
4月22日报道,上周冲上OpenRouter热榜(Trending)第一的匿名测试模型Elephant Alpha今早正式揭晓真身——蚂蚁旗下的百灵模型Ling-2.6-flash。
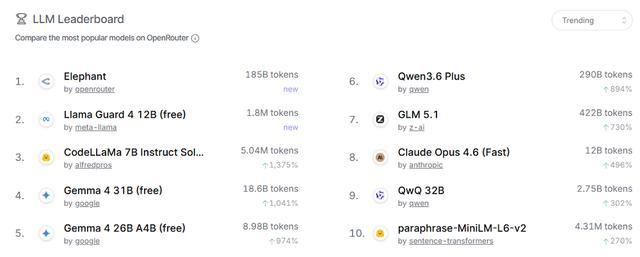
匿名上线以来,该模型调用量持续增长,连续多日位列热榜榜首,日均tokens调用量达100B级别。不少网友试用后表示印象深刻,有人称这是“用过最快的模型”“token效率很高”。
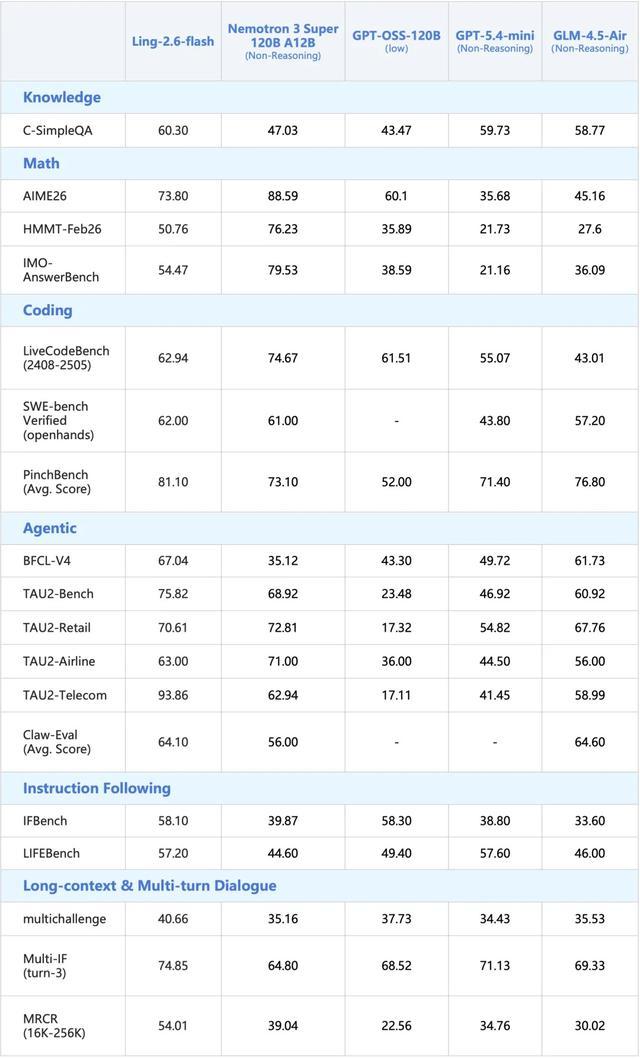
蚂蚁今日宣布正式推出Ling-2.6-flash。该模型总参数量104B,激活参数7.4B,为Instruct模型。如下图所示,该模型在Agent相关基准上达到同尺寸SOTA水平,并在其他核心能力上表现出色。
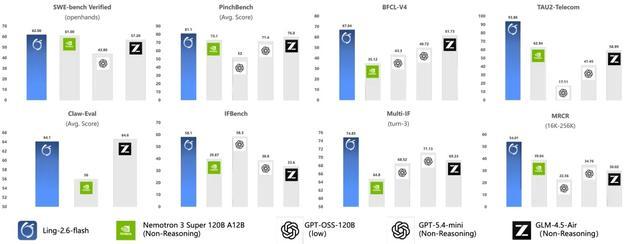
Ling-2.6-flash追求的是在控制token消耗的前提下,保持对Agent任务的强竞争力,主要具备以下三大核心能力:
1、混合线性架构,释放推理效率:通过引入混合线性架构,模型从底层优化计算效率。在4卡H20条件下,推理速度最快可达340 tokens/s,Prefill吞吐达到Nemotron-3-Super的2.2倍。
2、token效率优化,提升智效比:训练过程中对token效率进行针对性校准,力求以更精简输出完成目标。在Artificial Analysis完整评测中,Ling-2.6-flash仅消耗15M tokens,约为Nemotron-3-Super等模型的1/10。
3、面向Agent场景定向增强:针对工具调用、多步规划与任务执行能力持续打磨。在BFCL-V4、TAU2-bench、SWE-bench Verified、Claw-Eval、PinchBench等评测中,即使面对激活参数更大的模型,依然取得相近甚至SOTA级别的表现。
从智东西上周对该模型的实测来看,其在执行速度、指令响应、前端原型开发与长文件处理上表现高效,Agent规划与工具调用能力较强,但在项目级应用开发上仍有局限。总体而言,这是一款在轻量级、高频任务中具有优势的高效模型。

智东西用该模型接入类OpenClaw产品生成泰国7日游攻略网站
Ling-2.6-flash将在OpenRouter与官方平台同步提供一周免费API调用。
