2024 年,Lunar Lake 实现内存封装进芯片;25 年 Strix Halo 将统一内存带宽推到 256GB/s;26 上半年面市的骁龙 X2 Elite 系列采用了类似的共享内存架构;本周,Windows on ARM 行业再次团结在 RTX Spark 的旗帜下,发起挑战。
大,且统一的内存,用来驱动端侧 AI:说白了,全行业都抄苹果的作业抄到飞起。
但现在的问题是,这些晚了苹果至少五、六年的对手,联合发起围攻,会奏效吗?苹果在统一内存架构上的底气从哪来?
在 WWDC 的前夜,爱范儿专访了苹果 Apple silicon 高级产品经理 Doug Brooks。

Doug Brooks, Senior Product Manager, Apple silicon
比统一内存更重要的是内存带宽
谈起 Apple silicon 的设计逻辑,Brooks 告诉我:苹果是一家不必考虑外部客户的芯片厂商。
「我们不是那种卖芯片的厂商——造一堆芯片,指望别人拿去塞进各种不同的系统,或者利用芯片的不同功能。我们的芯片只为我们自己的系统而设计,系统设计和芯片设计互为彼此的唯一影响。」
本质上,苹果的芯片设计者知道自己需要在芯片里针对何种工作负载、工作流去优化,而反过来,它丝毫不用担心做进芯片里的东西 iPhone、iPad、Mac 等设备利用不上。
光有架构上的领先还不够,Brooks 反复强调的还有「均衡」。
得益于自初代 A 系列芯片便开始采用的统一内存架构,CPU、GPU(包括核内的神经网络加速器)、神经网络引擎(ANE/NPU)等核心计算单元全部位于同一片上,与封装内/片外的内存统一连接。
但比单片设计更关键的是,苹果的统一内存架构能够确保 CPU、GPU 以及神经网络引擎能够共享并调用这个庞大的内存池,如下图所示。
这是迄今为止我们在其它类似的统一内存架构产品上并未看到的。
而从 M5 Pro/Max 开始,苹果也走向两片式封装的融合架构。在这套架构上,单 SoC 内的片间互联位宽不是固定的,会随不同 SKU 增加。Brooks 告诉爱范儿:
「一个系统有很多算力,内存带宽却不够?苹果不会做这样的系统。从 M5 到 M5 Pro 再到 M5 Max,GPU 核心数是两倍和四倍——M5 芯片配备了 10 核 GPU,到 M5 Pro 则扩展至 20 核 GPU,而最高端的 M5 Max 更配备了 40 核 GPU。
但你不应该只看到核心数增加,我们在内存位宽上也翻了倍——随着产品线的升级,我们还将每款芯片的统一内存带宽翻倍。只有这样才能确保用户需要的各种工作流被整个芯片的算力满足。」

「统一内存架构」的数字比较
苹果方面并未直接回应 Apple silicon 与其他市面方案的比较,不过爱范儿将几家采用类统一内存架构的公开规格放到一起比较:Strix Halo 是 256GB/s,GB10/RTX Spark 是 273GB/s,骁龙 X2 Elite Extreme 是 228GB/s,苹果 M5 Max 最高 614GB/s。
换句话说,目前行业已知的所有其它方案,内存带宽才刚摸到苹果中高端的水位,离最高端还差着一倍多。而他们追到这里,却已经用了不止两年的时间。
RTX Spark 的裸片图像 (die shot) 显示,这枚「炸裂」级颠覆性的 SoC,却又存在很明显的瓶颈:它由两枚芯片拼接起来,Blackwell GPU 位于一侧,联发科 CPU 等其他元件位于另一侧,中间靠 NVLink 桥接。

DRAM 和内存控制器位于 CPU 侧,GPU 侧没有内存控制器,GPU 访存需要经由 NVLink 借道 CPU 侧的内存控制器。
也就是说,尽管中间这个 NVLink C2C 的双向带宽能够达到约 600GB/s,这块 SoC 的真实内存带宽并不会超过 GB10 的水平,也即封顶在 273GB/s 左右,四舍五入到 300GB/s。
更值得一说的是,RTX Spark 并非 2026 年的全新设计,甚至连 2025 年都算不上。从 Computex 现场照片中 SoC 上的 2443 刻印意味着它在 2024 年的第 43 周就已封装完成。

