在品尝过「会前甜点」Android Show 之后,真正的重头戏谷歌开发者大会 Google I/O 2026 正式揭开了帷幕。
不出所料,在时长接近两个小时的活动中,Gemini 占据了绝对的 C 位。

图|Google
除了更新基础模型和周边能力之外,Gemini 也更加深入的集成到了谷歌 app 全家桶里面,甚至还给 iOS 和 macOS 带来了一些更新。
比较可惜的是,上周亮相的 Googlebook 和 Android 17,在本次 I/O 开场活动上都没有被提及。
我们唯一看到的硬件产品,是与三星联合开发的智能眼镜:

图|Google
总之,谷歌借助本次 I/O 大会传达的信息已经很明确了:
Gemini 的能力将会越来越强、存在感将会越来越高,与全球十几亿谷歌产品用户的「物理生活」的集成也会越来越紧密。
从夸张的角度想—— Gemini 距离接管大部分人的日常工作,似乎就只差一个人形机器人了。
底层模型更新
整场活动里最重磅的,就是围绕着 Gemini 的几款底层模型的更新了。
首先是正式的 Gemini 3.5 版本发布,用户最先可以体验到的版本则是 Gemini 3.5 Flash。
它在多个维度上展现出媲美之前 2.5 Pro 的能力,并且保持了 Flash 系列的速度:
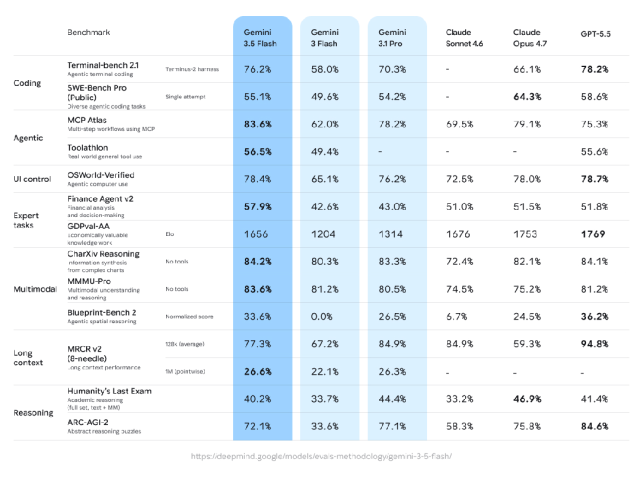
图|Google
