2024年,imec推出了CMOS 2.0作为新的扩展范式,以应对应用多样化带来的日益增长的计算需求。在CMOS 2.0中,片上系统(SoC)在系统技术协同优化(STCO)的指导下被划分为不同的功能层(或层级)。每个功能层都采用与功能约束最匹配的技术选项构建。
先进的3D互连技术重新连接了SoC的异构层。这让人想起一项已经应用于商用计算产品的演进:想象一下在处理器上3D堆叠SRAM芯片。但CMOS 2.0方法的标志是,异构性被引入SoC内部。根据应用需求,CMOS 2.0甚至设想将SoC的逻辑部分拆分为高驱动逻辑层(针对带宽和性能进行了优化)和高密度逻辑层(针对逻辑密度和性能功耗比进行了优化)。高密度层可以采用最先进的技术制造,包括规模最大的晶体管架构。

图1:CMOS 2.0 时代 SoC 可能分区的示例。
另一个关键特性是背面供电网络 (BSPDN):部分有源器件由晶圆背面供电,而非传统的正面供电方案。这样,在晶圆层正面实现极高的后端制程 (BEOL) 间距图案化成为可能,且不受电源电压降的限制。
基本上,在这种方法中,我们修改了器件晶圆,使之成为非常薄的前端 (FEOL)有源器件层,一侧(原来的“正面”)是密集的后端 (BEOL)信号布线层堆栈,另一侧(原来的“背面”,但现在是新的正面)是电源和外部 I/O 连接。还可以堆叠多个这样的薄器件层,每侧都有密集的互连。每层可以集成不同类型的器件,例如逻辑器件、存储器、静电放电 (ESD) 保护器件、稳压电路……我们将这种密集的 3D 器件层堆叠称为 CMOS 2.0。
通过这种系统扩展方法,芯片设计和制造将摆脱通用CMOS技术平台。该平台已服务于半导体行业数十年,但难以充分满足日益增长和多样化的计算需求。这种方法有助于解决计算系统扩展瓶颈,为半导体生态系统中的每个参与者(包括系统公司和无晶圆厂公司)带来价值。
3D互连和背面技术:CMOS 2.0的基础
CMOS 2.0 依赖于过去所有的半导体创新,包括逻辑器件缩放、存储器密度缩放、先进光刻、3D 集成和 BSPDN 技术。但是,由于3D 互连和背面技术的最新突破,这一概念现在才能成为现实。例如,晶圆间混合键合开始提供亚微米互连间距连接。因此,它可以提供与 BEOL 最后金属层相匹配的互连密度——这是通过混合键合连接实现逻辑上逻辑或存储器上逻辑层堆叠的关键。随着直接访问晶体管端子,背面电源传输技术预计将发展到更细粒度的水平。尽管此功能最初针对电源连接,但它也为细粒度信号连接迁移到背面提供了可能性。这样,任何器件技术层都将悬浮在 2 个独立的互连堆栈之间。
细间距键合和细颗粒背面处理的结合(图 2)是实现图 1 所示的CMOS 2.0愿景的基础。