Die shot 显示其 CPU 采用联发科 2024 年的公版 X925 和 A725 核心,在 2026 年已经落后至少一代甚至两代。
一颗两年前的处理器,重新包装一下也要当新片发——这本身就说明,统一内存的这阵风有多大。
领先者也有可改进空间
苹果的神经网络引擎 (ANE) 在 2017 年随 A11 芯片登场。在此前的文章中我们论证过,虽然在当时 ANE 仅用于和 AI 大体无关的神经网络计算场景,却为苹果迎接如今的 AI 热潮,特别是端侧 AI 工作流打下了关键基础。
好是好,但长久以来 ANE 都不是开放的——具体来说,虽然 Core ML 框架可以调用 ANE,但苹果没有提供足够的工具和能力,让开发者可以自行决定何时、如何调用 ANE 来处理除推理外的负载。相当于一块算力金矿放在这里,门却被封上了。
于是在今年年初,社区开发者 Manjeet Singh 自己着手对 M4 处理器上的 ANE 进行逆向工程,结果居然真的成功了。他发现 M4 ANE 的功耗效率极高,算力跑满时每瓦足以提供 6.6TOPS 算力。
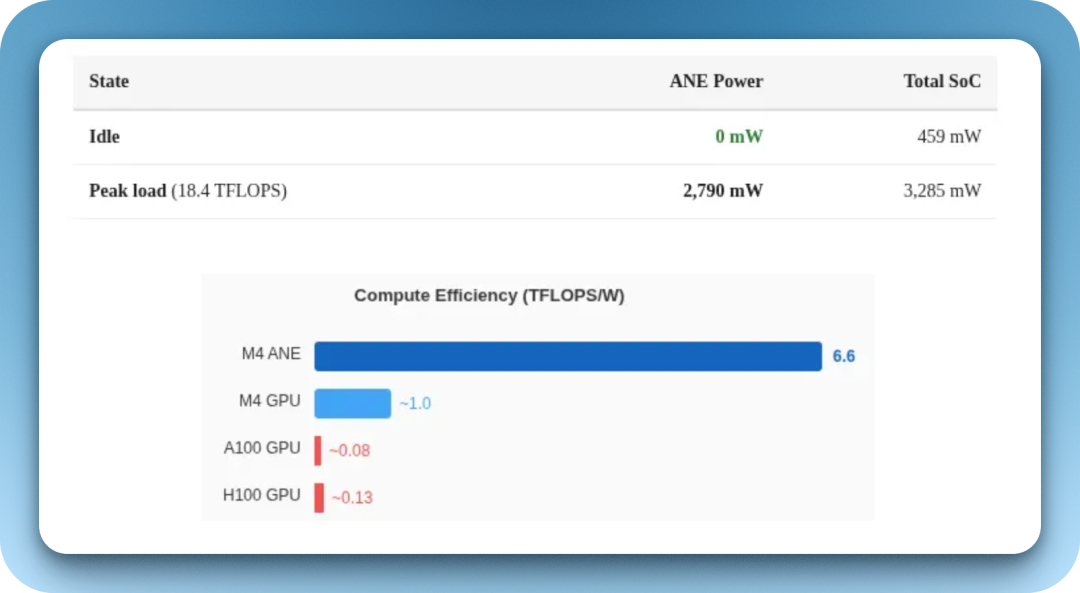
不仅如此,他后来还实现了仅调用 ANE 的算力,且完全越过 Core ML 限制的前提下,在一台 M4 Mac mini 上训练了一个完整的 1 亿参数的 transformer 模型:共用 5 万步,每步 96 毫秒,全程功耗不足 1W(权重和 Adam 优化器仍然需要 CPU 支持,ANE+CPU 功耗低于 8W)。
原来,ANE 也只是一个矩阵乘法计算器 (INT8/FP16),而苹果官方对它的「仅推理」设定也只是一个设定,毕竟训练所用的反向矩乘也是矩乘。苹果只是没有为 ANE 提供公开的训练接口,于是 Singh 自己手搓了一个接口而已。
显然,人们对于 ANE 这座尚未被开采的金矿,是有着浓厚兴趣的。
它的诱人之处不止于 ANE 的功耗性能本身,更在于目前有超过 10 亿台活跃设备搭载它,让 iPhone、iPad 和 Mac 都可以在不影响电池续航和散热表现的前提下,不仅驱动传闻中即将到来的 AI Siri 等一系列 Apple Intelligence 功能,更有潜力处理今天的开发者尚未想象出来的高性能、低功耗的本地 AI 工作负载。
抑或他们早就想到,但实在是苹果之前并不开放 ANE 给他们用。
借这次专访,我们当面问了 Brooks:开发者到底该怎么挑选计算单元,以及苹果怎么看社区对 ANE 的逆向。
他说,苹果提供了一系列不同层级的 API,像 Core ML 这样的高层 API,开发者可以直接说「帮我把这个模型跑起来」,让系统自己决定放在神经网络引擎还是 GPU 上(MLComputeUnits.all);亦或者,开发者也可以反过来说「我就要它跑在 CPU、GPU 或者 ANE 上」。
他特意加重了一句:「我们想给开发者尽可能多的控制。」
这其实说的是在 WWDC 2025 上,苹果首次在 Metal 4 中引入 tensor 作为原生资源类型,从而让用户可以更精细地控制在 shader 或者 GPU 核心内新增的神经加速器里进行计算。
Brooks 并未直接回应对于逆向 ANE 这一事件,但还是给予了社区较高的评价:
「退一步从大局来看,Mac 一直是个充满创新的 AI 平台。我们很高兴看到这么活跃的社区,在各个层面做着各种各样令人兴奋的工作,看到大量的开源研究和贡献。」
矿场的大门不会一直关闭,但是作为场主的苹果,历来对系统安全格外重视,把钥匙发给谁仍然需要谨慎决定。

