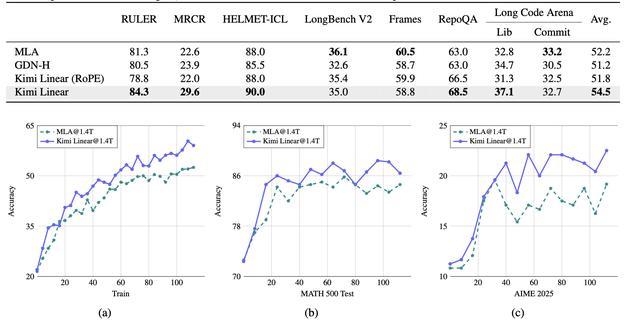
Kimi Linear与MLA、GDN-H在长上下文基准测试中的比较
总体结果总结:在预训练和SFT阶段,Kimi Linear优于GDN-H,GDN-H又优于MLA;在长上下文评估中,这一层级发生了变化,Kimi Linear保持领先地位,GDN-H的性能下降落后于MLA;在强化学习阶段,Kimi Linear性能优于MLA。
效率方面,随着序列长度的增加,混合Kimi Linear模型在较短的序列长度(4k–16k)下,性能与MLA相当,从128k开始速度显著提升。对于512k个序列,Kimi Linear的性能是MLA的2.3倍;对于1M个序列,其性能是MLA的2.9倍。在100万个Token上下文长度的解码效率方面,Kimi Linear的速度是全注意力机制的6倍。
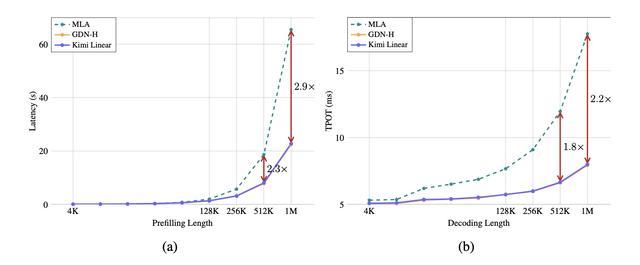
Kimi Linear与MLA、GDN-H在效率方面的比较
结语:攻克全注意力机制瓶颈,Kimi Linear实现性能、效率双超越
Kimi Linear通过KDA的细粒度门控与高效分块算法、3:1混合注意力架构,首次实现性能超越全注意力以及效率大幅提升的突破,且在100万个token长上下文、强化学习等场景中表现突出,使得其可以兼顾效率和可扩展性,为下一代Agent发展、解码密集型大模型提供了高效解决方案。
同时,Kimi Linear可以作为全注意力架构的直接替代品,这意味着在实际应用中,开发者可以直接采用Kimi Linear架构来改进现有模型,而无需进行大规模的重新设计和训练,有效降低开发成本和计算资源成本。