![图 2 – 高密度面对面混合键合连接和背面高密度连接网络示意图(2025 VLSI [4] 中展示)。(PADT = 顶部焊盘;PADB = 底部焊盘;TDV = 穿透电介质通孔。)](https://x0.ifengimg.com/res/2025/CE91ACA87B5268156676EE8F349CF87B1E8078B6_size36_w640_h476.jpg)
图 2 – 高密度面对面混合键合连接和背面高密度连接网络示意图(2025 VLSI [4] 中展示)。(PADT = 顶部焊盘;PADB = 底部焊盘;TDV = 穿透电介质通孔。)
在2025 VLSI大会上,imec报告了晶圆间混合键合和背面通孔两项3D集成技术的进展,这两项技术是实现CMOS 2.0的基础[4]。这些技术为围绕STCO指导下的CMOS 2.0愿景设计新的系统架构奠定了基础,而背面通孔网络(BSPDN)将在其中发挥核心作用。同样在2025 VLSI大会上,imec的研究人员强调了此类BSPDN可为先进系统架构带来的功率-性能-面积-成本(PPAC)优势[5]。
晶圆对晶圆混合键合迈向250nm间距:路线图视图
多年来,各种 3D 互连技术已得到发展,涵盖了广泛的互连间距,并可满足不同的应用需求。在所有这些技术中,晶圆间混合键合最适合提供CMOS 2.0 环境下存储器/逻辑上逻辑层堆叠所需的 3D 互连间距和密度。晶圆间键合的铜焊盘可提供从一层到另一层的短而直接的低电阻连接。在缩小的间距下,晶圆级连接可以在信号传输过程中提供高带宽密度并降低每比特功耗。
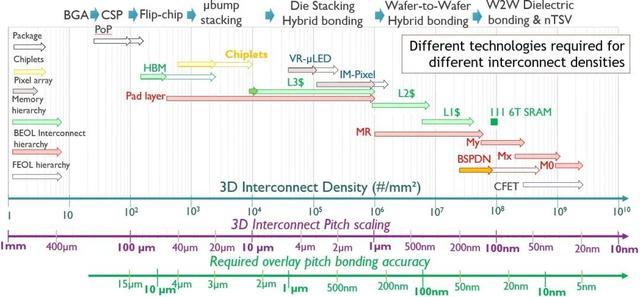
图 3 – Imec 的 3D 互连技术扩展路线图,展示了不同互连密度所需的不同技术。(BGA = 球栅阵列;CSP = 芯片级封装;W2W = 晶圆到晶圆;Mx、My 和 MR 代表 BEOL 互连层次结构)。
经典的晶圆到晶圆混合键合工艺流程
经典的混合键合工艺(图 4)从两片完全处理的 300 毫米晶圆开始,包括完整的前端工艺 (FEOL) 和 BEOL(另见图 2)。流程的第一部分类似于片上 BEOL 镶嵌工艺,在键合电介质中蚀刻出小腔体——主要使用 SiO2。腔体中填充阻挡金属、种子和铜。接下来是化学机械抛光 (CMP) 步骤,该步骤针对高晶圆间均匀性进行了优化,以产生极其平坦的电介质表面,同时为铜焊盘实现可控的几纳米凹陷。精确对准后,两片晶圆的实际键合在室温下通过使晶圆在晶圆中心接触而进行。抛光晶圆表面的粘附性导致晶圆间强大的吸引力,从而产生键合波,从中心到边缘闭合晶圆间间隙。完成此室温键合步骤后,晶圆在较高温度下退火,以获得永久的电介质-电介质键合和铜-铜键合。
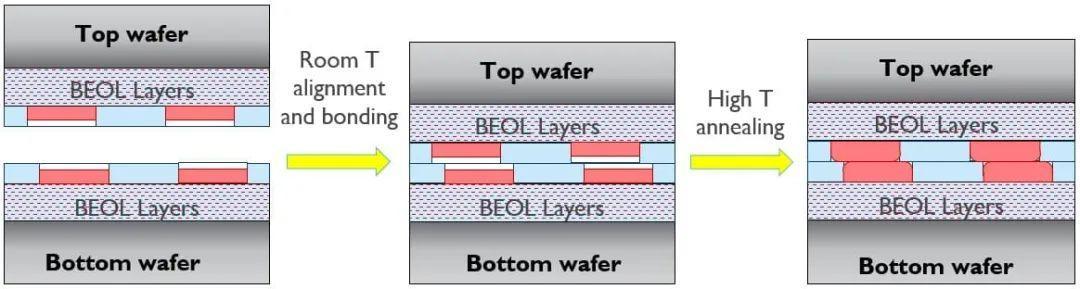
图 4 – 经典的晶圆到晶圆混合键合工艺流程
可靠的 400nm 间距晶圆间连接