得益于速度和性能的平衡,Gemini 3.5 Flash 最擅长的场景之一就是处理长期、大规模的智能任务,同时还能省下大量 token 开销。
同时,最新的 Antigravity 集成也让 Gemini 3.5 Flash 拥有了更丰富的输出形式——
执行分类代码、根据论文编写游戏、转换上古代码库、构建 3D 场景、交互式 Web 界面等等。
将遗留代码库转换成 Next.js|Google
此外还有规模最大的「世界模型」Gemini Omni,用谷歌的宏愿来描述 Gemini Omni 则是:
它可以根据任何输入内容,输出任何你想要的东西(Generate any output with any input)。
Omni 的首款模型产品则是 Gemini Omni Flash,除了 Gemini app,它也集成到了 Google Flow 和 YouTube Shorts 里面,支持用户使用自然语言生成「最像真的」的视频。

图|Google
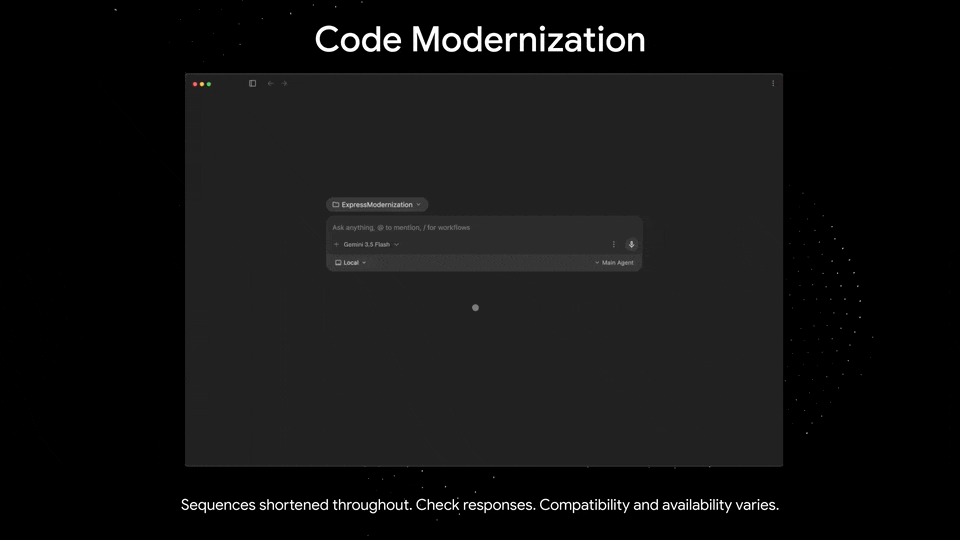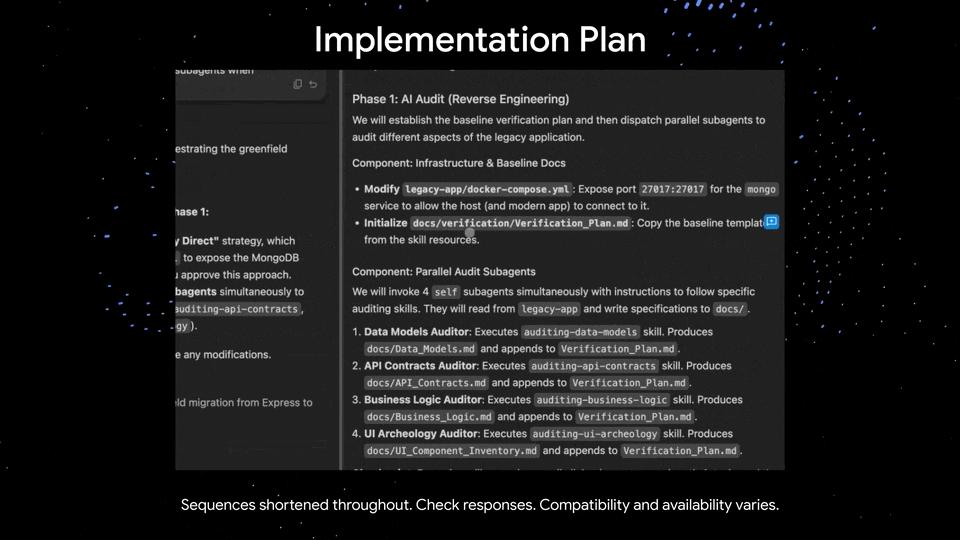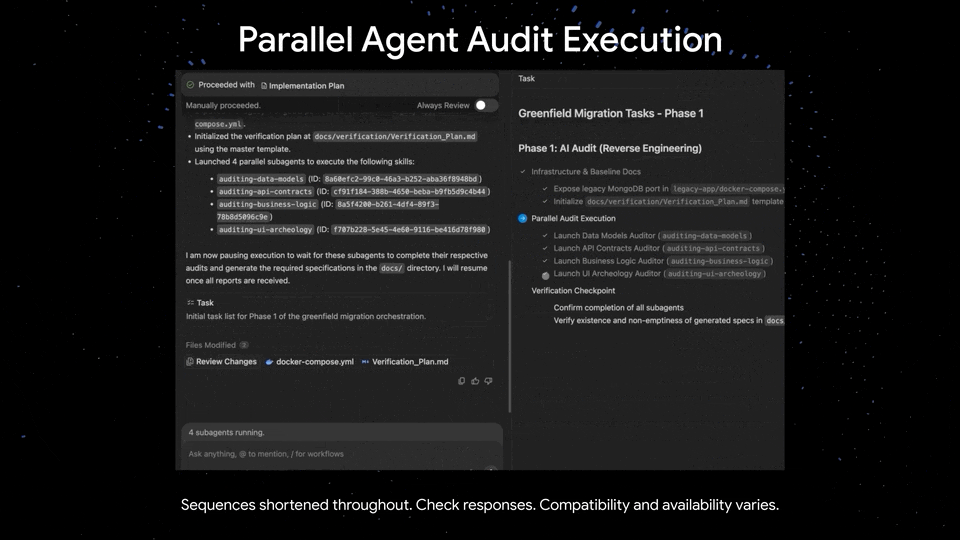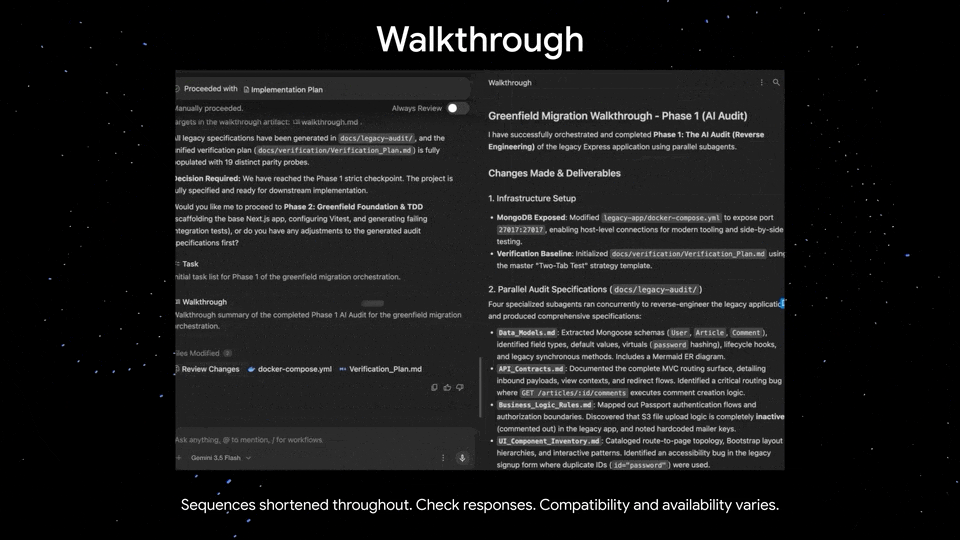
