
新智元报道
编辑:KingHZ
【新智元导读】无论最终叫Veo 4还是Gemini Omni,这次泄露已足够震撼:AI视频不再是短视频工具,而是拥有导演思维的叙事生产力。谷歌I/O当天,答案即将揭晓,而整个行业,都将重新洗牌。
自动播放
现在,网友猜测Veo 4/Omni可以生成完整的多角度场景,在保持连贯性的同时流畅切换透视。

视频片段最长可达9秒,分辨率为720p。

部分泄露示例中仍存在连贯性问题,但完全同步的多机位场景看起来确实令人印象深刻。
这次关于Veo 4(或Gemini Omni) 的泄露,绝不仅仅是参数的微调.
它更像是一场关于「叙事权」的底层革命。
当AI开始学会从多个角度审视同一个瞬间,它实际上已经从「画匠」进化成了拥有空间逻辑的「导演」。
曝料人Pankaj Kumar甚至推测,谷歌应该轻松直出15秒视频,但缺算力。所以,谷歌要聚焦于效率问题。
但要注意,目前只有Kumar一个人的转述,是Veo4还是Gemini Omni,静待谷歌I/O揭晓。

回到一年前。
Sora横空出世那会儿,所有人惊叹的是「AI能拍60秒电影了」。
但你仔细看就会发现一个问题:那60秒里,镜头是不动的,或者说,是连续的。
机位在场景里平滑滑动、推拉摇移,但没有「切」。
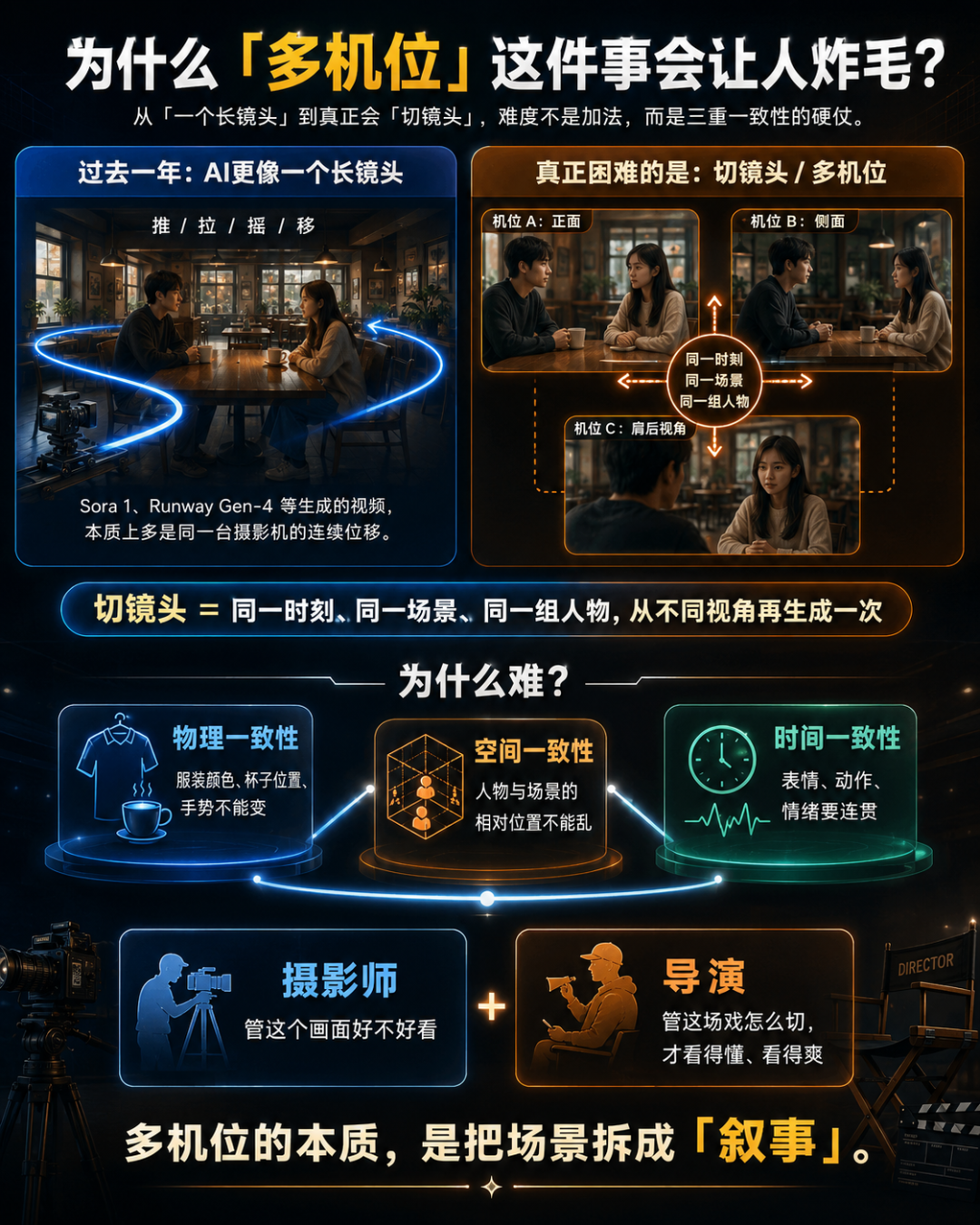
Runway Gen-4等所有同行产品都一样,生成出来的视频本质上是「一个长镜头」,哪怕镜头在动,也是同一台摄影机的连续位移。
为什么不能切?
因为对AI来说,「切镜头」意味着同一场景、同一组人物、在同一时刻、从完全不同的视角再生成一次,而且要保证服装颜色、桌上的杯子位置、人物表情连贯。
这是物理一致性、空间一致性、时间一致性三重压力叠加,业界一年来都在硬碰硬地啃,没人真做出来。
传统影视行业的从业者会告诉你,这件事在剧组里叫「机位调度」,是导演的工作,而非单纯摄影。
摄影师管「这个画面好不好看」,导演管「这场戏怎么切才看得懂、看得爽」。
多机位的本质,是把场景拆成「叙事」。
Pankaj Kumar的爆料如果属实,那Veo 4把这件事从「导演」压进了「模型权重」。
换句话说,你不再是「让AI拍一个镜头」,而是「让AI拍一场戏」。
这是个量级跃迁。
过去, AI视频是「短视频素材生产工具」,可以做点开头转场、做点背景画面。
这次,AI终于升级成「叙事生产工具」。
当然,前提是泄露属实、I/O当天演示真的能跑通。
同步音频补齐了最后一块拼图
爆料里第二个被反复提到的点,是音频。
具体说法是:Veo 4 原生生成同步对话、环境音,甚至会根据画面情境自动配背景音乐。
Veo 3已能做原生音频了,这不是Veo 4的新发明。
去年,5月Veo 3发布时,谷歌宣传的最大亮点之一就是「native audio」:视频里的脚步声、对话声、环境噪音都跟画面一起在模型里生成出来,不用后期对齐。

