
编译 | 陈骏达
编辑 | 云鹏
让AI翻译OG、砍一刀等新词、网梗,会是什么画面?
DeepSeek给出的答案是这样的:

不仅略显生硬,还有点惊悚,很可能让外国友人误解:“砍一刀”难道是一种针对外国人的暴力活动吗?
智东西9月1日报道,今天,腾讯混元开源其首批翻译模型:Hunyuan-MT-7B和Hunyuan-MT-Chimera-7B,给机器翻译提供了一个新选项。这一模型可对33个语种进行互译,并处理粤语、维吾尔语、藏语、哈萨克语、蒙古语等少数民族语言或方言。
这一模型还能精准理解网络用语、游戏用语等,结合语境进行意译。对于“砍一刀”,Hunyuan-MT-7B给出了如下翻译。虽然有点丧失了“砍一刀”的神韵,但准确传达了大义,至少不会让外国读者感到惊悚了。
在多个具有代表性的机器翻译基准测试中,Hunyuan-MT系列模型的表现超越谷歌翻译等专用翻译系统和Seed-X-PPO-7B、Tower-Plus-9B等同尺寸翻译模型,还打败了参数数十倍于它的DeepSeek-V3等模型,在翻译场景的表现接近Claude-Sonnet-4。
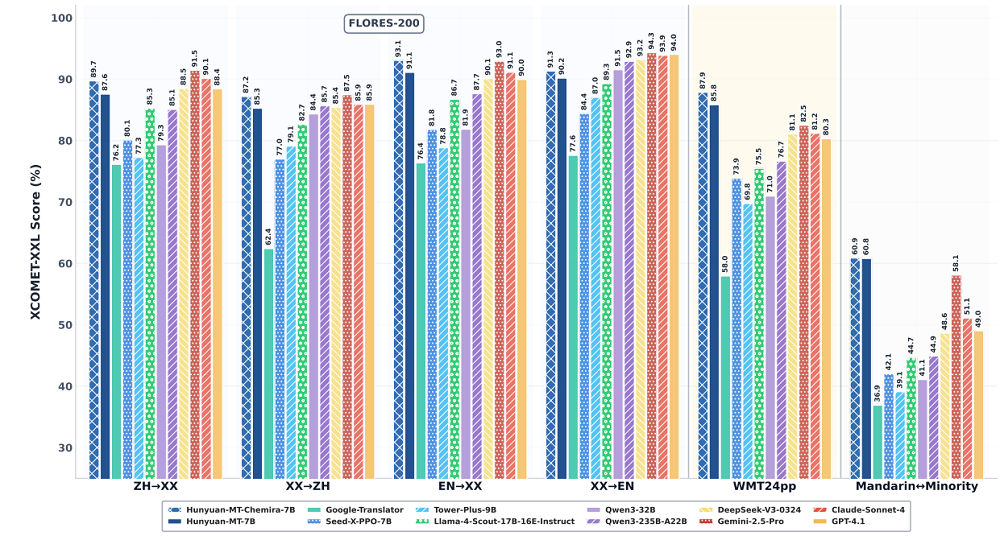
面向国内用户,Hunyuan-MT重点优化了中文与多种少数民族语言之间的双向翻译,采用了针对性的数据整理和优化措施,显著提升了模型在资源匮乏环境下的翻译效果。
在ACL(国际计算语言学协会)主办的WMT 2025(世界机器翻译大会)通用机器翻译任务中,Hunyuan-MT-7B在31对语言组合的互译中,获得了30项第一。
值得注意的是,这些语言组合既包括中文、英语和日语等资源丰富的语言,也包括捷克语、马拉地语、爱沙尼亚语和冰岛语等资源匮乏的语言。
腾讯混元还打造了翻译集成模型Hunyuan-MT-Chimera-7B。这一模型使用了“弱到强”强化学习方法,在推理阶段能够整合来自不同系统的多条候选译文,生成质量超越单一候选译文的最终输出。
腾讯混元已将Hunyuan-MT-7B和Hunyuan-MT-Chimera-7B上传至开源托管平台Hugging Face和GitHub,并基于腾讯自研的AngelSlim大模型压缩工具对Hunyuan-MT-7B进行FP8量化压缩,推理性能进一步提升30%。7B的模型尺寸,在不少消费级GPU都能实现流畅运行。
Hunyuan-MT-7B已经在腾讯混元AI Studio中上线,开发者可在这一平台体验模型,并通过API接口调用模型,但Hunyuan-MT-Chimera-7B尚未上线。
智东西第一时间对Hunyuan-MT-7B模型的能力进行了体验,并梳理了技术报告中有关这一系列模型的更多细节。
体验地址:https://hunyuan.tencent.com/modelSquare/home/list
Github: https://github.com/Tencent-Hunyuan/Hunyuan-MT/
HugginFace: https://huggingface.co/collections/tencent/hunyuan-mt-68b42f76d473f82798882597
AngelSlim压缩工具:https://github.com/Tencent/AngelSlim
一、精准翻译游戏名、网络梗,但在专业翻译考试题上翻车了
在技术报告内的多个翻译案例中,Hunyuan-MT系列模型展现出较强的理解力。
Hunyuan-MT-7B能正确将“小红薯”理解为社交平台“REDnote”,并将“砍一刀”理解为拼多多的降价机制。而谷歌翻译仅能直译,并给出错误的译文(分别为“sweet potatoes”和“cuts”)。