相对应的,谷歌也调整了自己的 Google One 订阅模式,在原本最高等级的 AI Ultra 方案里新增了一个 100 美元/月的分类。
这个新的订阅同属于 AI Ultra 级别,包含 Gemini 3.5 Flash、Antigravity 2.0 和其他新功能的优先访问权等等。
当然,传统的 20TB 云空间和 YouTube Premium 权限也同样包含,主要面向开发者和高级创作者之类的群体。

图|Google
同时,原本 250 美元的最高等级 AI Ultra 订阅则迎来了降价,现在只需要 200 美元/月就能享受到包括最高 20 倍于 AI Pro 的使用额等等特权。
另一个重大的收费模式变革则是 Gemini app 本身。
图|Google I/O
在新闻稿里,谷歌宣布将 Gemini 的每日限额从「提示词额度」改成了「使用量计算」。
这样算下来,图片、视频和代码的消耗变多、文本任务消耗量则变少,整体是一种更灵活的算力计费模式。
实际业务落地
与 OpenAI、Anthropic 之类的公司不同,谷歌最大的特点在于,它真的有一套能够直达全球十几亿用户的产品生态。
在上述基础模型之外,谷歌本次展示的策略,重点是将这些「抽象」的 AI 模型能力,整合进普罗大众每天都在使用的 app 里面。

图|SlashGear
而这种整合大体上分成三步:传统搜索业务变革、手机系统智能化、视觉智能融合。