官方免费期结束后,平台仍将提供每日50万tokens免费额度;超出部分按量计费:输入0.6元/百万tokens,输出1.8元/百万tokens。模型的BF16、FP8、INT4等版本也将于近期开源。
一、实测:秒级响应、指哪打哪,几十分钟产出百万字长篇
智东西在体验中首先尝试了一些编程小项目,发现其响应速度和Agent工具调用能力较强。
首先是一个网站,这主要考察模型的前端能力。拿到开发任务后,该模型对网站的几个核心组件进行了规划,并主动为这一网站加入了明暗模式切换、移动端响应式设计等我们并未要求的功能,最终耗时1分钟左右完成开发。
当我们要求它将网站的主色调改成绿色后,该模型用不到10秒钟就完成了修改,其他大部分模型在处理修改任务时往往需要通读上下文,逐一修改,花上几分钟。
而它基本做到了指哪儿打哪儿,这对于一些快速、高频的网站调试需求是很实用的。
我们也试了试它有没有打造项目级任务的能力,让它根据自己的内部知识,复刻一个支付软件。我们是在Kilo Code插件中体验的模型编程,由该模型驱动的多个子Agent并行工作,进一步放大了它的输出速度优势,但是其最终打造的结果仅能算是一个原型。这种表现可能与其较小的参数量有关。
(更多体验案例移步→《匿名模型“大象”搅局OpenRouter:100B参数冲到热榜第一,实测结果如何》)
蚂蚁官方也公布了一些Ling-2.6-flash的实战演示:
在代码场景,以网页生成为例,Ling-2.6-flash兼具高审美表达与高速代码生成能力,能准确调用前端组件与图标库,适合单页面演示和原型制作中的快速验证。
其INT4量化版本可在DGX Spark上运行,下面视频为基于Ling-2.6-flash&DGX Spark 构建业界SOTA Hermes一体机教程。
Ling-2.6-flash结合Kilo Code可将视觉指令快速转化为高质量界面,胜任个性化视觉风格生成、报刊级排版及周刊、报告等办公内容的即时生成。
在文本场景,Ling-2.6-flash仅凭Prompt即可胜任多步骤文本任务执行,在指令遵循、文风调整与实时生成方面表现突出。
在Agent工具调用场景,该模型具备强大的上下文检索、工具调用与高速响应能力,适合复杂信息处理与知识增强场景。
基于Ling-2.6-flash,长篇写作助手autonovel可覆盖世界观设定、角色构建、大纲生成到正文创作的全流程,以200+ tokens/s的生成速度,仅需几十分钟即可产出百万字长稿。