对于英文俚语表达,Hunyuan-MT-7B能准确捕捉惯用意义,例如将“You are killing me”翻译为表达“好笑、逗趣”的含义,而非字面上的“你要杀我”;谷歌翻译则未能准确处理。

智东西的实测也验证了Hunyuan-MT-7B的这一能力。在翻译“He’s killing it”时,模型不会直接翻译原文,而是理解了这是一个口语化的表达,并翻译为“他表现得非常出色”。

此外,该模型在专业术语翻译上也表现出更强能力,能够正确翻译医学术语,如“blood disorders”和“uric acid kidney stones”,还能成功实现跨语言的完整地址翻译,而谷歌翻译往往保持原文不变。

这些例子表明,Hunyuan-MT-7B在语言细微差别、文化背景和领域知识上具有更深刻的理解,从而能够生成比传统翻译系统更准确、更自然的译文。
对于欧洲语言(意大利语、德语)和亚洲语言(韩语、波斯语),Hunyuan-MT-7B能够生成更准确、自然的译文,正确理解上下文特定术语,避免直译错误。
在少数民族语言(如哈萨克语、藏语等)的翻译中,Hunyuan-MT-7B能够准确翻译完整句子,而谷歌翻译往往输出无意义的内容(例如哈萨克语)。
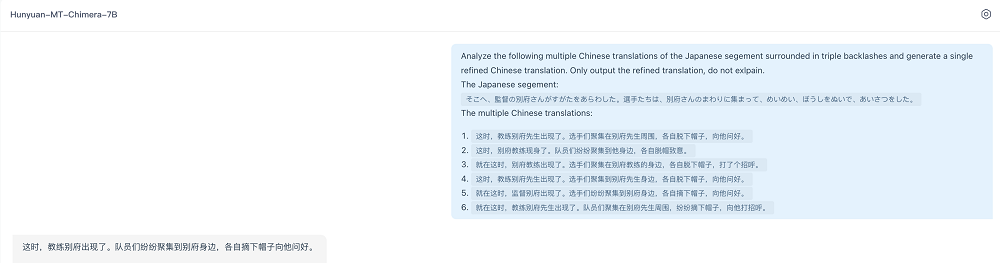
Hunyuan-MT-Chimera-7B能在游戏等场景,利用其增强模块提升对上下文、口语表达及领域术语的理解,使译文更加准确自然。
例如,其他模型未能将缩写“d2”识别为游戏《暗黑破坏神 II》,或将“make a game”错误理解为游戏开发,而Hunyuan-MT-Chimera-7B正确识别了游戏语境及交易术语。

