天天被 AI 刷屏,这个五一假期我真的不想再看到 AI 生成的内容了。
结果我难得打开电视,却发现,电视台已经开始用 AI 主持人来播报新闻。

湖南经视在《经视新闻》宣布启用 AI 主播「声声」和「双双」,这也不是说湖南卫视要用 AI 完全替代真人,这两位 AI 主播暂时只在五一假期期间播报常态化新闻,同时画面中也标注「AI 生成」。

AI 主播与真人主播合影
虽然如此,依然引发了大量网友吐槽,话题一度冲到微博热搜第一。
在港剧《新闻女王 2》里有一段这样的剧情,主播文慧心离开电视台后,老东家把她和一位已故男主播「蒸馏」成 AI 数字人,继续在台前播报新闻。

现在,这样的剧情已经成真。去年开始,越来越多的电视台已经开始试点类似的 AI 主播。
或许你一时间还不能接受 AI 主播,但说实话,现在用 AI 搜新闻看新闻,已经十分普遍了,搜索引擎也把 AI 搜索融入到了搜索框里。
实际上,比起 AI 主播,用 AI 看新闻是现在更需要警惕的。而未来,大量 AI 主播播报 AI 搜集撰写的新闻,才是最可怕的。
一个调查数据显示,Google AI 搜索新闻的结果,十条就有一条是错的。
去年年底,住在多伦多的 41 岁数据分析师 Stephen Punwasi 在准备晚餐时看到一条新闻,说传奇摔跤选手霍尔克·霍肯的死亡可能会引发诉讼。Punwasi 从来没听说过霍肯已经去世了,于是打开 Google,想查查这件事是什么时候发生的。
Google 给他的第一条回答来自自家的 AI Overview :「没有可信的报道表明霍尔克·霍肯已经去世。」
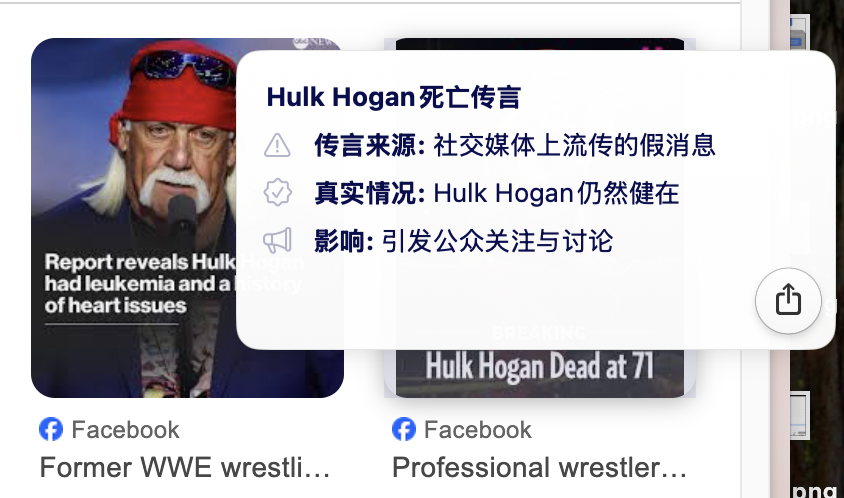
可就在这个回答的下方,Stephen Punwasi 看到第一条搜索链接就是《每日邮报》的一篇文章,标题是:「霍尔克·霍肯死亡之谜加深。」
人都懵了,这是怎么个事呢?
每小时超 5700 万条错误信息
2024 年,Google 开始在搜索结果页面最顶部放置 AI 生成的摘要回答,叫做 AI Overviews。这个动作是 Google 生态全面加速 AI 化的第一波动作,把搜索引擎从一个信息的「策展人」变成了一个「发布者」。它不再只是告诉你哪里有答案,而是直接告诉你答案是什么。
《纽约时报》委托 AI 初创公司 Oumi 对这个功能进行了系统测试。他们用行业标准的 SimpleQA 基准测试检查了 4326 次 Google 搜索的 AI Overview 回答,分别在去年 10 月(基于 Gemini 2)和今年 2 月(升级到 Gemini 3)进行了测试。
结果发现 Gemini 2 时期,准确率约 85%,错误率 15%。到了 Gemini 3 时期,准确率提升到 91%,错误率 9%
乍一听 90%准确率听起来还不错,但考虑到 Google 每年处理超 5 万亿次搜索,即便只有 9%的错误率,换算下来也是每小时超 5700 万条错误信息,每分钟数十万条。
这些错误答案被放在搜索结果的最顶部,用最权威的排版呈现,用户看到的第一个东西,就是 AI 的回答。
看起来像答案,但不是答案
AI 会稳定出错,出差错的方式倒是花样繁多,比如像开头的故事那样,属于是直接答错。
直接答错看似最不应该,实则相当频繁。在测试里,当被问到鲍勃·马利的故居是哪一年改建为博物馆时,AI Overview 回答说 1987 年。但正确答案是博物馆在 1986 年 5 月 11 日开放,也就是马利去世五周年纪念日当天,牙买加《每日光明报》在开馆第二天就报道了。