此外爱范儿还看到,苹果在端侧模型上目前的进展则是另一种稍显遗憾。
苹果的 Foundation Models 框架,将苹果自行训练的端侧大模型直接做进了 iOS 和 macOS 系统本身。开发者通过简短的代码即可调用,没有云端 API 计费,无需购买 token 或者付费订阅,直接离线可用,数据也全程停留在本地并加密。这套架构,目前没有第二家给得出来。Brooks 告诉爱范儿:
「不光免费,还不需要联网,随时随地都能在本地运行,这本身非常强大。更让我兴奋的是,Foundation Models API 已经被数千个应用采用,去做各种大大小小的 AI 功能,不只是简单的文本处理,更是极强的生产力工具。」
但在今天,特别是苹果一直打交道的那些生产力最高、对于变革自己工作流最积极的专业用户,使用 AI 的方式早已经出离简单的对话界面,而是进入到了随时发起任务,就能调起几十上百个 agent 去分割、代理、互相校验、汇总的新工作流时代。
此时,这个本地「小」模型,本身足够聪明吗?
好在答案本身不是二选一。苹果目前的对策,是在 Apple Intelligence 中利用私密云计算技术 (Private Cloud Compute),在安全和数据用后即焚的逻辑下调用云端更强大的模型。
眼下端侧模型,或者更具体来说苹果自己的端侧模型,其天花板清晰可见。约 30 亿参数,在苹果自己的技术报告里提到的擂台对手,是 Qwen-2.5-3B、Gemma 3-4B 等早期、参数量较小的模型。这个规模的模型,在做摘要、改写、修图等轻量生成任务上是把好手,应用场景潜力也颇大。
但一旦碰上复杂推理、代码、需要世界知识的任务,它和现如今 OpenAI、Anthropic、Kimi、MiniMax 等专为 agent 任务而训练的旗舰模型相比,还是捉襟见肘。根据此前最新的公开资料,苹果服务器端的模型尚且「落后于 GPT-4o 和 Llama-4 Scout」,离第一梯队更是遥不可及。
说到底,苹果的护城河在于硬件,在整合,在真正的统一内存架构实现以及消费级电脑市场上难以企及的内存带宽上。但模型本身的能力,反而成了苹果这套体系里最令人担忧的一环。
但苹果或许留有一手。
WWDC 见分晓?
一年一度的苹果全球开发者大会,即将于北京时间 6 月 9 日凌晨召开。
如果此前彭博社苹果专家 Mark Gurman 的爆料属实,苹果很有可能会用一个全新的 Core AI 框架来取代沿用多年的 Core ML。这一传闻中的新框架,将首次允许开发者用他们再熟悉不过的方式,例如 API,来直接接入任选(但原则上苹果认可)提供商的模型。
除此之外,传闻中苹果可能即将启用的新一代端侧基座模型,可能会是一个蒸馏自其他美国头部 AI 企业的新模型。甚至苹果自己也可能挑选 Google、OpenAI、Anthropic 等作为系统默认模型提供商。
苹果方面并未对以上传闻做出回应。
正如前面提到,在模型能力上苹果此前的确落后,而借力打力正是苹果过去多年来与其他硅谷巨头们「竞合」的核心思想——毕竟,没人不想打入数十亿台 iPhone,成为默认的搜索引擎(以前),以及默认的 AI 引擎(现在)。
回头最开始的问题:当全行业对苹果的统一内存架构,在核心硬件产品的品类里发起围攻,苹果为什么并不害怕?
可能从一开始他们就找错了弱点。AMD、英伟达、高通、英特尔纷纷入局统一内存架构,但他们攻击的是苹果最坚硬的那一堵墙。无论怎么追赶,追赶的都是苹果的昨天。
真正令苹果感到危机的,并不是这群人,而是另一群后起之秀,以 OpenAI 为代表。
这不仅仅是因为 OpenAI 有意开发全新形态的 AI 硬件,来创造出一个新的、类似于 iPhone 和 Mac 的现象级品类,从而颠覆苹果;
更因为 OpenAI、Anthropic 们所最擅长的东西,包括并不限于模型本身,以及由新一代 agentic 模型所驱动的新工作、新生活、新计算方式,才是苹果最薄弱的地方。
苹果如何补强这些点?下周 WWDC 见分晓。
(本文所有对第三方厂商的分析内容均来自公开资料。苹果方面从未对第三方厂商公司做出评论。)
作者|杜晨
采访|杜晨