在处理非正式语言时,它能够恰当地翻译用于强调的脏话,而非直译为粗俗用语,显示出更好的语用理解。

此外,它还展现了更强的上下文感知能力,将“穿过”翻译为“sped through”,而非含义不当的“drove through”(暗示冲入人群)。

这些案例表明,Chimera增强模块能够提升对上下文、口语表达及领域术语的理解,使译文更加准确自然。
智东西让Hunyuan-MT-7B翻译了两道2025年全国翻译专业资格(水平)考试(CATTI)真题,这一考试侧重对时政、热点的考察。
在英译中任务上,Hunyuan-MT-7B准确地处理了专有名词、术语的翻译,但是在句式选择上仍然受到英文原文的影响,读起来并不顺畅,只能说达到了入门级译者的水平。
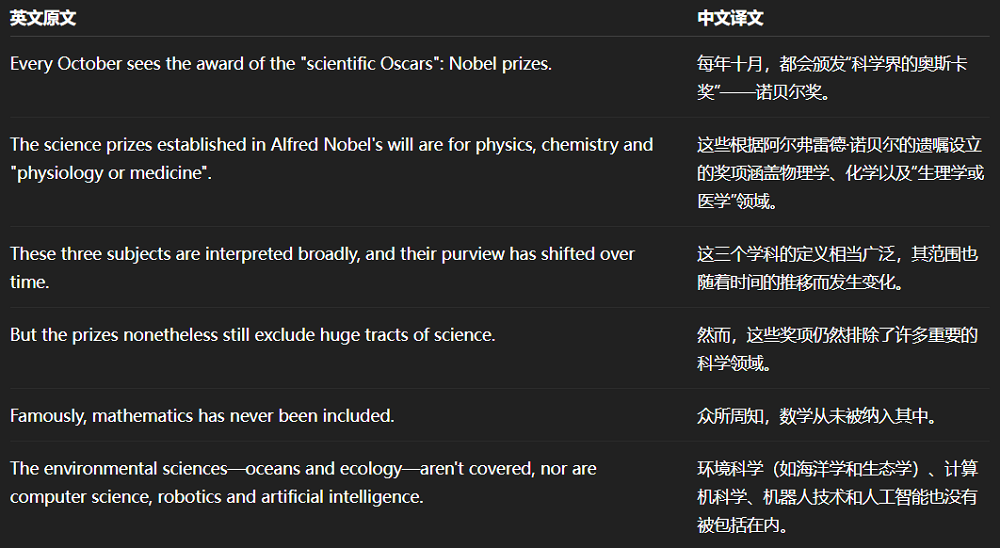
在处理中译英任务时,Hunyuan-MT-7B对关键词的翻译基本准确,但是将最重要的会议名称翻错了,会议全名中有一个单词出错,还将“消博会”的缩写写成了“进博会”的缩写CIIE,属于较为严重的错误。这可能是因为模型参数量较小,对此类表达积累不足。

