作者|江宇
编辑|漠影
一套“24小时运转”的龙虾团队,在上线第4天,差点被主人亲手“团灭”。
智东西3月10日报道,海外知名AI科技博主、前谷歌产品经理Shubham Saboo近日在社交平台公开复盘了自己连续运行30天的AI Agent系统。
在他的设想中,这支“龙虾团队”应该像一个自动运转的小型内容工作室:有人负责研究行业信息,有人负责写内容,还有人负责发布和运营账号,整个流程全天候自动运行。但现实很快给了他一记闷棍。
最初几天,这套系统几乎可以用“灾难”来形容:负责写内容的Agent写出来的推文又长又空,读起来像模板拼接;负责搜集信息的Agent一天抓回47条所谓的“行业线索”,其中40条都是没用的假消息。
Saboo后来回忆,那几天他几乎一直在给Agent“擦屁股”。他花在修改Agent输出上的时间,甚至比自己手动把这些事情做完还多。上线第4天,他差点直接把整套系统关掉。
但事情在几周后开始出现转折。同样的模型、同样的提示词,第4周时,这些Agent生成的内容已经可以直接拿来用,大多数草稿只需要改两三个词就能发布。原本需要他反复返工的任务,开始自动跑通。
在这份复盘里,他回答了一个问题:为什么那么多人“养虾”时,第一周就速速放弃,而有些人却能把龙虾变成同事,效率倍增。
一、第1周几乎是“负收益”:改Agent比自己干活还累
Saboo最早上线的Agent是运营Agent——“Kelly”,负责运营他的X账号。第一天只是搭建环境,第二天开始生成推文,但结果并不理想。
Kelly写出来的内容既冗长又套路化,经常使用列表和箭头符号,开头是“我很高兴宣布……”,结尾再配上一串标签,整体风格不是作者平时的表达方式。
Saboo回忆,在第一周里,他几乎每天都在修改这些内容,花在修正Agent输出上的时间,比自己直接写一条推文还多。原本期待AI带来效率提升,现实却是不断修补错误输出,同时还要维护系统本身。
后来复盘这段经历时,他把这个过程称为 “纠错式Prompt工程(Corrective Prompt Engineering)”。与其一开始就设计完美提示词,不如先在SOUL.md(Agent行为设定文件) 中写一个粗略设定,然后通过持续反馈不断修正,就像管理新员工一样。第一版通常很普通,第十版开始能用,第三十版才会真正稳定。
Saboo坦言,在第一周结束前,他一度差点把整个系统关掉。
二、把具体反馈写进文件,而不是停留在聊天里
Saboo发现,Agent真正变好的关键在于具体规则的积累。在“运营Agent”Kelly第一次生成推文后,他把一组明确规则写入Agent的记忆文件。
这个记忆文件后来逐渐形成两个部分:一个叫“BAD”,记录所有被否定的写作模式,比如使用bullet points(项目符号列表)、箭头格式或领英帖子的语气;另一个叫“GOOD”,里面放的是作者过去表现最好的推文,让Agent在每次写作时进行模仿。
随着这些规则不断累积,Kelly的表现逐渐改善。第10天时emoji基本消失,第15天开始模仿作者的句式结构,到第20天时,大部分草稿只需要改一两个词就能发布。
Saboo认为,很多人使用Agent时会忽略一个关键环节:反馈必须写入文件,而不是停留在聊天记录里。如果反馈只存在对话记录中,下一次任务Agent就会再次犯同样的错误。只有当这些经验被写入可持续加载的文件,系统才会真正进化。
三、一次错误,让研究Agent学会判断“信号”和“噪音”
Saboo的第二个Agent是研究Agent——“Dwight”,负责每天扫描AI行业信息,为内容团队寻找选题线索。第一次扫描时,Dwight推送了47条信息,其中40条都属于噪音:包括各种小更新、未经验证的传闻,以及几乎没有价值的项目。