在需求整理和排期等真实工作场景中,Ling-2.6-flash能稳定参与信息检索、任务拆解、内容处理与工具协同,具备较低的幻觉率与较高的结果可用性。
二、架构升级:推理吞吐最高提升4倍
Ling-2.6-flash延用了Ling 2.5的模型架构设计:在Ling 2.0架构基础上引入混合线性注意力机制,通过增量训练将GQA注意力机制升级为1:7的MLA+Lightning Linear高效混合架构。
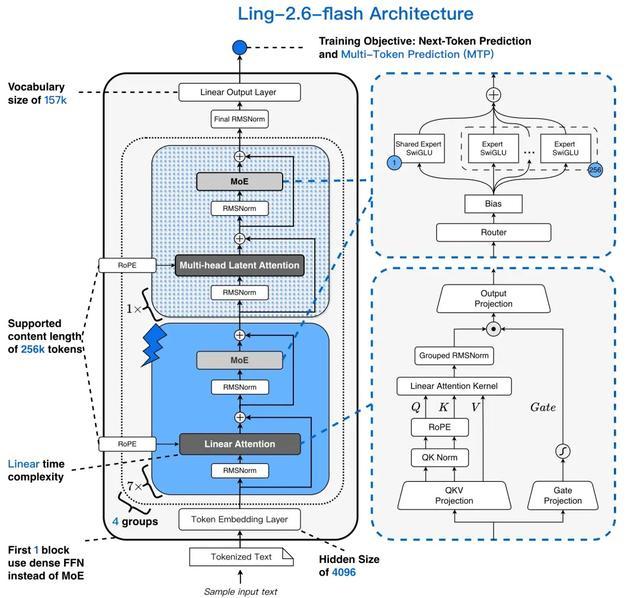
得益于混合注意力机制与高度稀疏化的MoE架构,Ling-2.6-flash在推理效率上优势显著。与同尺寸级别的主流SOTA模型相比,首字响应更快,长输出场景下的生成效率更高,Prefill吞吐与Decode吞吐最高均可达到约4倍提升。随着上下文长度和生成长度增加,吞吐优势进一步放大。
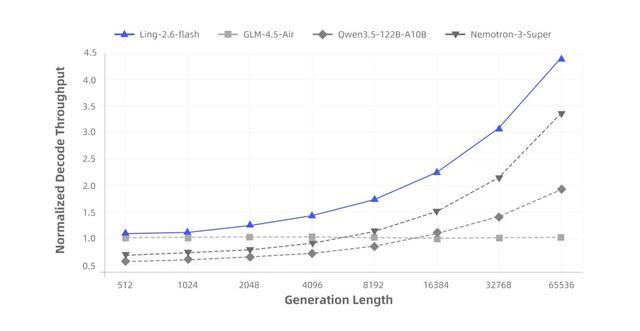
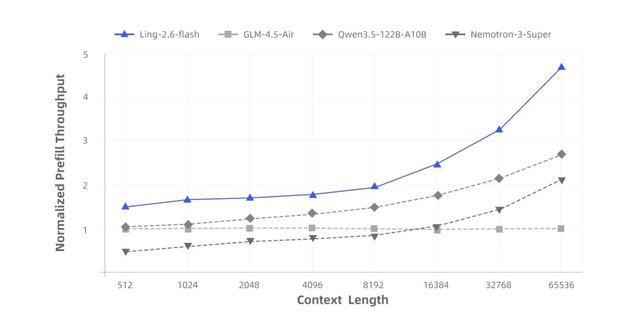
在预训练阶段,团队通过大规模算子融合提升训练效率;推理侧则围绕真实部署场景深度适配,使融合算子在融合粒度、实现路径与数值行为上尽可能与训练侧保持一致。相关推理算子将随linghe陆续开源。
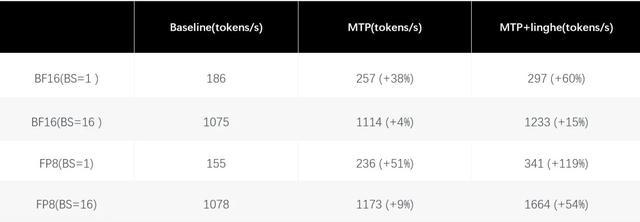
针对不同精度场景,推理链路进行了系统性优化:
BF16推理:实现QK Norm+RoPE、Group RMSNorm+Sigmoid Gate等关键算子深度融合,MoE Router GEMM与LM Head GEMM采用BF16 Input+FP32 Output计算方式。
FP8推理:进一步融合RMSNorm、SwiGLU与量化算子,针对小Batch Size引入Split-K的Blockwise FP8 GEMM,以此带来更高的系统吞吐、单用户TPS、更短的等待时间,以及在真实交互场景下更稳定、更流畅的使用体验。
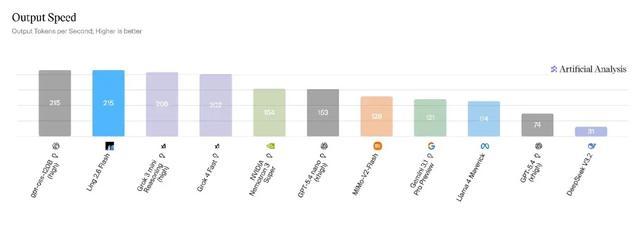
在Artificial Analysis榜单的Output Speed维度测评中,Ling-2.6-flash以215 tokens/s的输出速度处于第一梯队。
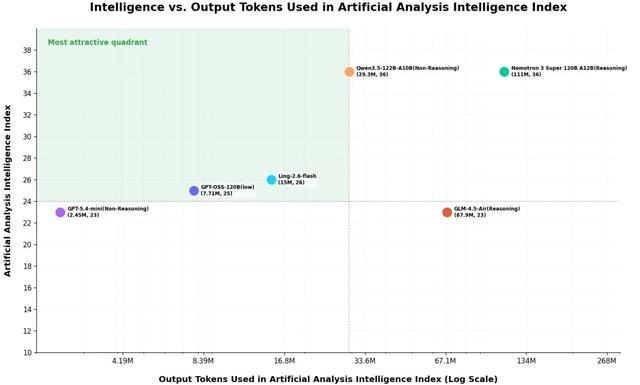
三、更优性能,token消耗仅为同行十分之一