在IEDM 2023上,imec 展示了可靠的 400nm 间距晶圆间连接,并实现了高良率,这比工业晶圆间键合工艺中使用的 1µm 间距连接有了显著提升 [6]。互连间距的这一飞跃得益于多项工艺流程的改进,包括增强对晶圆表面拓扑结构的控制以及使用SiCN 作为键合电介质。研究发现,SiCN 比传统的SiO2具有更优异的键合强度和可扩展性。
推动混合晶圆对晶圆键合路线图迈向200纳米间距
每当我们深入系统层级——最终将逻辑部分拆分为专用逻辑层——就需要低于 400nm 的键合间距,从而推动晶圆间混合键合路线图朝着 200nm 间距发展。但随着间距不断缩小,对两个铜焊盘之间键合覆盖层的要求也随之提高。通常,键合工艺的覆盖精度相当于间距的四分之一,对于 200nm 间距的键合工艺,覆盖层精度可小至 50nm。在 300mm 晶圆规模上实现如此高的精度是当今实现更高互连密度的最大挑战。
为了继续推进该路线图,imec 的研究人员致力于对键合工艺以及影响高套刻精度的因素进行更深入的理解。众所周知,在键合过程中,两个晶圆很容易变形和扭曲,从而阻碍铜焊盘之间的精确套刻。该团队通过模拟发现,两个晶圆粘合时产生的键合波传播并不均匀——这种现象被认为是晶圆变形的根本原因。这些发现有助于建立模型,让我们能够预测晶圆的变形程度,并最终调整键合工艺。
这些知识还可以通过另一种方式帮助提高套刻精度:设计人员可以在实际晶圆键合之前,根据图案设计调整铜焊盘的位置。这些键合前的光刻校正使imec能够使用当今最先进的键合机工具,实现间距为300纳米的晶圆间混合键合,且95%的芯片的套刻误差小于25纳米。
在 VLSI 2025大会上,Imec 的研究人员展示了将晶圆间混合键合路线图进一步扩展至前所未有的 250 纳米间距的可行性。然而,为了在 300 毫米晶圆上以行业相关的良率实现所需的套刻精度,需要下一代键合设备。Imec 将继续与其工具供应商生态系统合作,朝着这一宏伟目标迈进。

图 5 – 250nm 六边形焊盘网格上的菊花链(键合顶部(PADT)和底部(PADB)焊盘,尺寸不等)的 TEM
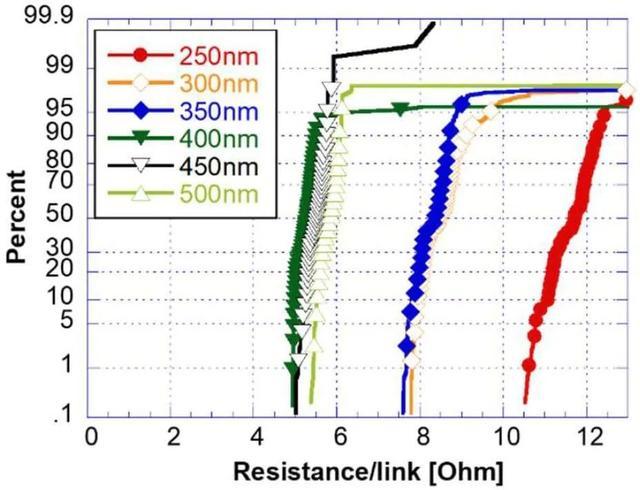
图 6 – 对于不等尺寸焊盘,混合键合菊花链的电气产量与焊盘间距的关系
利用纳米硅通孔连接层正面和背面的金属
在CMOS 2.0实现中,层级堆叠将比当今工业混合键合的情况复杂得多。堆叠的层级将不再是两层,而是多层。大多数层级的两侧(正面和背面)都将有金属线,中间则有一个有源层(例如存储器或逻辑电路)。部分背面金属线可用于为有源器件供电,作为更广泛的BSPDN的一部分。
通过直接背面接触和纳米硅通孔实现前后连接
