作者 | 程茜
编辑 | 李水青
DeepSeek和GPT合体写论文了!
智东西5月27日报道,昨晚,DeepSeek资深研究员陈德里(Deli Chen)放出一篇他和Agent合写的45页论文,其中99%内容都是CodeAgent所写。
论文题目是《从Copilots到同事:自主科研智能体综述(From Copilots to Colleagues:A Survey of Autonomous Research Agents)》,作者是陈德里、DeepSeek-V4-Pro、GPT-Image2。

陈德里还特意发了免责声明:这篇论文绝非严谨学术论文、不代表任何公司或组织观点,只是出于兴趣以及顺便测试下他搭建的DeliAutoResearch。
他透露,论文共迭代6次,耗时6天搞定,而初稿仅用了76分钟。期间智能体累计运行约108轮、消耗Token约64.8万、LaTeX代码共2234行,最终成品45页,其中包含7个图标、4个表格,文件大小538KB。陈德里也不禁感叹,同样的工作以前至少需要一个月才能完成,而这次他本人的“CPU运转时长”不到2小时。
陈德里是DeepSeek-V1、V2、V3、V4、DeepSeek-R1、DeepSeek-Coder、DeepSeek-MoE架构的核心贡献者,他曾获得北京大学信息管理学士学位及计算机科学硕士学位,曾在腾讯担任微信AI研究员。
这篇论文梳理了机器学习、软件工程、科学发现三大领域共计105篇相关文献,陈德里称已经对这些文献进行了验证。其核心目的是为能够自主开展研究的AI智能体提供统一的分析框架,主要有四项研究成果:
1、提出一套五级自主能力分级体系(L1–L5),层级从代码自动补全延伸至完全自主制定研究规划,为各类系统的界定与对比提供规范的术语标准。
2、剖析了四大主流架构模式:单智能体循环、多智能体协作、分层调度编排、工具增强执行;同时搭建对比分析框架,评估各类架构在可扩展性、成本、稳定性及人工监管方面的优劣取舍。
3、基于六维特征矩阵,对17款主流系统展开分析。研究结果表明,当前前沿系统普遍处于L4级别(限定领域内可完成多步骤自主执行),而L5级别仍停留在目标构想阶段。
4、梳理出六大核心待解难题:认知死循环、上下文窗口限制、创新价值评估、结果可复现性、安全风险与使用成本,并针对每项难题给出具体研究方向。
其研究分析发现,实现L5级自主能力的核心瓶颈并非模型基础性能,而是在于长效知识沉淀、可靠的自我评估能力,以及具备理论支撑的智能体架构规模化方案三大难点。
不少开发者纷纷在陈德里的评论区下面求开源。
论文:https://victorchen96.github.io/auto_research_survey.pdf
一、当前系统多为能独立产出论文的L4级,已有系统展现出L5级特征
论文将自主研究智能体定义为:一类软件系统,在接收到高层级研究目标后,能够独立执行科学探究的迭代闭环,包括假设生成、实验设计、执行、分析与迭代优化,且在执行流程中仅需极少、甚至完全无需人工干预。
自主研究智能体的五级自主能力分级体系(L1–L5),是基于两个维度:
一是智能体可对什么内容独立做出决策,二是智能体在无需人工审核介入的情况下,可持续自主运行多久。

L1的典型代表是GitHub Copilot等代码补全工具,这一层级中智能体可运行单个token或单行文本,核心能力是对人类撰写文本后续内容的预测,且人类完全主导内容的方向、结构与正确性。
论文中提到,从CodeX演化而来的代码补全模型,在受控编码任务中可实现30%-55%的效率提升,但无法独立完成多步骤目标。
L2的代表是带插件的ChatGPT、支持工具调用的Claude等对话式AI助手,智能体能够将定义清晰的任务拆解为多个步骤并执行,但每一步都需要人工的显式或隐式审批。
其能力包括网页搜索、代码执行、信息整合,全程需要人类引导对话、验证中间结果。
L3是代码智能体,这之中,智能体可自主执行10-100个连续动作,仅在预设的检查点、或遇到不确定情况时,才请求人工审核。其能自主查看代码仓库、编辑文件,无需人类逐步骤审批。
L3与L2级的核心区别在于:智能体可自主做出决策,例如选择编辑哪个文件、如何修复测试失败,无需逐步骤获得人工批准;人类仅保留监督权。
L4的代表是AI Scientist系统、Devin、SWE-Agent等,可自主生成研究思路、撰写论文、运行实验、产出完整论文,甚至完成自动化同行评审,全流程无人工干预。
这一层级的智能体接收到研究目标后,可独立运行数小时至数天,包括自主从故障中恢复、迭代优化策略、最终产出完整的研究成果。人类仅需评估最终输出结果,无需全程监督执行过程。
L5是自主能力的最高等级,智能体不仅能执行研究任务,还能自主选择研究问题、在多个项目间分配资源、基于过往成果持续迭代。
其研究显示目前尚无系统达到这一层级,可自主生成难度递增任务学习课程的智能体Voyager,可基于过往成功程序迭代发现新数学构造的智能体FunSearch已经展现出了L5的部分特征。

二、四大主流架构可适配不同层级系统
论文归纳了四大主流架构模式:单智能体循环(ReAct/Reflexion)、多智能体协作(MetaGPT/AutoGen)、分层编排(Supervisor-Worker)、工具增强执行(CodeAct)。
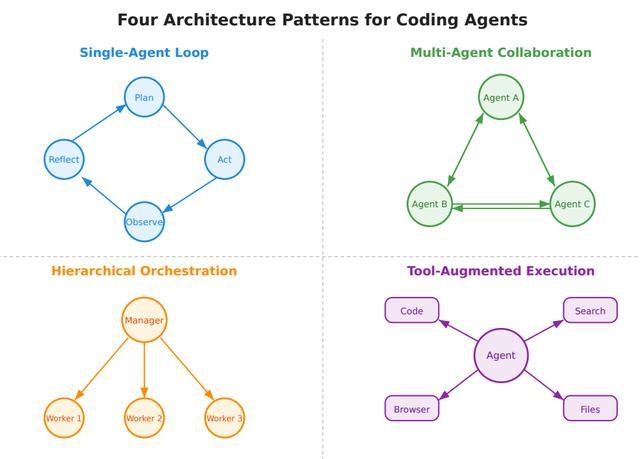
单智能体循环(ReAct/Reflexion):这是自主智能体中最简单、应用最广泛的基础架构,由单个语言模型迭代执行“观察环境→推理下一步动作→执行动作→吸收反馈”的闭环流程,是绝大多数L3-L4级系统的核心架构。
尽管架构设计简单,但它是绝大多数L3-L4级系统的核心骨架,且在推理策略上存在大量可优化、可变化的空间,适配性极强。
多智能体协作(MetaGPT/AutoGen):多智能体系统可以将任务责任拆分给多个专业化智能体,通过智能体间的通信与协作完成目标。
分层编排(Supervisor-Worker):随着任务复杂度不断提升,扁平化的多智能体通信模式会逐渐失效,分层编排引入了明确的监督管控关系:由一个高层监督者智能体负责拆解任务,将子任务分配给专业化的执行者智能体,同时监控任务进度,并在必要时介入调整。