二、预训练数据包含上百种语言,Base模型已成为同量级SOTA
为什么要打造Hunyuan-MT?腾讯混元在技术报告中分享了当前机器翻译模型存在的几大问题。
虽然如今的大模型已经能在特定语言对上交付超越人类专家译者的疑问,但机器翻译系统和大模型在处理网络新词、俚语、专业术语以及地名等非书面语言时,翻译质量仍然有待提升。
同时,对低资源语言(缺乏相关语料的语言)和少数民族语言机器翻译的研究严重匮乏,而中国少数民族语言与普通话之间的翻译问题尤为突出。
要解决这些问题,不仅需要强大的语言理解能力,还必须能够生成在文化上契合、表达上地道的译文,从而超越逐词对应的直译。
为训练这一机器翻译模型,腾讯混元团队在通用预训练阶段联合训练了中文、英文以及小语种、少数民族语言的数据。
其中,非中文、英文的少数语种数据集规模达1.3万亿个token,涵盖来自多种来源的112种非中英文语言及方言。
这些数据并不会被一股脑地输入模型,而是通过多语种数据质量评估模型评估其知识价值、真实性与写作风格后,得到加权得分,并根据数据源的特征,动态调整质量评估的权重。例如,在图书类与专业网站内容中,腾讯混元团队会优先选择知识价值得分较高的文本。
同时,为了确保训练数据的多样性,腾讯混元团队还建立了三个数据标注体系,分别为学科标注体系、行业标注体系(24类)和主题标注体系(24类)。
这一体系可用于筛选和比例调节,例如平衡学科分布,确保跨行业的内容多样性,或是过滤广告内容等。
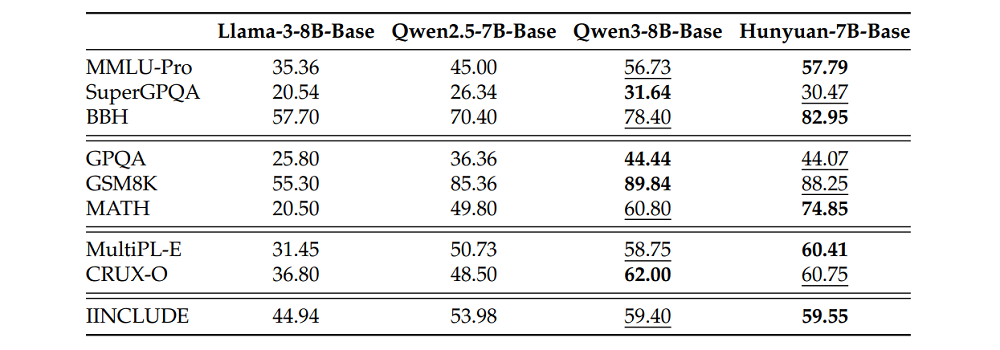
在采用上述数据训练后,腾讯混元团队得到了Hunyuan-7B-Base模型,这一模型在通用知识、推理、数学、科学知识、编程和多语言能力上均实现同尺寸模型中的较好表现,在9项基准测试中获得5个SOTA。
三、针对机器翻译“定向预训练”,翻译能力进一步提升
打造Hunyuan-7B-Base的环节被称为“通用预训练”,接下来,模型还需针对机器翻译任务进行“定向预训练”。
在这一阶段,腾讯混元团队使用了单语语料与双语语料的混合数据,这些数据主要来自于开源数据集和公开的平行语料库(收录双语对照数据的数据库)。之后,这些数据还经历了语言识别、去重、质量过滤等环节。
为确定合适的数据混合比例,该团队借鉴了RegMix方法,先在小规模模型上进行实验,拟合采样比例与训练损失之间的函数关系,再通过函数模拟,找到使预测损失最小的比例,并将该比例用于最终翻译模型的机器翻译定向预训练阶段。
为防止灾难性遗忘(模型学新忘旧),腾讯混元团队在训练中保留了20%的原始通用预训练语料。同时,他们还采用了先升温至初始预训练的峰值学习率,再逐步衰减至最小值学习率的调度策略。
为全面评估模型的多语种翻译能力,Hunyuan-7B★(★代表经过机器翻译定向预训练)在业界常用的翻译能力测评数据集FLORES-200、WMT24pp等和汉语-少数民族语言互译测试集上进行了测试。
结果显示,无论是在客观指标和多语种专家的主观测评中,这一模型的表现都超过了同尺寸模型,和机器翻译定向预训练前的Hunyuan-7B相比,也有明显提升。

四、采用三种后训练方法,能融合6种翻译结果
预训练之后,腾讯混元团队通过监督微调(SFT)、强化学习(RL)和“弱到强”强化学习(Weak-to-Strong RL),进一步提升模型翻译能力。
Hunyuan-7B-Base在SFT环节的第一阶段,使用了超过300万对平行语料,涵盖了公开数据集、人工翻译、DeepSeek-V3-0324生成的合成语料,以及精选的指令调优数据。
进入第二阶段,Hunyuan-7B-Base的优化重点是更高的精度。腾讯混元团队选取了约26.8万对更高保真的语料,经过更加严格的筛选与验证,部分样本由人工复核,保证了数据的可靠性。
借助这一双阶段的微调策略,模型的翻译表现实现提升,特别是在少数民族语言与汉语的互译任务中展现出明显优势。
RL阶段,Hunyuan-7B-Base采用了常见的GRPO算法,并设计了多元化的奖励函数。
这一奖励函数包括质量感知奖励、术语感知奖励和重复惩罚。
其中,质量感知奖励包含两个奖励信号,一个由客观机器翻译质量评估模型XComet-XXL提供,这一模型不像传统的BLEU评估模型一样依赖人工译文,而是直接分析翻译文本的流畅性、准确性和自然度等特征。
另一个奖励信号来自DeepSeek-V3-0324的评分。V3在这里扮演了类似人工翻译评审员的角色,并借用了GEMBA翻译质量评估框架里的提示词,让V3对翻译结果的语义准确性、语法正确性等进行评分。
能否对关键术语进行准确翻译,也会影响译文质量。腾讯混元团队引入基于词对齐的奖励机制,通过词对齐工具提取关键术语和信息,计算机器译文和参考译文的重合率,重合率高奖励就越大。
该团队观察到,模型在RL后期容易生成重复内容,甚至可能导致训练崩溃。因此,他们设计了重复检测机制,一旦发现重复模式则施加惩罚,以保持输出的多样性和训练的稳定性。
腾讯混元团队还提出了“弱到强”强化学习方法,模型会生成多个翻译结果,并利用基于Hunyuan-MT-7B的融合模型通过GRPO聚合这些输出。奖励函数由XComet-XXL评分、DeepSeek-V3-0324评分和重复惩罚项组成。这种奖励机制能够全面评估翻译质量,同时避免冗余输出。最终,Hunyuan-MT-7B-Chimera模型诞生了。
系统提示词显示,Hunyuan-MT-7B-Chimera会分析六个不同翻译结果,生成经过统一优化的最终翻译结果。