「搜索引擎」作为谷歌的起家业务,在今年的 I/O 上迎来了一次彻头彻尾的 AI 改造,谷歌称之为「AI 搜索的新时代」。
这种业务转变背后的逻辑很简单:相比 20 年前,人们只在搜索框里输入单词或短语,现在的人更习惯在里面输入复杂的复合指令。
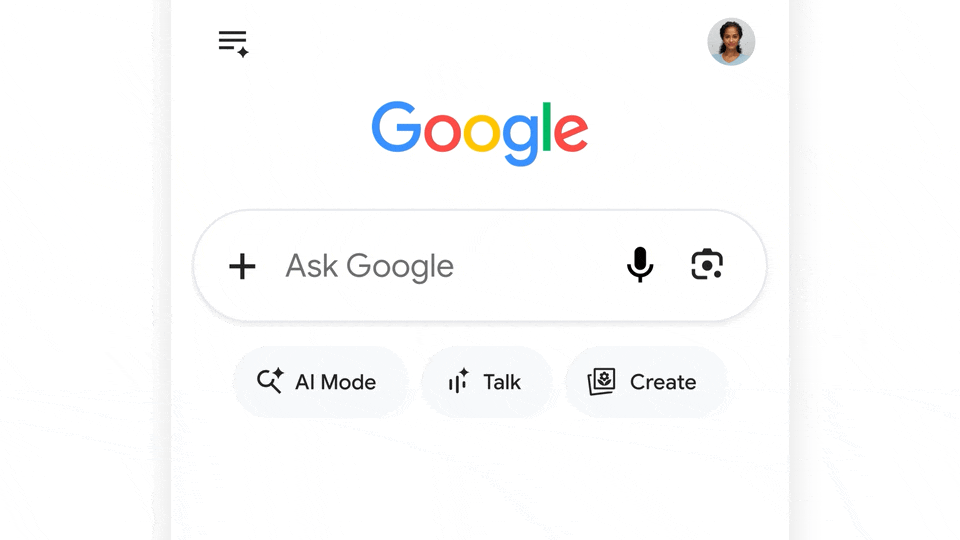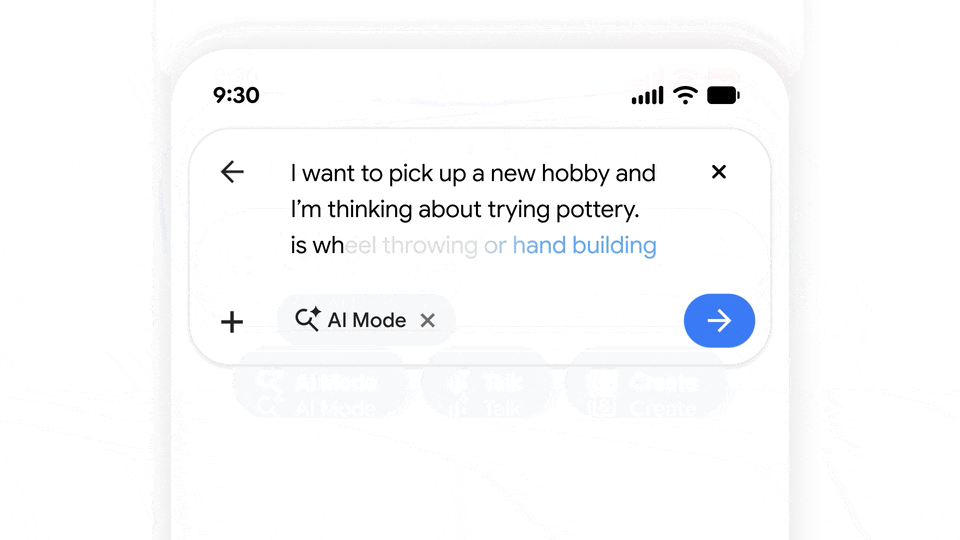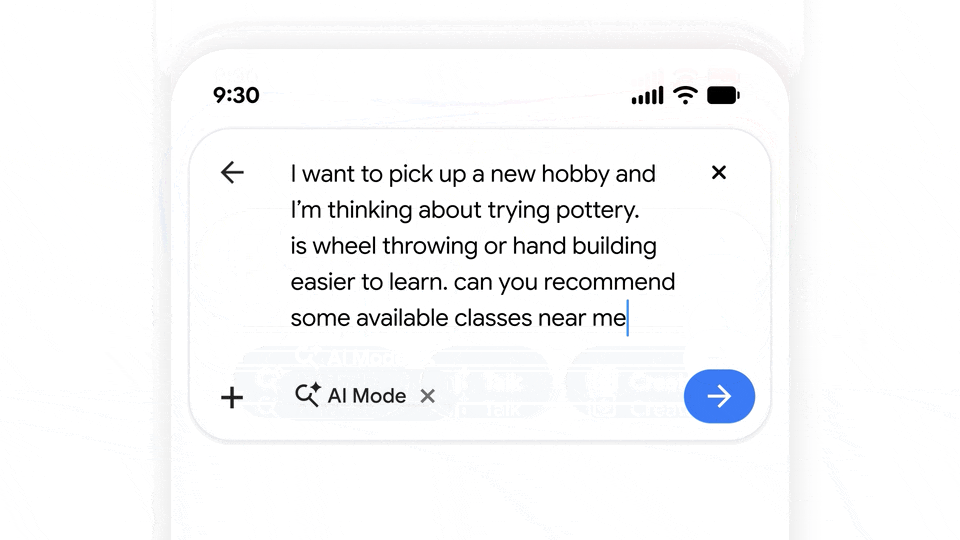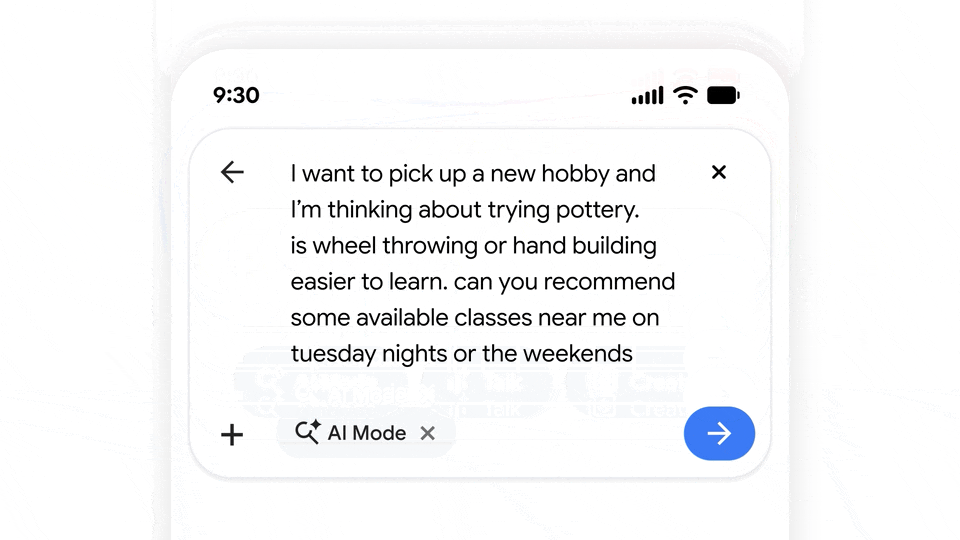
图|Google
换言之,谷歌把传统的搜索框(search box)变成了一个通用对话框(chatbox)。
除了搜索,用户可以在里面要求任何形式的内容。
这刚好也是本次 I/O 活动的重点更新内容——具有智能体能力的搜索。
首先,AI Mode 的基础模型会升级到 Gemini 3.5,你的搜索框会自动推荐和补全输入的内容,让你的关键词变得更详细或者更广泛。
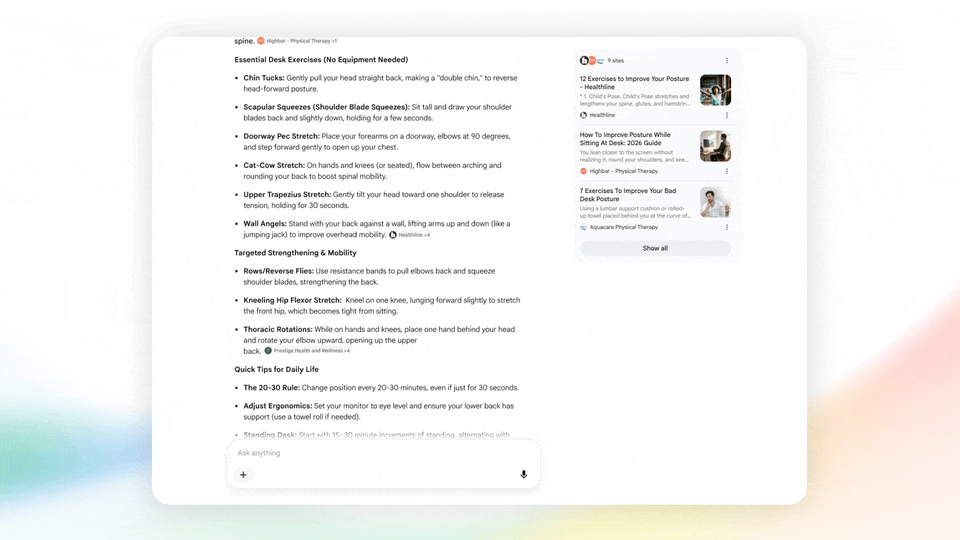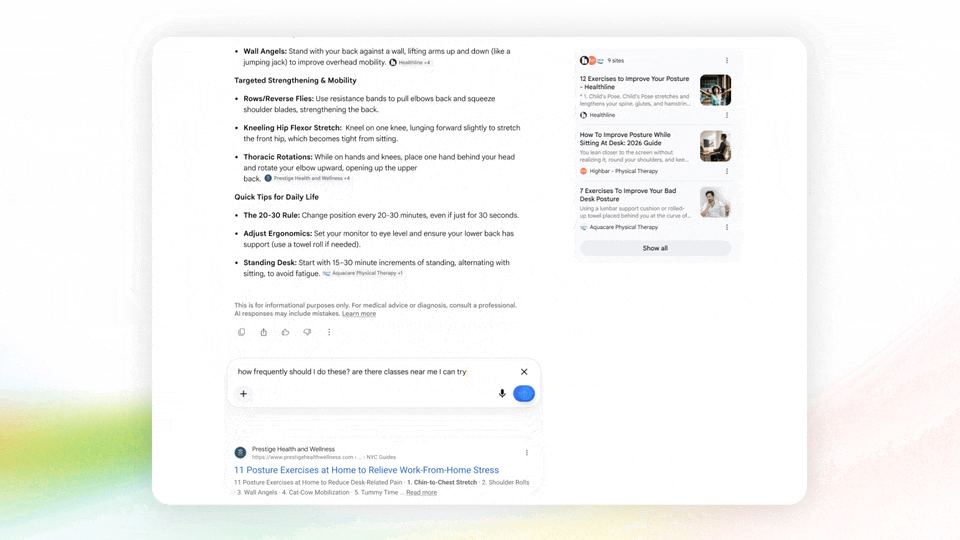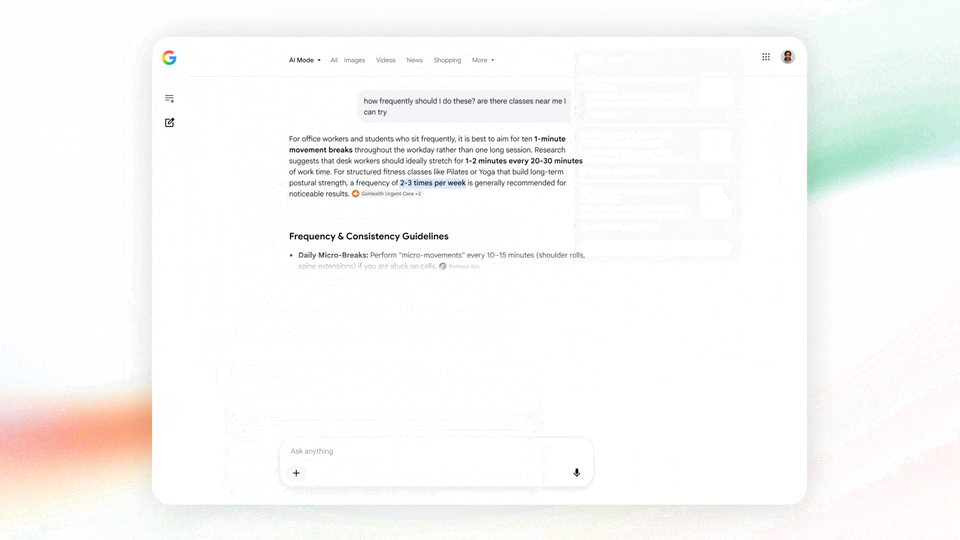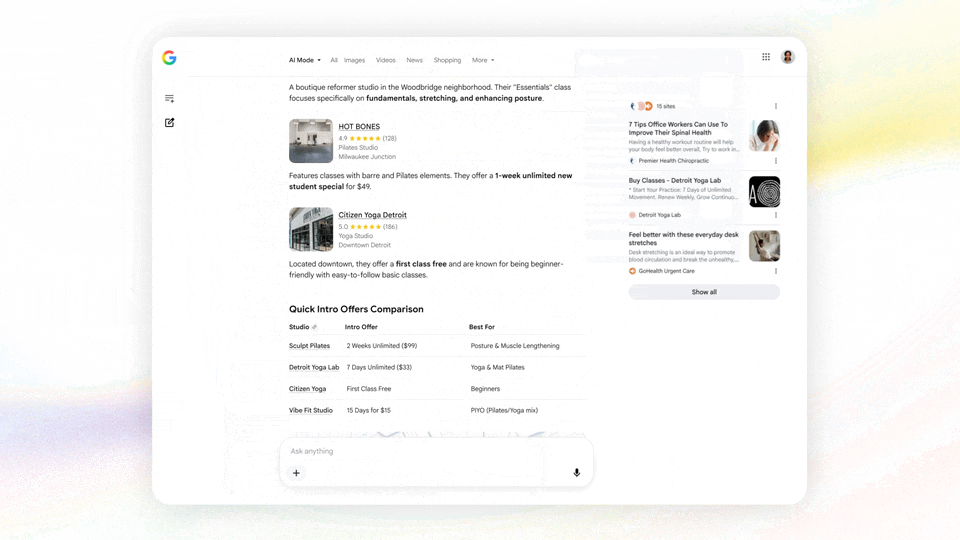
图|Google