最后是工具增强执行(CodeAct):这是自主研究智能体的核心标志性特征,是其与外部工具、外部环境交互的能力。工具增强执行将语言模型从被动的文本生成器,转变为计算与物理工作流中的参与者,再加上其可以外接代码、实验、网页,能力上限最高。
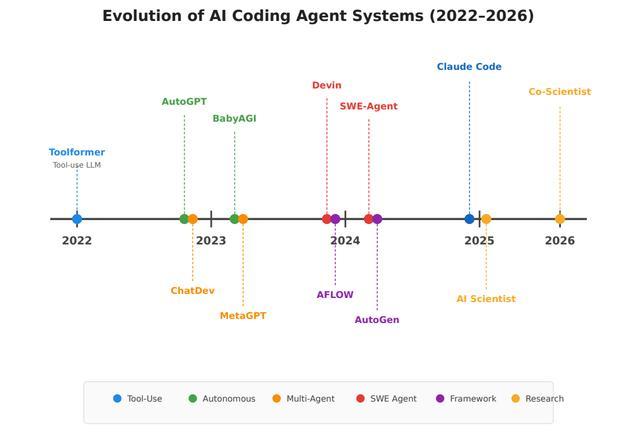
总的来看,L2级系统用简单的单智能体循环即可高效运行,L3级系统采用Reflexion,可天然嵌入检查点机制,收益最大,L4级系统通常需要分层编排架构,搭配自主迭代优化,才能在长时间自主运行中维持输出质量,理论上的L5级系统大概率需要具备自重组能力的图结构架构才能实现。
三、三大结论:开闭源差距收窄,专用智能体超越通用,代码智能体最成熟
基于六维特征矩阵,论文对17款主流系统展开分析,六维特征包括前文提到的L1-L5自主等级、核心应用领域、架构模式、工具集成广度、评测方法论、开源属性。
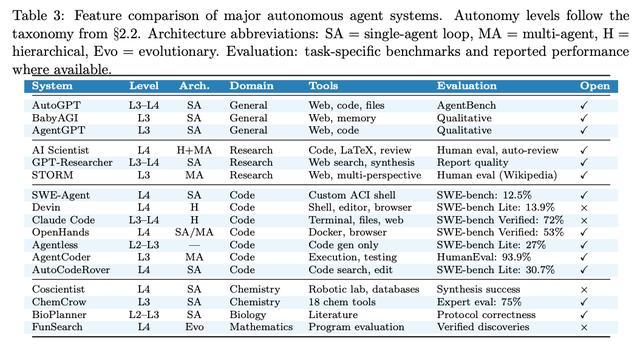
其得到三大结论:
首先更聚焦某一领域的系统,能力上限更高,其中,代码智能体在所有维度中表现最优,受益于自动化评测体系、成熟的工具环境、大规模基准测试的支撑,是当前行业最成熟的赛道。
其次领域专用智能体全面超越通用智能体,SWE-Agent、Coscientist、FunSearch等L4级系统均通过收缩应用范围实现了稳定输出,AutoGPT、BabyAGI等通用智能体,始终无法在多样化任务中实现稳定的L4级运行。
最后,开源与闭源的差距正在收窄,开源系统OpenHands的性能表现已经非常接近Devin等闭源系统。
在评测体系方面,论文提到了需要聚焦三大核心方向:
多维度指标:联合评估创新性、正确性、效率、安全性,而非单一维度的优化;长周期评测:追踪智能体在长期科研项目中的表现,而非孤立的单次任务;社群化评估:将专家反馈循环嵌入评测流程,建立行业共识的评估标准。
论文最后还给出了智能体系统六大核心待解难题:认知死循环、上下文窗口限制、创新价值评估、结果可复现性、安全风险与使用成本。
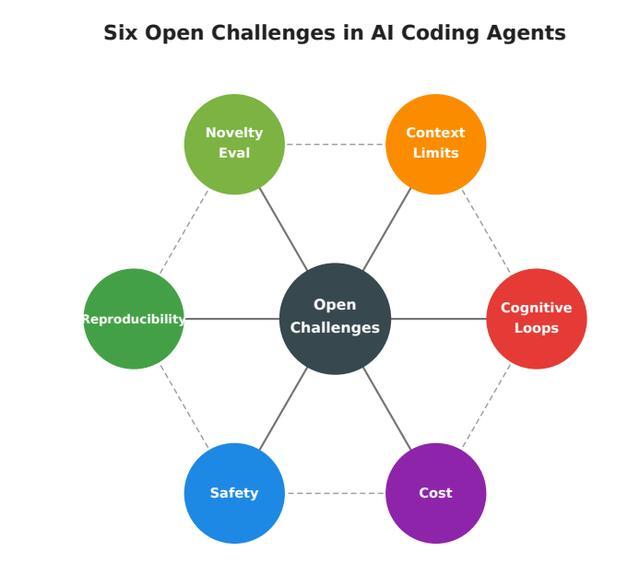
其中认知死循环、原创性评测、安全问题最为关键,因此认知循环问题使得智能体仍无法识别自身陷入困境,只会在失败策略上持续坚持,而非寻找全新方法;再加上其没有可靠的自动化指标,能衡量科研成果的质量与原创性,导致智能体无法在闭环中实现自我改进;最后随着智能体能力提升,其安全边界与伦理风险愈发突出。
结语:双AI协作产出完整论文,智能体真变身科研同事了
陈德里此次的实验,让智能体实现了从想法到完整论文的自主产出,其仅投入2小时人类思考时间,通过双AI协作就产出了AI科研综述论文,证明了AI从工具进化为“科研同事”的可行性。
AI此次面对长周期、长流程的复杂工作,最后生成的论文逻辑清晰且没有跑偏,展现出了超长文本处理、长流程持续执行、全程逻辑统一的核心能力。
在科研智能体领域,陈德里不仅用有趣的实验展现出了科研智能体的能力,还通过完整的论文分析解读展现出当下这一领域发展的现状及痛点,可以说是双管齐下,或为后续智能体的研究提供了新颖的参考方向。