于是Saboo给了它一个非常严格的规则:如果读者Alex今天无法据此做任何事情,就不要推送。Alex是Saboo设定的目标读者画像:一位AI产品开发者。
这个规则很快改变了Agent的行为。第10天时,Dwight每天只推送18条信息,而且大多有价值;到第25天时,数量减少到7条,但每一条都值得阅读。
此外,一次错误也让系统进一步优化。Dwight曾把一个工具当成“新发布项目”推荐给Saboo,后来才发现,这个工具早已存在,只是当天有人在X上提到它。Dwight误把“被讨论”当成“刚发布”。
Saboo随后调整流程,要求Agent在推荐项目之前必须验证发布时间,例如检查GitHub仓库创建日期、Hacker News发布时间以及实际发布记录。如果项目已经存在一周以上且没有明显更新,就直接跳过。
他还彻底移除了GitHub趋势榜作为信息源,因为那里噪音太多,很多项目只是被重新讨论而已。取而代之的是goodailist.com(专门筛选新AI项目的网站)。
四、Agent团队也会“发胖”:上下文太多反而拖慢系统
随着系统不断积累经验,一个新的问题出现了:上下文膨胀。
Kelly的上下文一度达到161000个token,Dwight也超过156000个token。大量历史记录占据了模型的上下文空间,导致响应变慢,输出质量也开始下降。
Saboo最终对两个Agent进行了“压缩”:Kelly的上下文从161K减少到40K,Dwight从156K减少到43K。做法很简单,只保留当前真正有用的规则和记忆,其余内容全部归档。
他后来把这件事变成固定流程,每两周检查一次Agent记忆文件。Saboo形容,这个过程就像软件项目里的代码重构,如果长期不清理,系统就会越来越臃肿。
同一时期,他还解决了另一个系统问题。
第三周时,定时任务调度器出现Bug:任务在队列中推进,但实际上并没有执行。Saboo几个小时后才发现问题,因为系统表面状态看起来一切正常。
于是他新增了一个“首席运营Agent”——Monica。Monica负责定期检查系统“heartbeat(任务心跳信号)”。如果某个任务超过26小时没有运行,她会自动触发重新执行。
五、每个Agent团队都会经历的三个阶段
根据自己的实践经验,Saboo认为大多数Agent团队都会经历三个阶段。
第一阶段是混乱期,通常发生在上线后的前一周。Agent输出内容普遍比较普通,修改成本甚至高于人工完成任务,很多人会在这一阶段放弃。
第二阶段是稳定期,大约在第8到第21天之间。随着反馈不断积累,明显错误逐渐消失,输出开始接近可用状态,只需要少量编辑。
第三阶段是复利期。当系统积累了足够多的规则和上下文后,Agent会逐渐理解用户的表达习惯和判断标准,新任务也能继承过去的经验,整体效率明显提升。
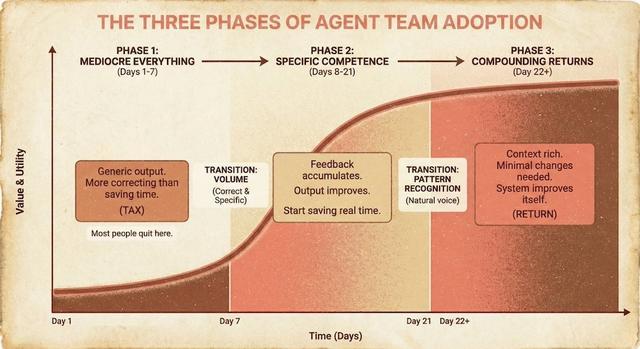
在他看来,能够坚持度过“混乱期”的人,最终得到的是一套会不断学习的自动化系统;而那些中途放弃的人,则每一次都要从零开始。
六、真正提升效率的是:两类文件和一个闭环
Saboo在复盘这30天时特别强调,真正会随着时间不断变好的,其实只有三样东西,其他部分基本都没有本质变化。
第一类是记忆文件。记忆文件存放的是Agent从反馈里学到的“偏好”,每一条反馈一旦写进记忆文件,就意味着这类错误以后不必再纠正一次。
第二类是技能文件。和记忆文件不同,技能文件记录的是从失败中提炼出来的“操作规则”。Saboo认为,技能文件更像是任务说明书,它告诉Agent这项工作到底该怎么做,而不仅仅是用户个人偏好是什么。也正因为更具指令性,技能文件往往比记忆文件积累得更快,效果也更直接。