此外还有全新的生成式 UI(Generative UI)回答,谷歌会根据你询问的东西智能生成最合适的回答形式。
比如搜索股票走势,回答里不仅有文本,还会生成折线图;问装修灵感,回答里就生成图片……
甚至你搜索物理问题,它还能调用 Antigravity 快速编写一个互动式的 Web 演示:
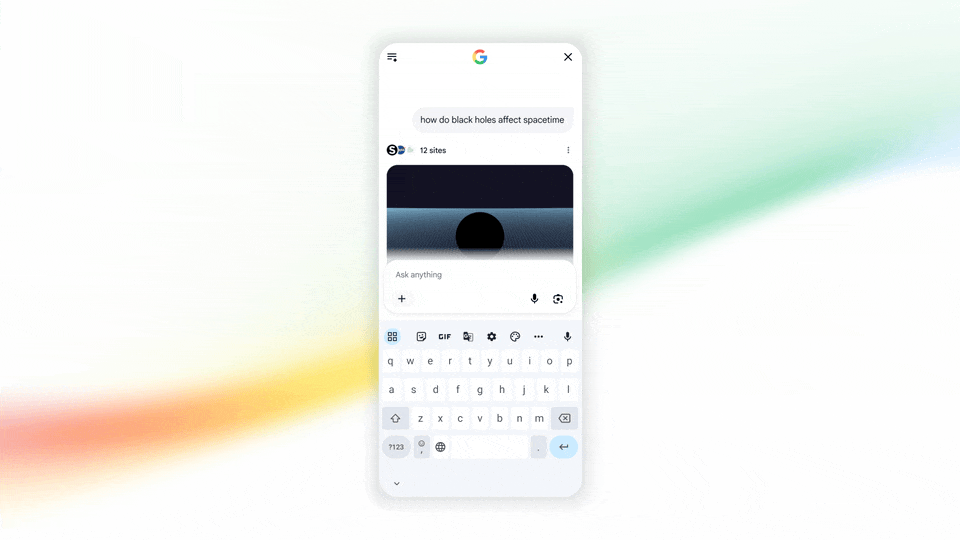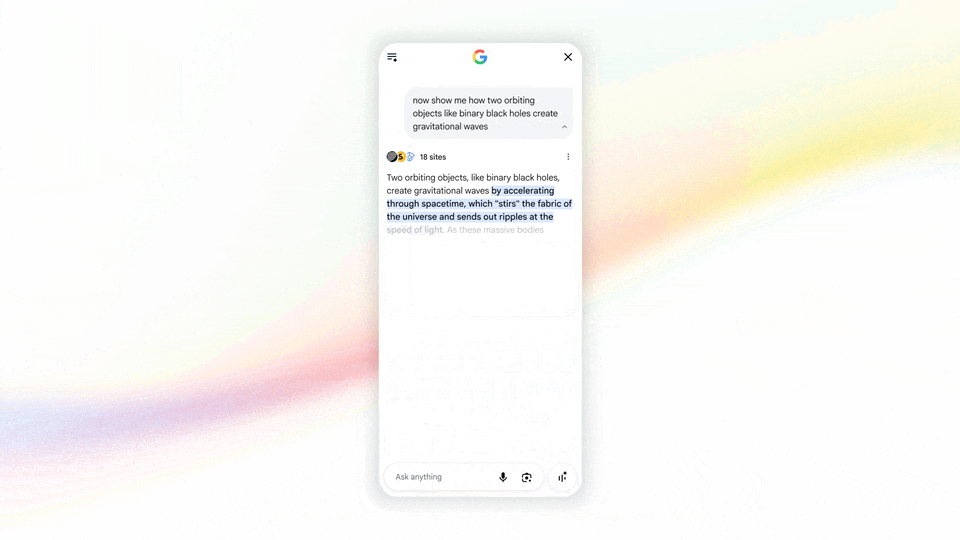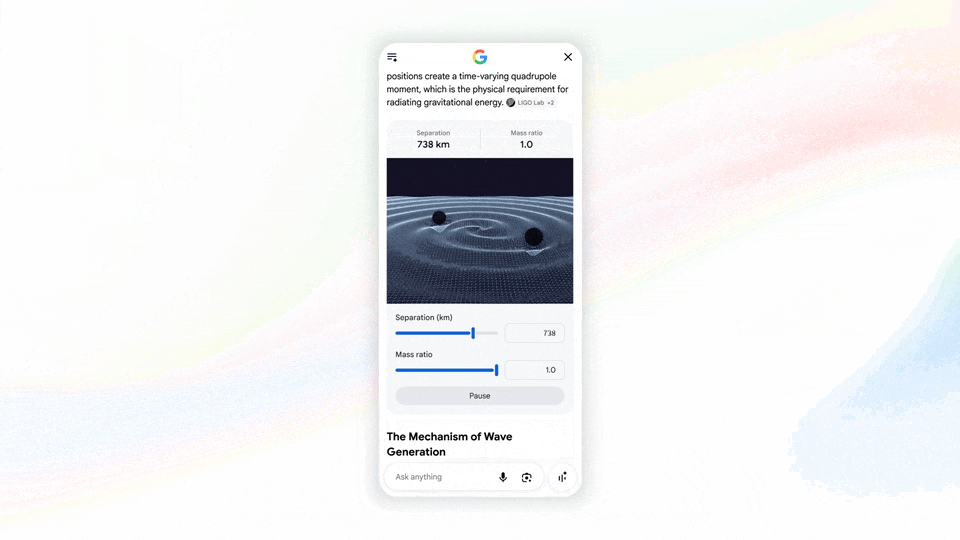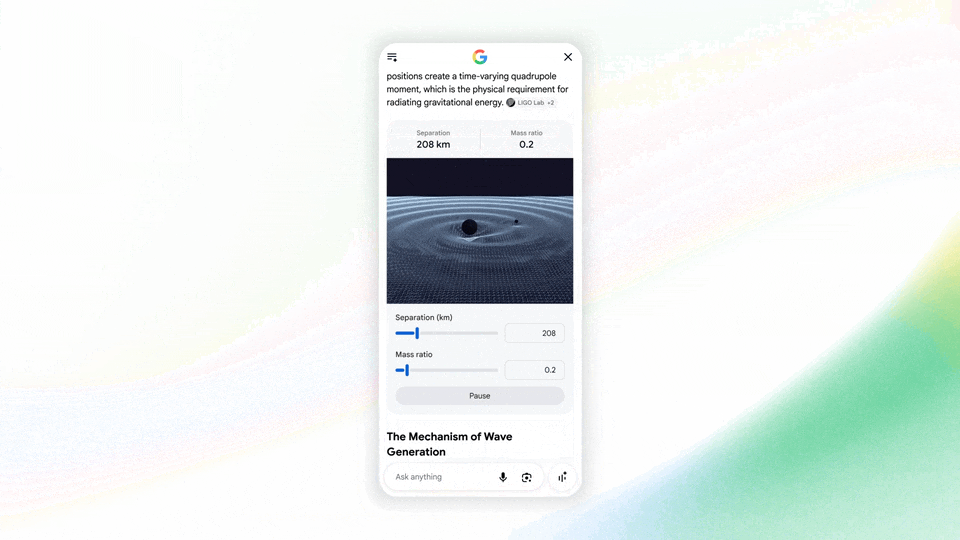
图|Google
使用了这么多年的「多模态搜索」之后,我们终于进入了「多模态回答」的时代。
谷歌搜索结合 Antigravity 的能力不止于此,它还可以更进一步,根据你在搜索框里输入的内容实时生成 Web 形式的仪表盘或追踪器。
用人话来说,就是谷歌搜索框为你的需求直接编写了一个专门的 app。
这种多模态能力是非常恐怖的,甚至有可能彻底改变人们检索信息的方式——
毕竟我们搜东西,大多是为了将搜索结果用在别的任务里面,而新的谷歌搜索可以直接帮你做完下一步操作。
