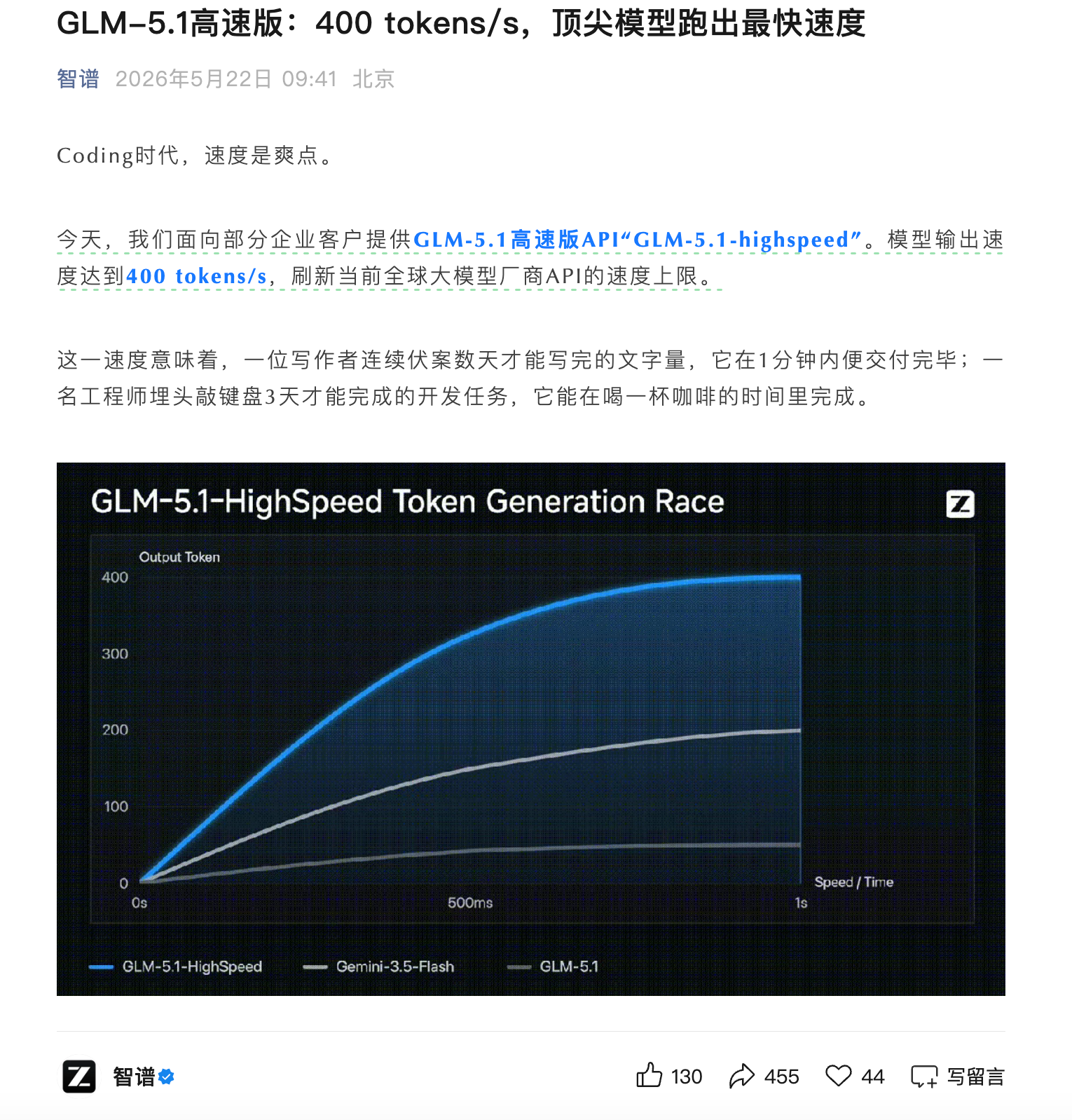
凤凰网科技讯 5月22日,智谱宣布面向部分企业客户推出GLM-5.1高速版API“GLM-5.1-highspeed”,模型输出速度达到400 tokens/s。智谱称,这一速度刷新了当前全球大模型厂商API的速度上限。
该模型基于旗舰级GLM-5.1能力开发,打破了此前“高速模型几乎总是轻量级模型”的行业惯例,首次在国产大模型中实现旗舰级能力与极致低延迟的兼顾。
高速版由智谱GLM团队与TileRT团队联合打造,通过推理引擎、调度系统与底层基础设施的系统级优化实现。据演示,在长程任务中,模型可在30秒内完成复杂网页的代码生成;在Agent Swarm场景下,可瞬间调度50个不同人格并行回答。
该API适用于AI编程、实时交互、商业决策、实时语音等对延迟敏感的场景,目前已向智谱MaaS平台部分企业客户开放。