秉承这一愿景,如今的层级结构在两侧均实现了连接,正面和背面金属以无缝方式相互连接。这种前后连接可以通过硅通孔 (TSV)实现,粒度可达逻辑或存储器标准单元级别。随着系统层级结构的深入,需要以更精细的互连间距实现其他前后连接,包括直接背面接触。这种连接方案可用于将先进逻辑器件的源极/漏极接触区域直接连接到背面金属,并且正在成为领先代工厂的逻辑路线图中的新兴技术。
正反面连接技术的发展必须跟上晶圆对晶圆混合键合路线图的进步,以便以平衡的方式在晶圆两侧提供紧密间距的连接(另见图2)。但结合所有这些技术也带来了挑战。晶圆对晶圆键合步骤后需要越来越多的后处理,包括晶圆减薄(以支持TSV的制造)和背面金属图案化。在后一步骤中,最大限度地减少背面光刻畸变对于确保背面金属线与TSV或源极/漏极触点之间的紧密覆盖至关重要。
底部直径为 20nm 的背面电介质通孔
在VLSI 2025 大会上,imec 展示了其纳米硅通孔 (nTSV) 路线图的进展,展示了直径小至 20 纳米、间距为 120 纳米的背面通孔。如此小直径的通孔具有尽可能少占用标准单元面积的优势,但其制造需要极度减薄晶圆,以确保可控的纵横比。

图 7 – 使用底部直径为 20nm 的无障碍 Mo 填充 TDV 进行正面到背面连接的 TEM
Imec 的路线图提供了多种制作 nTSV 的选项,包括先通孔、中通孔和后通孔集成。此外,通孔底部可以做成圆形或狭缝形,以牺牲面积为代价换取覆盖公差。在 2025 VLSI 演示中,通孔是采用先通孔方法制作的,这意味着在晶圆减薄之前,通孔已经在晶圆正面的浅沟槽隔离 (STI) 特征内图案化。由此产生的穿透电介质通孔(TDV,之所以这样称呼是因为这些通孔穿过 STI 电介质)用钼 (Mo) 填充。Mo 可以在没有阻挡层的情况下实现,并且比传统的 Cu 或 W 金属具有更小的电阻,从而有利于面积和性能。
以高套准精度连接正面和背面
典型测试结构的版图显示,55nm 宽的背面金属线与 20nm 宽的 Mo TDV 圆形底部之间的叠对边距为 15nm 。此叠对规格可通过在背面金属光刻步骤中每次曝光时使用高阶校正来实现,以补偿先前晶圆键合和减薄步骤造成的网格畸变。
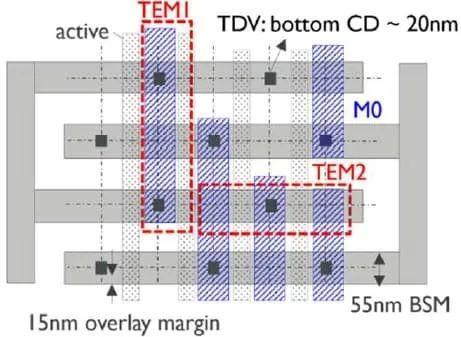
图 8 – 版图显示,TDV 底部与 55nm 宽背面金属之间有 15nm 的叠对余量。(TEM1 代表图 7 中使用的 TEM 切口。)
在所有之前讨论的连接方案中,实现混合键合中的高总覆盖精度以及最大限度地减少背面光刻畸变都是关键目标,这既依赖于键合工艺,也依赖于下一代键合设备的功能。
BSPDN 在始终在线和交换域设计中的性能和面积优势