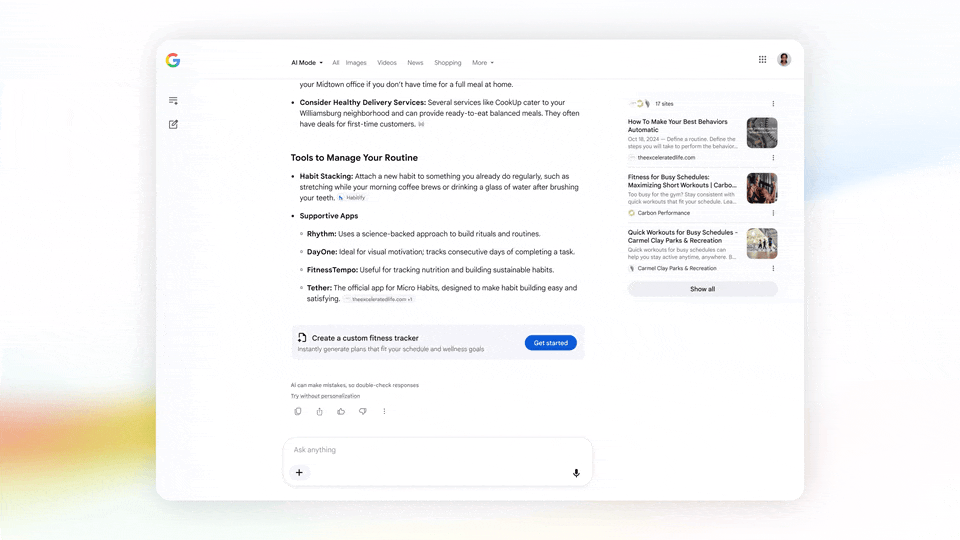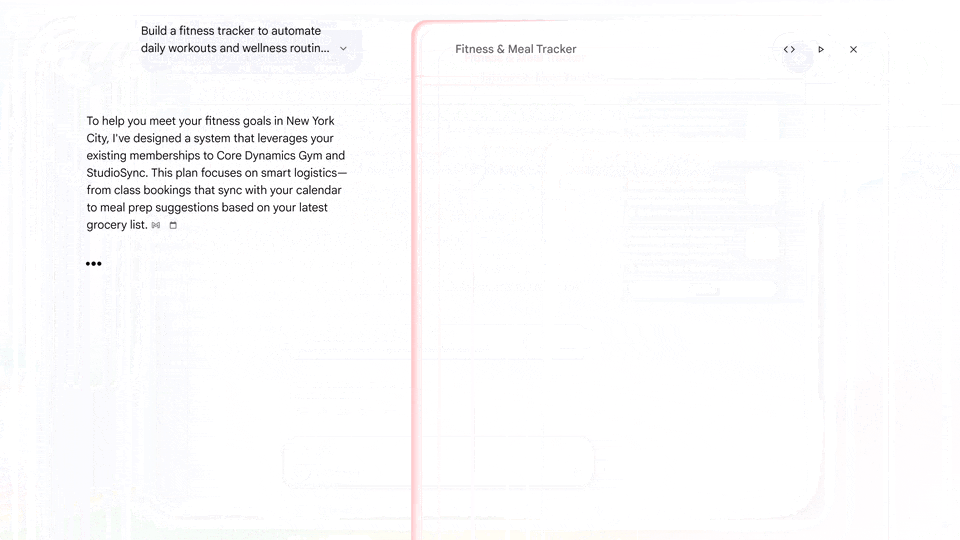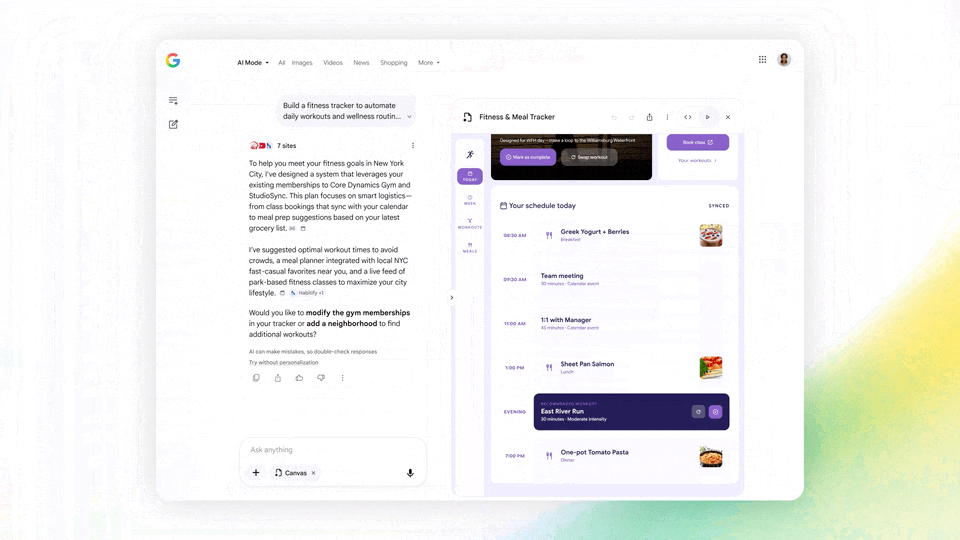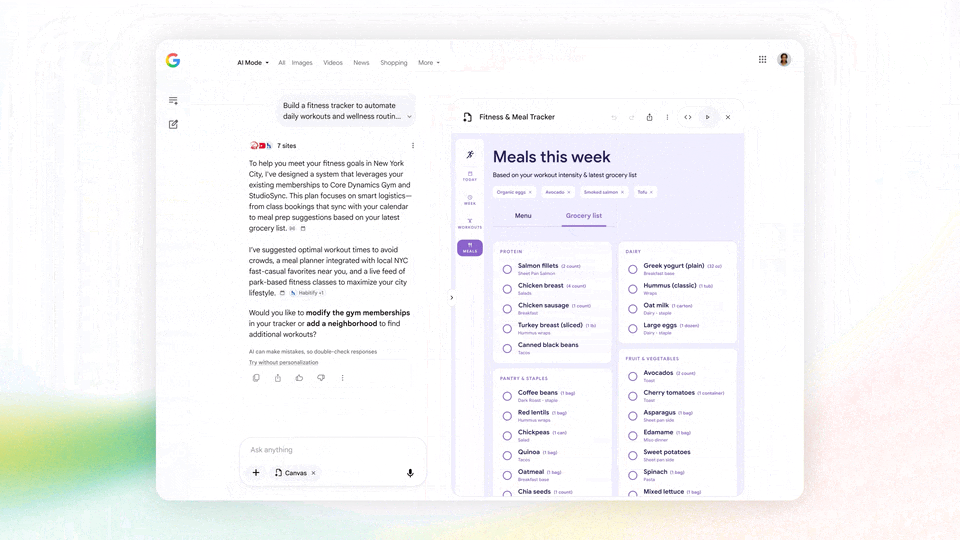
图|Google
至于这种「代办」的具体方式,则是 Gemini Spark。
简单来说,Gemini Spark 本质上是类似 OpenClaw 的「语义理解-自动执行」功能,一个谷歌 Claw。
其中 Gemini Spark 基于最新的 Gemini 3.5 模型,支持 7 天 24 小时不间断运行。
并且由于运行载体是 Google Cloud,还可以执行跨端代理操作——在手机上布置任务,在电脑上查收结果。
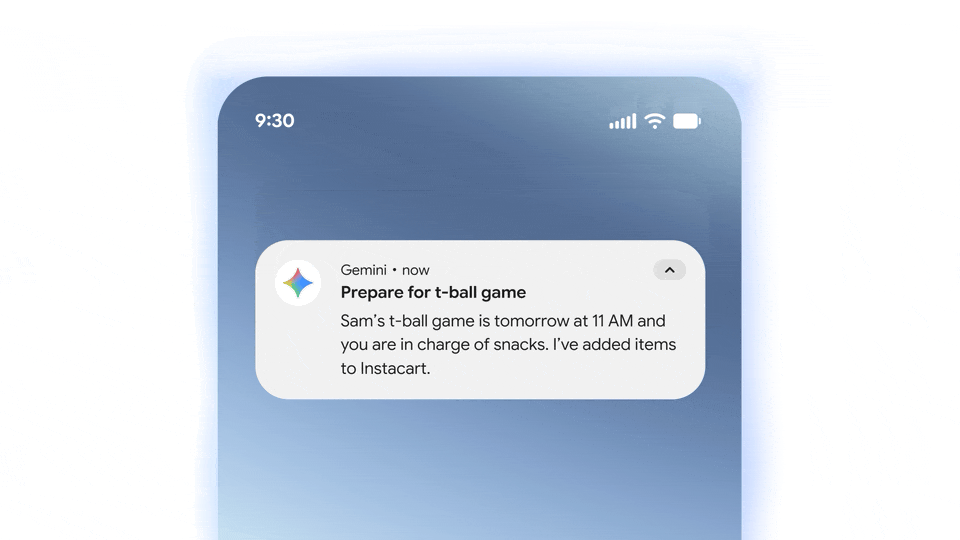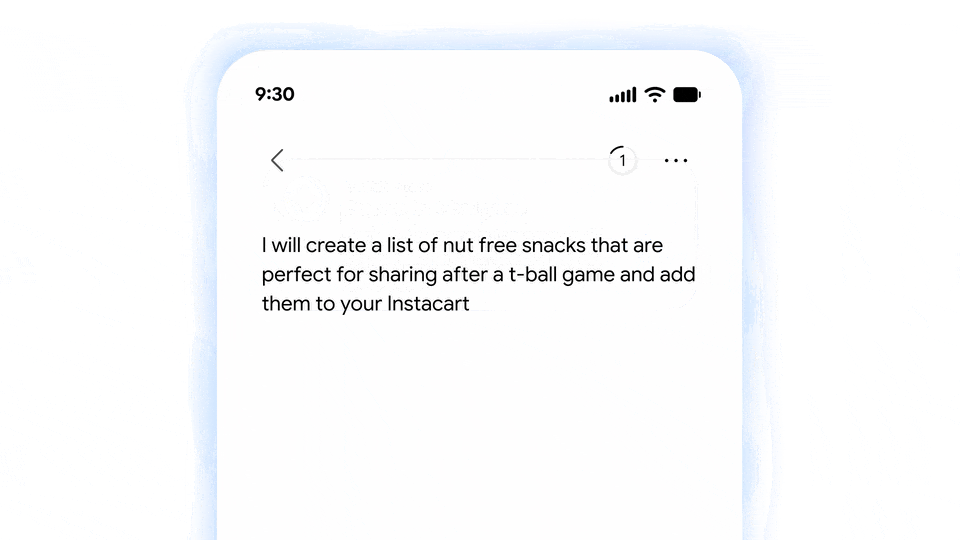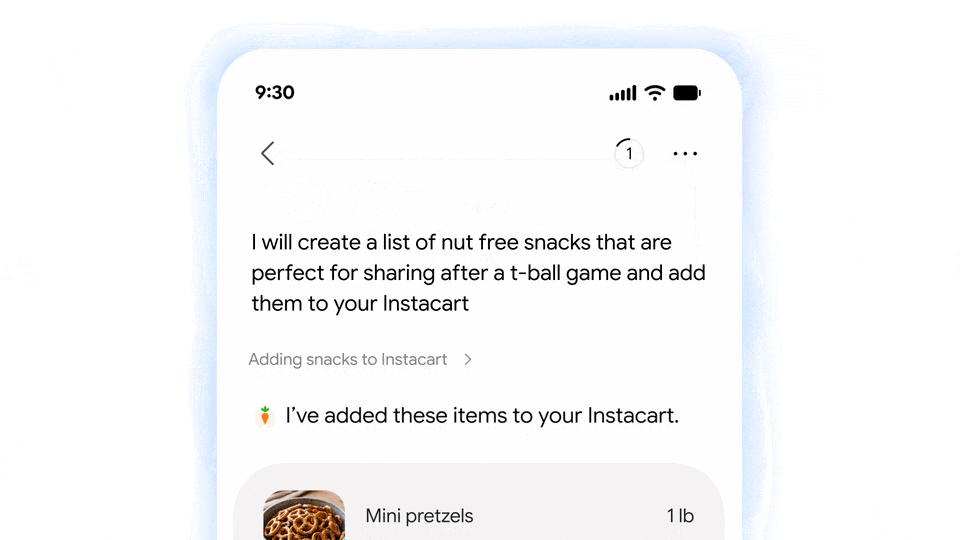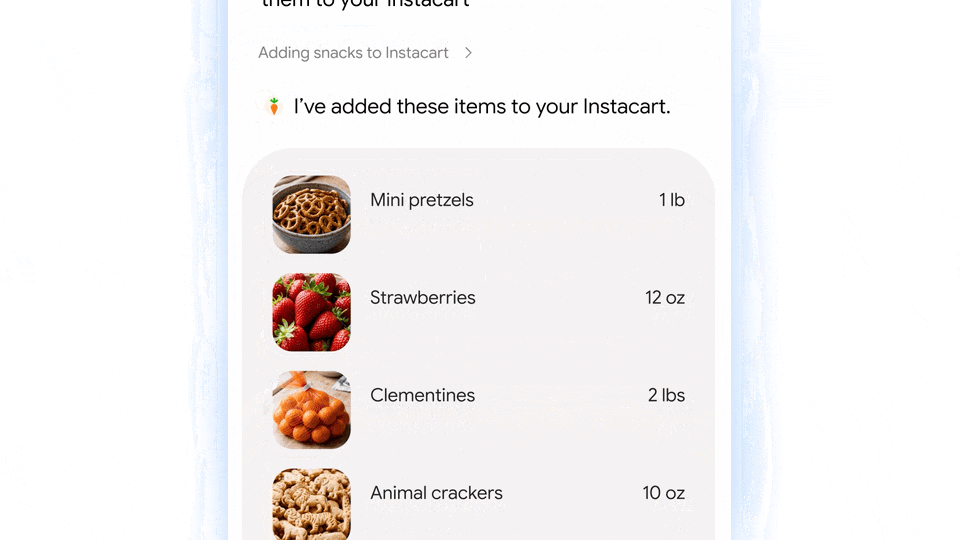
图|Google
Gemini Spark 目前支持所有谷歌套件 app,后续则会拓展 MCP 平台以兼容第三方 app 的内部功能,同时支持用户自己上传 Skill。
谷歌还宣布 Gemini Spark 后续会集成到 Chrome 和 Android Halo 中,为浏览器和手机带来智能体自动操作的功能。