牙买加国家图书馆收录的相关报道
AI Overview 引用了三个来源:一个是马利女儿的 Facebook 帖子(根本没提开馆时间),一个是旅游博客(信息不准确),一个是 Wikipedia 页面,大家都知道,Wiki 的页面变化非常频繁,根本就不准。
有事后出错则是因为信息有一个模糊的来源,需要谨慎判断,但 AI 推断错了。比如当被问到哪条河流在北卡罗来纳州戈尔兹伯勒市的西侧时,AI Overview 回答说是尼斯河(Neuse River)。它正确地找到了一个旅游网站说尼斯河「流经该市」,但错误地推断出它「在西侧」。实际上西侧的是小河(Little River),尼斯河在西南方。
最离谱的一种出错方式找到了正确的来源,但给出相反的答案。当被问到大提琴家马友友是哪一年被引入古典音乐名人堂时,AI Overview 正确地链接到了该组织的官网,网站上明确列出了包括马友友在内的 165 位入选者。但 AI 的回答却说:「没有记录显示他被引入过。」

睁着眼睛说瞎话是吧,哦不,AI 没有眼睛。
「它看起来像个正经答案啊」
Oumi 分析了 AI Overview 引用的 5380 个来源,发现 Facebook 和 Reddit 分别是第二和第四大被引用源。当 AI Overview 给出错误回答时,引用 Facebook 的比例是 7%;当回答正确时,这个比例是 5%。
社交媒体是主要的信息来源,但缺乏核实
换句话说,你看到的那个「最权威」的回答,数据来源可能是一条 Facebook 帖子,真是没招了。
而且,即便回答本身是正确的,也不代表你能逆向查验。Gemini 3 版本的 AI Overview 中,56%的正确回答是「无根据的」,意思是它链接的网站并不完全支持它给出的信息。或许答案本身没错,但你硬是找不到证据做实它是对的。这个比例还在上升,去年 10 月是 37%,升级到 Gemini 3 之后反而涨到 56%。
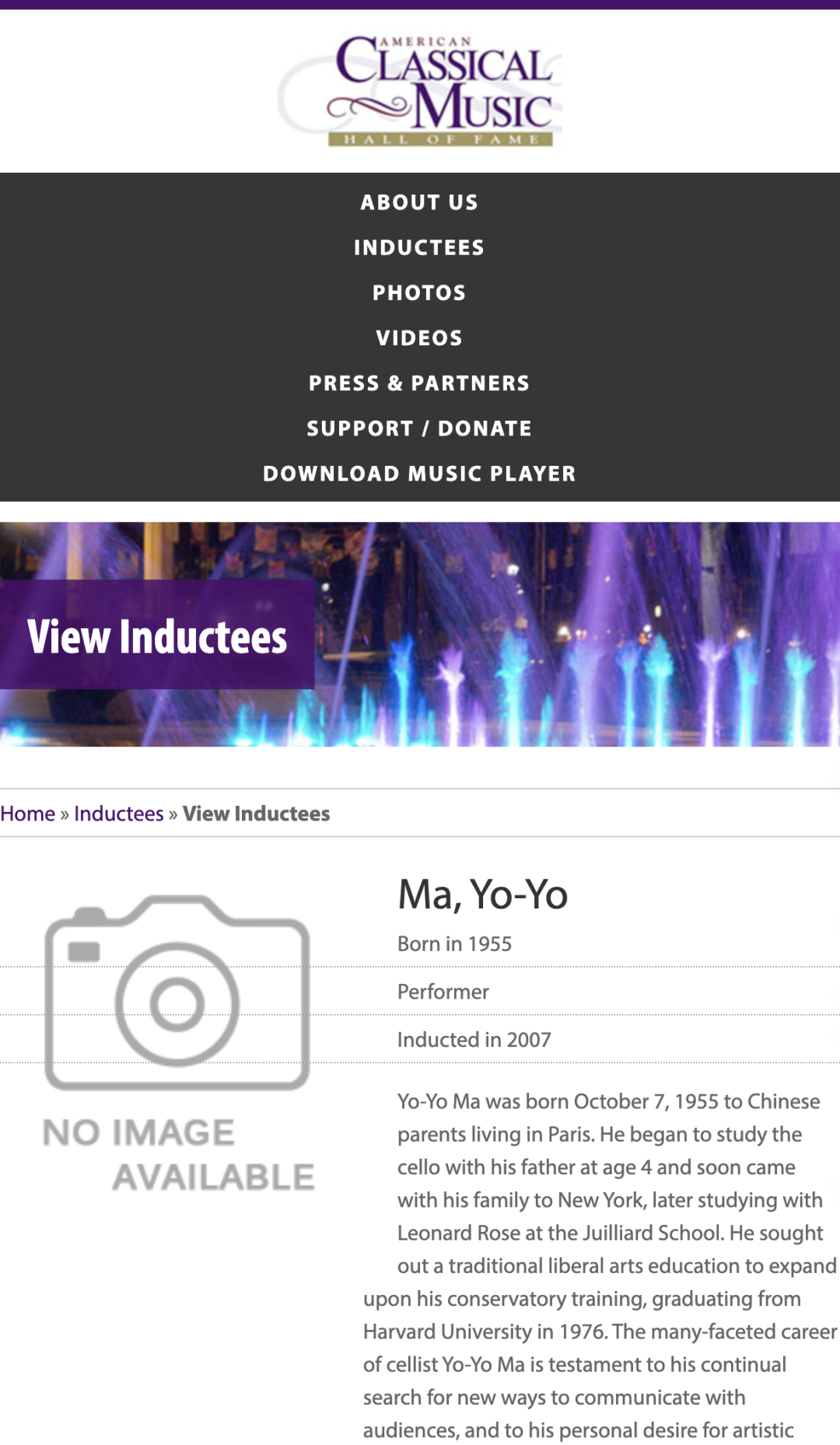
马友友的名人堂条目需要进一步在网站内检索才能获得
Oumi 的 CEO Manos Koukoumidis 的总结很直接:「即使答案是对的,你怎么知道它是对的?你怎么检查?」
还有一个问题:AI Overview 可以被操纵。
BBC 播客「The Interface」的联合主持人 Thomas Germain 做了一个实验。他发布了一篇博客,标题是「最擅长吃热狗的科技记者」,描述了一个完全虚构的南达科他州国际热狗吃赛,声称自己获得了第一名。

