
5月25日消息,近日,海外博主Codez将所有和Claude记忆相关的信息,整合成了一篇如何让Claude拥有记忆的指南。他直言,现在还有很多人会遇到这样的情况:每次打开一个新的Claude对话,它都从零开始,不知道用户的名字,不记得昨天已经纠正过它三遍的事,更不记得用户讨厌列表式总结。
这不是Bug,这是大语言模型的底层特性,每个会话独立启动,除非你把上下文喂回去。
对聊天机器人来说这并没有什么问题,但对一个跑重复任务的Agent,如果它跑到第100次还和第1次一样,那简直是灾难。
不过解决方案已然推出:今年3月份,Anthropic向所有Claude账户推送了Chat Memory;5月6日,在Code with Claude活动上,Dreaming记忆系统作为Managed Agents的研究预览放出。
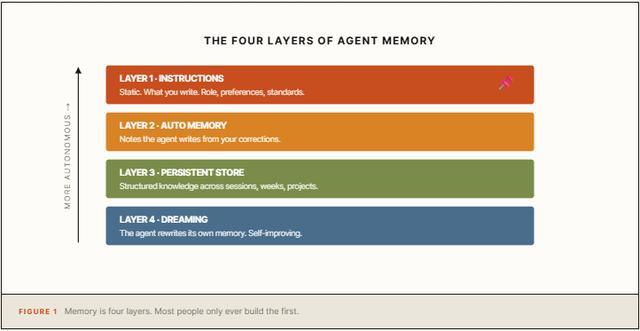
这两项功能加上正确的配置,构成了让Agent跨会话、跨周记住用户偏好的四层架构,以下是Codez总结的12步实操路径。
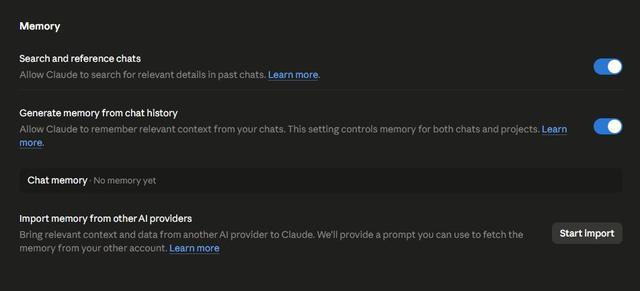
第一步是打开很多人并不知道已经存在的功能,3月份,Anthropic就已经向所有账号推送了Chat Memory功能,但很多使用者并不知晓。
操作路径:点击头像,进入Settings,找到Capabilities,翻到Memory区域,确认“Generate memory from chat history”已开启。开启后,Claude大约每24小时会对用户的对话做一次记忆合成,这是后续所有层级的基石。
第二步有些反直觉:不要等Claude从对话历史中推断偏好,用户需要直接告诉它。
比如,开一个新对话,输入:“请记住以下关于我的信息:我在科技领域工作,主要工作内容是文章撰写。我喜欢直接简洁的表述,不要列表。我的写作风格是简洁干练。永远不要过多修饰。”Claude会立即写入记忆,下一场对话开始就带着这些信息。
第三步是创建Project作为Agent的集合地。用户需要进入Projects,创建New Project,按任务分类进行命名,随后在自定义指令框中填入Agent的角色、标准和限制,之后这个Project里的每一场对话都会自动继承这些指令。
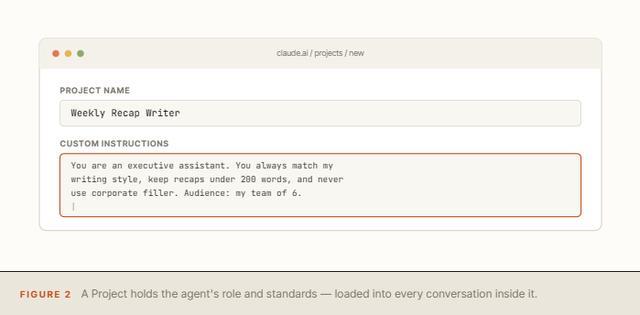
第四步是用户需要明白Project忘记的是什么,这是多数人踩坑的地方,Project只会持久地记住指令,在默认情况下不会记住对话历史。
很多用户建好Project、填好上下文、跑了几场对话,然后开启一个新对话,之前讨论过的所有内容会全部消失,架构决策、半截任务、调试过程,什么都没留下。
Anthropic的Project设计逻辑是:指令是常量,对话是变量。常量留在Project里,变量应该在每次会话中重新加载。问题在于,很多用户把Project当成“给Agent的长期记忆空间”来用,这是对产品设计的根本误读。
这也是为什么很多人用完Project之后觉得“怎么还是每次从头教”,因为他们把Project当成了记忆工具,事实上它只能记住指令。
二、持久记忆层:一个文件,让Agent每次开工前先读一遍
第五步是加一个活体记忆文件。最简单的持久化记忆就是设置一个文件,让Agent每次启动时读取,每次结束时追加。
在Claude Code里这个文件叫CLAUDE.md,在任意Agent里可以是放在Project Knowledge中的memory.md。这个文件关键的的规则是保持精简,也即一个新会话在你还什么都没输入之前,大概只能用2万个Token加载指令,不要把这个文件当维基百科来填,无需面面俱到。

第六步是开启自动记忆。Claude Code内置了auto-memory机制,用户可以在会话中用/memory切换,或在项目设置中开启“autoMemoryEnabled”,开启之后Agent会做轻量级自我记录,用户做出的调整可以保留到下个会话,而不是原地蒸发。