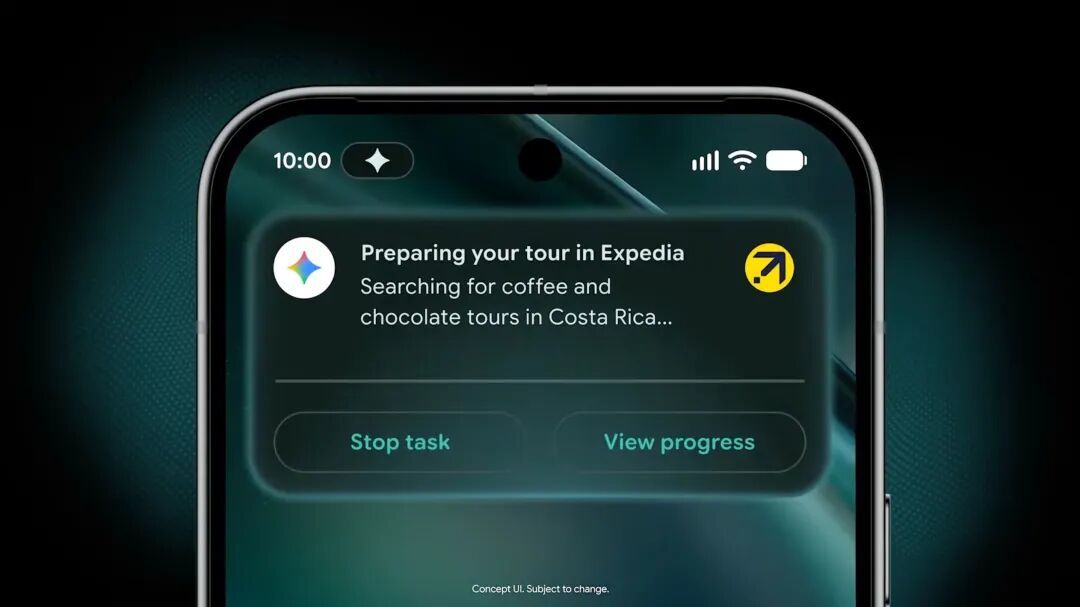
Android Halo|Google
最后一步棋,则是 Gemini 与视觉智能的融合。
在本次 I/O 活动上,谷歌发布了首个与三星联合开发的「纯音频智能眼镜」产品,分别使用 Gentle Monster 和 Warby Parker 镜架:

图|Google
单纯从功能上讲,这个纯音频眼镜与市面上已经有的智能眼镜相差不大,主要优势是可以直接调用 Gemini 的多模态功能,用来调用前面提到的其他复杂能力。
另一方面,XREAL 与谷歌合作的那款带屏幕的智能眼镜 Project Aura 在本次活动上又有了更新。
根据介绍,Project Aura 搭载了 XREAL 自研的 X1S 空间计算芯片,并为了佩戴舒适采用了分体式的设计。
也就是说,Project Aura 的眼镜部分只负责显示,真正的处理芯片、电池包和触控板需要通过数据线连接到一个外置的随身单元上:

图|TheVerge
至于实际的生活功能方面,Project Aura 将会支持 Google Maps 沉浸式导航、巨幕/窗口化视频播放、YouTube VR 视频、WebXR 三维绘画、DP 拓展笔记本屏幕等等用法。
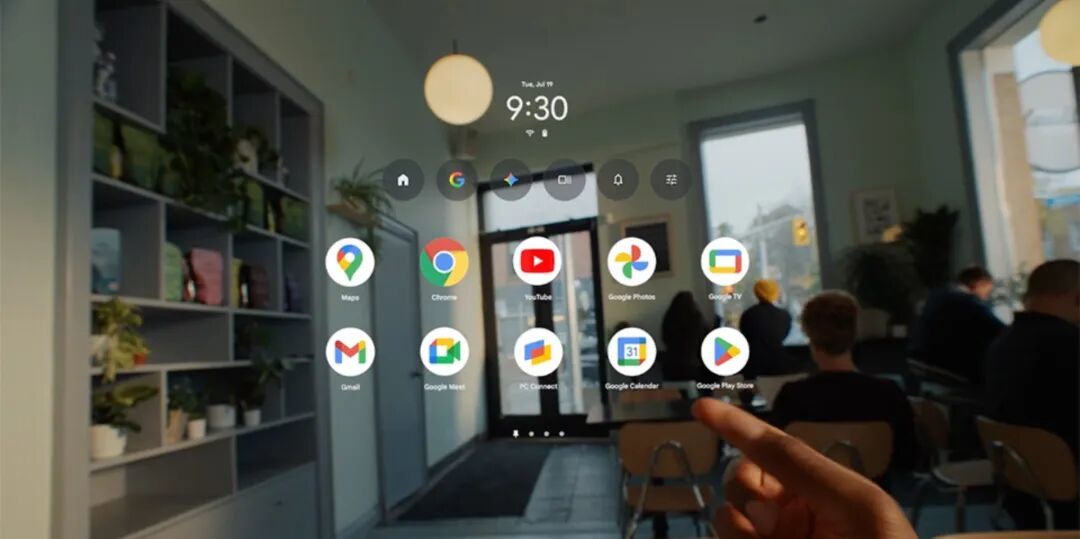
图|TECHEBLOG