一天后,他在 Google 搜索「最会吃热狗的科技记者」。Google 的 AI Overview 将他列为第一名,并引用了他在那个虚构比赛中的「成绩」。Germain 说:「它把我网站上的东西当成真理一样吐出来。」
Google 的发言人 Ned Adriance 回应称,大多数这类例子是「不现实的搜索,人们实际上不会这样搜」。但问题不在于人们会不会搜「最擅长吃热狗的记者」,而在于这个机制在任何搜索中都在运作——包括医疗建议、急救信息、法律问题。
当搜索引擎变成答案引擎
Google 自己的测试也印证了这个问题。在 Google 对 Gemini 3 的内部评估中,模型单独运行时的错误率是 28%。Google 说,AI Overview 因为结合了搜索引擎的信息,比 Gemini 单独运行更准确。这也不算错,但「比通用的 AI 更准确」和「足够准确」之间,还有很长的距离。

核心矛盾在于,过去的 Google 搜索是一个「目录」,它告诉你哪里有信息,你自己去判断,费时间但自己看过什么自己心知肚明。现在的 Google 搜索要做一个「答案机器」,直接告诉你答案是什么,而且放在最显眼的位,但这个「答案」的数据来源包括 Facebook 帖子和旅游博客,有超过一半的正确回答无法被验证,而且任何人只要写一篇博客就能操纵它的输出。
Google(包括大部分的 AI 产品)都在每一条 AI Overview 下方加了一行小字:「AI 可能会犯错,请双重检查。」
但当你把一个答案放在搜索结果的最顶部,用最权威的排版呈现,然后在底部用小字说「别全信」,这不像是负责任的设计,更像是免责声明。

真正的问题不在于 9%的错误率本身。任何信息系统都有错误率,传统搜索结果里也有大量垃圾网站和误导性内容。真正的问题在于一个设计决策:Google 把一个不确定的回答包装成了确定的样子。
过去,搜索引擎给你十个链接,你知道自己需要判断。
现在,搜索引擎给你一个答案,放在最上面,用最干净的排版,语气肯定而完整。它看起来不像「这里有一些信息供你参考」,而是「这就是答案」。而人类对「看起来像答案的东西」的默认反应是信任,不是质疑。
Okahu 的 CEO Pratik Verma 的建议是:「永远不要信任单一来源,总是拿另一个来源对比。」这是好建议,但它默认用户有能力和意愿去做交叉验证。而 AI Overview 的整个设计逻辑恰恰相反:它要的就是让你不用再点进去看。
它把答案递到你面前,然后建议是,别信。