该方法利用多种翻译之间的互补性,从而显著提升翻译质量。
基准测试结果显示,Hunyuan-MT-7B和Hunyuan-MT-Chimera-7B在XCOMET-XXL和CometKiwi两项指标上均显著优于大多数基线模型,显示出稳定而显著的改进。
在谷歌等企业推出的WMT24pp基准上,Hunyuan-MT-7B的XCOMET-XXL得分为0.8585,超越了所有基线模型,包括Gemini-2.5-Pro和Claude-Sonnet-4等超大模型。
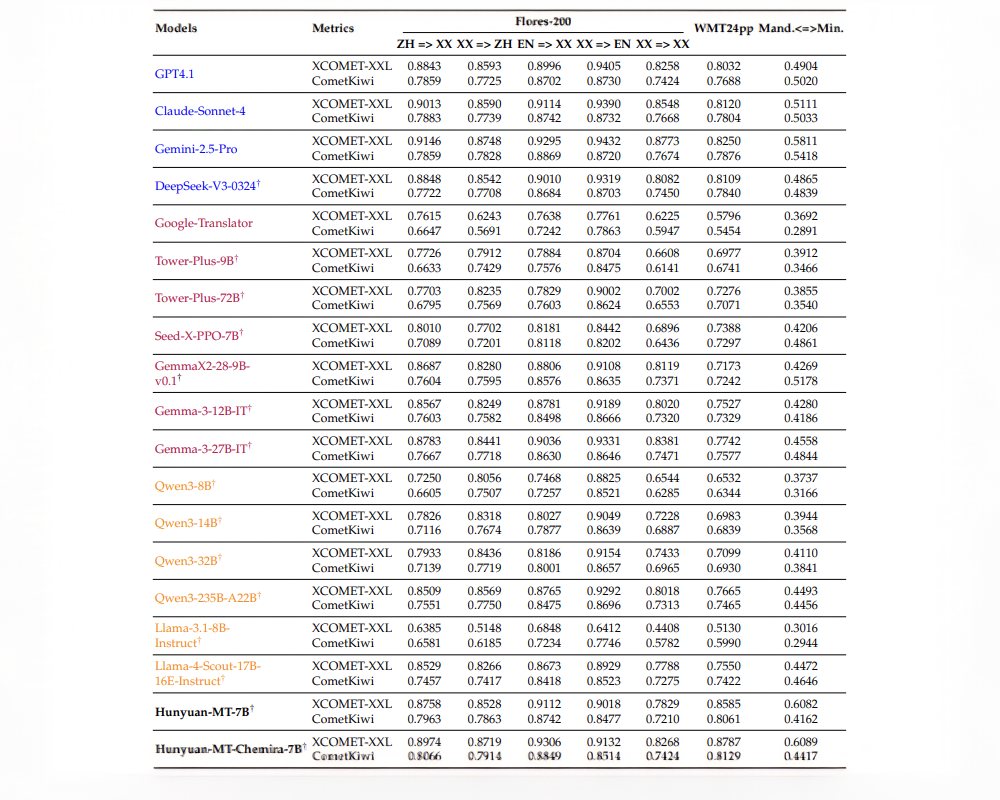
在汉语与少数民族语言的翻译任务中,Hunyuan-MT-7B(得分0.6082)和Hunyuan-MT-Chimera-7B(得分0.6089)高于所有竞品,其中最接近的Gemini-2.5-Pro为0.5811。
结语:生成式AI给机翻带来新解法,多家大厂已下注
对腾讯、字节、阿里等企业而言,机器翻译模型有其现实价值:在展开跨国业务的过程中,高质量的机器翻译模型可以替代或者加速部分人工翻译流程,实现降本增效。
在生成式AI时代,机器翻译这一计算语言学的经典话题又迎来了新的解决方案,有越来越多的厂商使用Transformer等新一代模型架构打造机器翻译模型。未来,我们或许能看到更为成熟、强大的翻译模型投入使用,