BSPDN是未来 CMOS 2.0 架构的另一个关键特性。采用 BSPDN,整个配电网络被移至晶圆背面,从而可以扩大供电互连线的尺寸并降低电阻。因此,BSPDN 可以显著降低电源电压(或 IR)降。这有助于设计人员保持 10% 的裕度,以应对稳压器和有源器件之间不必要的功率损耗。通过将供电网络与信号网络分离,BSPDN 还可以缓解晶圆正面的 BEOL 拥堵,从而可以更高效地进行信号传输设计。
Imec于 2019 年率先提出了 BSPDN 的概念,并同时提出了几种实现 BSPDN 的方案 [8]。一些主流芯片制造商最近已将该技术纳入其逻辑路线图,并计划推出搭载基于 BSPDN 的先进处理器的商用产品。该技术在 3D SoC 实现中也展现出良好的前景, 预计 CMOS 2.0 架构也将从中受益。
始终在线和交换域设计中的 BSPDN:
相对于前端实现的性能和面积改进
过去,imec 已经证明了BSPDN 在模块级别上可为高密度和高驱动逻辑用例带来的PPAC 优势。这些优势已通过针对始终开启用例(即电源(即全局 VDD)持续输送至有源器件的架构)的设计技术协同优化 (DTCO) 研究得到证实。
在VLSI 2025 大会上,imec 还展示了在开关域设计 中实施 BSPDN 的优势,在这种设计中,标准单元块会被关闭以进行电源管理。开关域设计是通过在本地实现电源开关来实现的:这些设备将电源(本地 V DD)本地分配给晶体管,并可在需要时打开和关闭标准单元组。这类设计通常用于功耗受限的应用,例如手机。
Imec 的研究人员比较了在交换域设计中使用 BSPDN 与传统前端 PDN 实现的影响。这项研究是通过 2nm 技术的移动计算处理器设计的物理实现进行的。
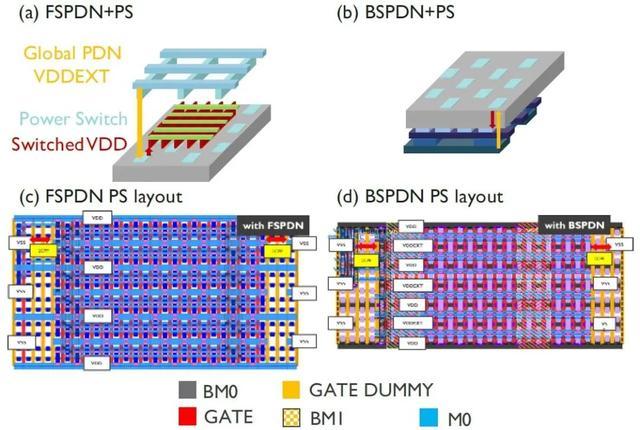
图 9 – (ab) 开关域设计的供电方式,其中电源开关呈棋盘格布局;(cd) 正面和背面 PDN 的电源开关布局。(VDDEXT=常开电源;VDD=开关电源;PS=电源开关。)
与前端 PDN 交换域设计相比, BSPDN 实现方案不仅提升了性能,还减少了面积占用。采用 BSPDN 后,IR 压降显著降低(降低了 122mV)。这使得 BSPDN 设计能够使用更少的电源开关,同时仍能控制可接受的 IR 压降。与前端 PDN 实现方案相比,减少的电源开关占用的内核面积更小:采用 BSPDN 实现方案,总面积减少了 22%。
结论
随着CMOS 2.0的出现,一种新的扩展范式将会出现,以满足日益多样化的计算应用。它依赖于功能层的堆叠——每个功能层都使用最合适的技术(节点)进行优化。细粒度背面处理以及细间距混合键合是实现这一愿景的关键。由SRAM分区推动的晶圆间混合键合和由功率传输优化驱动的背面技术的最新进展使CMOS 2.0概念更接近现实,从而在逻辑和存储器标准单元的粒度上提供层到层的连接。这些基础技术将使得在SoC本身内实现异构性(当前chiplet方法的核心)成为可能,从而为计算系统扩展创造更多选择。