第七步是给记忆文件搭结构。一个只增长不整理的记忆文件会变成噪音。用户需要将记忆文件分段处理,Codez给出了下面这四个具体的分层案例:
决策段落:2026年4月18日,选Postgres而非Mongo,因为需要关系型报表。
常犯错误:不要自动通过涉及auth模块的PR。
第八步是决定什么值得记。不是所有东西都该被保存,每次重要会话后,Agent会回顾发生了什么,然后只提取值得保留的:一个决策、一个变通方案、一个偏好、一个错误,其他的都可以被舍弃。
什么是好的筛选标准呢?Codez总结的判准是,这个东西会不会改变Agent下次的行为?如果会,就保存;如果不会,就舍弃,什么都保留的记忆和全部丢失的记忆一样没用。
三、Dreaming层:让Agent自己“做梦”整理经验,Harvey效率暴增6倍
第九步是理解Dreaming到底是什么。5月6日,Anthropic在Code with Claude活动上将Dreaming作为Managed Agents的研究预览正式发布。名字是从神经科学借来的:人类睡眠时,大脑会将白天的经历巩固为长期记忆,Dreaming对Agent做的事情,逻辑上如出一辙。
它是一个定时运行的后台进程,读取Agent已有的记忆库和历史会话记录,产出一份重新整理后的新记忆库:合并重复条目、用最新信息替换过时内容、从大量会话中提炼出之前未被显式记录的洞察。
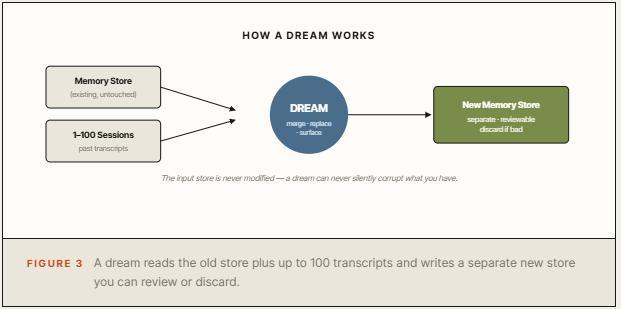
值得注意的是,Dreaming不是万能的。它只对反复跑同类任务的Agent有意义,也即跨几十上百场会话去识别模式,一个只用了几次的Agent,没什么模式可提炼,Dreaming帮不上忙。
第十步是跑一次Dreaming的API流程。Dreaming目前处于研究预览阶段,使用需要满足三个前提:持有Managed Agents的API密钥、通过Anthropic表单申请Dreaming访问权限、安装最新Anthropic SDK的Python或TypeScript环境。每次调用需要设置特定的beta头字段(dreaming-aware版本的SDK会自动处理)。
调用时输入现有的记忆库ID和最多100个近期的Agent会话ID,还可以通过指令引导Dreaming关注特定方向,比如“聚焦编程风格偏好,忽略一次性调试记录”。
预览期间支持的模型为claude opus 4.7和claude sonnet 4.6,费用按所选模型的标准API Token费率计费,成本随输入会话数量和长度大致呈线性增长。Anthropic官方建议从少量会话开始,先确认整理质量再扩大规模。
第十一步是关键的人工审查环节。输入记忆库在整个Dreaming过程中保持只读,Dreaming生成的是一个独立的新记忆库,它的ID会在运行完成后出现在输出数组中。
在切换使用之前,先把新记忆库通读一遍:合并的条目是否正确?被替换的旧内容是否真的过时了?提炼出的新洞察是真实模式还是数据噪音?这一步人工审查,是Agent越变越聪明和悄悄跑偏之间的分界线。
第十二步,信任输出质量后,用户可以改一行配置将Agent指向新记忆库ID,然后给Dreaming设置自动运行周期:每晚跑一次,或每周跑一次,这取决于Agent的工作密度。
至此闭环完整形成:Agent白天工作,间歇期Dreaming整理经验,每个周期后带着更锋利的记忆回来。不需要重新训练,不需要手动调参。
法律AI公司Harvey的实测数据是这个闭环价值最直接的证明:在法律文档起草流程中启用Dreaming后,任务完成率提升了约6倍。那些之前因为Claude在会话间反复忘记文件格式差异和工具变通方案而频繁卡住的任务,在记忆闭环建立后开始稳定跑通。
大多数人还是会用最习惯的方式打开Claude:一场新鲜但彻底健忘的对话,每轮重新解释自己是谁、要什么、最近在做哪件事,然后困惑Agent为什么总是不长记性。
把四层记忆框架搭起来的人,拿到的是完全不同的东西:一个认识用户的Agent,记得用户的偏好和决策,积累每一次踩坑的教训,自己定时整理和重写记忆,每周都比上周更强。