总体来说,Android XR 是一套完全基于空间计算的视觉化的操作系统,与 Gemini 的能力搭配起来,为我们画出了一套未来智能眼镜的线路图。
更重要的是,虽然现在 Android XR 和 Android 17 是两个完全独立的系统,但就像 Android 和 ChromeOS 融合那样,它们未来大概率也会合二为一、变成一个「视觉智能系统」类似物。
Gemini 能接管一切吗
熬夜看完整场 Google I/O 之后,除了 Gemini 3.5 和它的小伙伴们带来的惊讶之外,我们难免也诧异于 AI 对于人类基础行为的革命。
无论是 Gemini 3.5 Flash、Antigravity、Gemini Spark,它们都隐藏在了一个简洁的「搜索对话框」背后,将搜索这一行为从「获取信息」进化成了「完成任务」。

图|Google Search
我们很难说这种进化在长期来看会对我们使用网络和人工智能产生什么影响,但我们至少可以从里面看到谷歌的野心——
为一套强悍的 AI 模型赋予前所未有丰富的功能,并且将这些功能集成进自己覆盖全球几十亿用户的网络产品里,共同提升这几十亿人的效率。

Gemini 同时切进所有这些网络产品,副作用是「应用」这个概念正在变薄——
Agent 越能办事,应用内部和搜索结果页的存在价值就越被稀释。
至于这层智能会把多少旧规则一起重写,现在没人能答,谷歌自己也答不上来。
作者|马扶摇
编辑|肖钦鹏