这一招把Veo 3从同行里拔了出来。
但有两个东西Veo 3没做好。
一是音质本身。
5月11日那波早期用户实测时,Reddit期待拉满了,反馈积极,但具体到什么程度不知道,但应该比Veo 3那种「AI配音感」再前进了一步。
二是背景音乐。
Veo 3主要做环境音和对话,情境化的配乐基本不在它的活儿范围。
Kumar这条爆料明确点出「contextual background music generated natively」,如果真的成了,意味着AI视频从此自带BGM。
把多机位和原生BGM放一起看,你就能感觉到谷歌这盘棋的轮廓:它不在拼「谁的画面更细腻」、不在拼「谁的物理更逼真」。
它在拼「谁能直接出一条成片」。
镜头会切,声音对得上,BGM自带。剩下的,差一个剧本。
Sora已死,谷歌选这个时间点摊牌
Veo 4泄露的时间点,精准卡在 Sora 倒下的废墟之上。
4月26日,OpenAI的Sora App正式停服。

烧钱。Sora推理成本据称每天100万到1500万美元,比文本和图像生成贵了不止一个量级,整个生命周期没把单位成本压下来。
留不住人。峰值100万MAU,停服前跌破50万,30天留存不到8%。
不赚钱。整个生命周期App内收入约210万美元,连一天的算力费都覆盖不了。
3月24日,Sora官方账号发出告别——「We’re saying goodbye to the Sora app」。
API将在9月24日彻底关闭。

商业上的差距已经摆在数据里。技术上的代差,这次泄露算是把帐挑明了。
OpenAI倒下的位置上,谷歌选了一个非常贴脸的时间点踩上去。
I/O当天,谷歌还会亮哪些牌
Omni只是这场泄露的一角。
同一波泄露中,谷歌即将推出的多款 Gemini 模型被意外推送到了生产环境 API——Gemini 3Flash、3.1全系列(Pro、Flash Image、Lite、TTS),以及专注于高保真音频生成的Lyria 3 Pro。

最重磅的一句话藏在内部文档里——「Omni模型将针对所有核心模型推出专门的Agent版本。」

意思很直白。
谷歌要把视频生成、音频生成、Agent框架一起摆上I/O的台面。
一年前,Pichai说要把Gemini「装进每一个谷歌产品里」.
这一次,他大概会让大家亲眼看见这句话兑现的样子。