在Artificial Analysis的Intelligence vs. Output tokens对比中,Ling-2.6-flash展现了突出的token效率优势:以15M output tokens实现了26分的Intelligence Index,在保持较强智能水平的同时将输出消耗控制在相对更低的位置。相比部分依赖更长输出换取更高分数的模型,它在“智能表现”与“输出成本”之间取得了更优平衡。
对于开发者和企业场景而言,这种能力带来的价值可能是更低的推理开销、更快的首字响应、更短的整体生成时延,以及更流畅的交互体验。
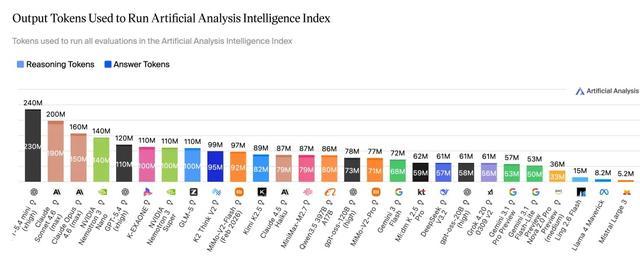
基于AA榜单的官方测评分数绘制
从token消耗看,在 Artificial Analysis Intelligence Index 的完整评测中,Ling-2.6-flash的总消耗仅为15M tokens,而Nemotron-3-Super等模型达到或超过110M tokens——仅用约1/10的token消耗完成同类评测任务,智效比更高。
四、强化学习特训:Agent能力对标SOTA
为增强模型Agent能力,团队显著扩展了Ling-2.6-flash训练数据的难度与广度,依托自研的大规模高保真交互环境,进行了针对性的General Agent与Coding Agent强化学习(RL)训练。
模型在指令遵循、工具调用、多步规划及长程执行方面表现提升显著,在BFCL-V4、TAU2-bench、SWE-bench Verified、PinchBench等榜单上表现优异。通过RL优化泛化性与稳定性,在Claude Code、Kilo Code、Qwen Code、Hermes Agent、OpenClaw等框架中均展现了良好的使用体验。
此外,Ling-2.6-flash在通用知识、数学推理、指令遵循及长文本解析等维度保持优秀水准,各项指标对齐同尺寸SOTA模型。
结语:部分高复杂度场景受限,将继续探索智效比边界
经过一周的持续迭代和优化,Ling-2.6-flash在Agent场景的泛化性和稳定性方面获得进一步提升。
Ling-2.6-flash在工具调用、多步规划与长程任务执行等关键维度上实现了明显提升。但百灵团队坦言,部分高复杂度场景中,受限于推理深度,模型仍可能出现一定的工具幻觉;此外,在中英双语自然切换、复杂指令遵循等方面仍有优化空间。
该模型后续迭代将继续探索智效比的更优边界,在保持高效推理特性的同时,进一步推动智能产出质量与token效率之间的深度平衡。