第三类真正持续起作用的东西,是反馈闭环。Saboo认为,这是最容易被忽略的一环。很多人搭完Agent之后就让它自己运行,过几天发现效果没提升,便觉得系统没有用。但问题往往不在模型,而在于反馈没有真正进入系统。
比如“运营Agent”Kelly写完一条推文,如果Saboo只是当场说一句“太长了,把第一段删掉”,但这句反馈没有被写进文件,那么下一次Kelly还是会犯同样的错误。只有当这条反馈被记录进记忆文件或技能文件,并在下一次任务开始时重新加载,Agent才会真正“记住”这件事。
Saboo自己后来形成了一套固定动作:先给反馈,再由Agent更新记忆文件或技能文件,下一轮任务开始时把这条经验重新加载进去。整个流程并不复杂,但前提是执行上必须足够严格。
在他看来,模型在第1天和第30天其实没有变化,不会越用越“聪明”。真正发生变化的,是围绕模型构建的系统——包括规则文件、记忆记录以及持续反馈形成的工作流程。
七、他踩过的坑,也正是多数人会放弃的地方
回头看这30天,Saboo也总结了几个自己最典型的失误。
第一个问题是Agent上得太快、太多了。
他在两周之内一口气搭了6个Agent,结果很快发现:单个Agent本身都还没有进入稳定状态,多个Agent之间的衔接自然更容易混乱。更合理的方式应该是先把一个Agent做到稳定可用状态,再去加第二个。
第二个问题是文件结构一开始就设计错了。
最初两周里,他把所有内容都塞进同一个文件:偏好、规则、经验、教训混在一起。结果就是,Agent加载到的上下文经常互相打架。比如第一周形成的是一种表达偏好,第二周又写入了一条更明确的规则,二者之间可能彼此冲突,最终反而让Agent理解混乱。
Saboo后来才把记忆文件和技能文件彻底拆开,并给自己定了一条更明确的要求:当上下文达到15万token以上时,就必须强力压缩,不能再拖。
第三个问题是反馈给得太模糊。
Saboo认为,“把这个改好一点”这种话几乎不会留下任何有效积累,因为它无法写成一条规则,也无法指导下一次任务。真正有用的反馈,必须具体到足以直接写进文件。可靠的反馈不仅能解释为什么有问题,也能直接告诉Agent下次应该怎么改。换句话说,只有能被规则化的反馈,才有复利价值。
八、如果从零开始,前30天应该怎么跑
在文章最后,Saboo也给出了一套更适合新手照着执行的30天方案。
第一周,最重要的不是追求复杂系统,而是只挑一个自己每天最重复、最机械的任务。
围绕这个任务搭建一个Agent,写好SOUL.md,设置一条简单的定时任务,让它先跑起来。Saboo提醒,这一周产出的内容大概率会很普通,甚至很糟糕,这本来就是正常现象。第一周唯一的任务是把所有错误都具体地纠正出来,不是简单说“这个不行”,而是明确告诉它:“这条不行,是因为X;下次请按Y来做。”
第二周,要开始检查这些经验到底有没有真正留下来。
Saboo建议,可以让同一个Agent跑两次相似任务,然后观察它是否还会犯同样的错误。如果同样的问题再次出现,就说明反馈闭环没有成型,也就是经验没有真正进入可持续存储的文件。这一阶段,用户应该开始建立自己的技能文件,把那些反复重复的规则正式写下来。
第三周,如果前两周执行得比较扎实,Agent通常会逐渐进入第二阶段,也就是“内容需要编辑,但不需要重写”。这个阶段可以开始记录一个更实际的指标:每次审稿到底花了多久。
Saboo认为,这个数字应该是一周比一周下降的。如果没有下降,通常不是模型不行,而是反馈仍然不够具体。
到了第四周,才适合考虑引入第二个Agent,而且前提是第一个Agent已经能够稳定产出有用结果。
Saboo建议,这时两个Agent之间的配合也不要设计得太复杂,最简单的方式就是基于文件协作:第一个Agent把产出写进共享文件,第二个Agent去读取这个文件再继续处理。集成方式越简单,系统越不容易失控。
