
作者|江宇
编辑|漠影
智东西5月15日报道,昨日,豆包输入法macOS版正式上线,用户终于可以在电脑上直接“张嘴打字”了。
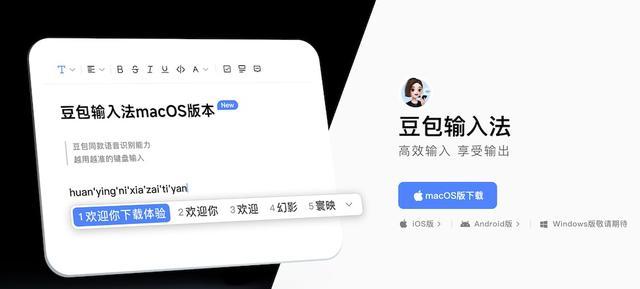
和传统输入法里的“语音转文字”功能不同,这次豆包输入法主打的,是一整套AI语音输入能力。
其背后采用的是豆包App同款语音模型,重点强调“边说边出字”“中英文混说”“智能纠错”和“长文本输入”等能力。
目前,豆包输入法支持在任意对话框中实时语音转文字,且没有时长限制,适合长文案、小说、会议记录等持续输入场景。
同时,它还支持中英文混说、多种方言识别,无需手动切换输入法,可自动识别语言。
在AI能力部分,豆包输入法加入了“智能纠错”和“个性化记忆”功能,其能够自动修正部分语气词、语病和口误,并逐渐记住用户的改词习惯,让语音输入越用越准。
此外,豆包输入法还支持轻声识别和抗噪能力,在办公室、咖啡店、图书馆等环境中,也能进行低音量输入。交互模式上,则提供“长按”和“免按”两种方案。
某种程度上,AI语音输入正在成为新的输入趋势。过去,语音输入更多还是手机上的“临时替代方案”,但随着Vibe Coding等场景越来越普及,很多用户开始长时间“和电脑说话”。
目前,市面上已经出现了微信输入法、智谱AI输入法(小凹)以及Typeless等AI语音输入产品,其中不少已经开始收费。相比之下,豆包输入法目前免费推出,这或许也会成为它吸引用户的一大优势。
那么问题来了:豆包输入法,真的好用吗?
这次,我们从延时、中文准确率、中英文混说、方言识别、智能纠错以及个性化记忆几个维度,对它进行了实测。
一、普通话几乎边说边出,粤语还在等AI“补作业”
语音输入最核心的问题,其实只有一个:跟不跟得上人说话。
在普通话场景下,豆包输入法整体表现还是比较流畅的。无论是短句、长句,还是中英文混说,基本都能做到“边说边出字”。
主观感受下来,它的首字延迟大概会略高于1秒,完整句子的生成延迟通常会控制在1秒以内。而且在连续长文本输入过程中,它的整体卡顿感并不明显。
但到了方言场景,尤其是粤语等复杂方言,体验就会大不相同。它不像普通话那样一句话刚说完立刻就能识别,反而是“先听一遍,再靠AI后处理”。
很多时候,前半句几乎没识别出来,后面才开始通过上下文一点点修正。部分长句甚至会出现超过5秒以上的完整句延迟。
原句(粤语):哗,出面做乜突然间落咁大雨嘅?係啰,明明头先仲好地地。死火,我赶住出去呀。不过依家大风大雨,好易湿身㗎。唔使惊!我带咗遮同埋雨褸添。都係你够醒目!
对应普通话:“哇,外面怎么突然下这么大雨?就是啊,明明刚才还好好的。糟糕了,我赶着要出去呀。蕭汉过现在风大雨大,很容易湿身的。不用怕!我带了伞还有雨衣呢。还是你够聪明!”

比如在我们的测试中,第一句“哇,出面做乜突然间落咁大雨?”其实被完整识别了出来,准确度是没有问题的。
但到了后半段,识别结果就开始出现较大偏差,大部分内容都没有正确识别出来。
东北话的表现则明显更稳定一些。在我们的测试里,除了“旮沓”等个别词汇出现问题之外,其余内容大体都能正常识别。
原句(东北话):哎呀妈呀,咱东北这旮沓老好了,那雪下的老大了,跟棉花套子似的。冻梨啃一口,甜滋滋的,拔凉拔凉的。铁锅炖大鹅,那香味老霸道了。

闽南语则基本属于“困难模式”。目前识别效果仍较差,很多句子几乎无法正确转写。
当然,这本身也是整个行业里最难的问题之一。不同方言之间,口音、连读和词汇差异本来就很大。如果你本身会说方言,或许也可以自己试试看,它到底能听懂多少。
二、甄嬛传名场面没翻车,但外国人名还是有点难
中文准确率,是这类产品另一个核心能力。
这次,我们专门选了两个“难题”。
第一个,是《甄嬛传》“滴血认亲”名场面。因为文言式表达、人物称谓、停顿节奏和长句结构,本身都比较复杂,对语音识别其实很不友好。
原话:臣妾要告发熹贵妃私通,混乱后宫,罪不容诛。宫规森严,祺贵人不得信口雌黄。臣妾若有半句虚言,便叫五雷轰顶,永不超生。我还以为是什么毒誓呢,生死之事谁又能知啊?可见祺贵人不是真心的了。臣妾以瓜尔佳氏一族起哲,若有半句虚言全族无后而终。

但实际测试下来,豆包输入法的表现比预期更稳定。它在长文本输出过程中,能够持续进行动态修正。包括人称、断句、标点,甚至部分误读内容,都会在后续识别过程中不断调整。
最终结果里,文言表达、标点符号和整体句意没有错误。这种“边识别边回改”的机制,近乎可以看成AI写作过程中的实时润色。
第二个测试,则是科技新闻场景。我们读了一段关于“马斯克诉奥尔特曼案第三周庭审”的内容,重点测试它对外国人名的识别能力。
这一部分难度更高。因为很多英文人名本身就存在多种中文译法,而且中文互联网里也没有统一标准。
原话:马斯克诉奥尔特曼案进入第三周,被告方关键证人相继出庭,微软CEO萨提亚·纳德拉、OpenAI联合创始人兼前首席科学家伊利亚·苏茨克维,以及OpenAI基金会董事会主席布雷特·泰勒作证。此前在第二周庭审中,马斯克方主导举证,OpenAI前CTO米拉·穆拉蒂、前董事海伦·托纳、塔莎·麦考利、前员工罗茜·坎贝尔,以及非营利治理专家戴维·希泽等证人的证词和庭审材料陆续浮出。

实际结果里,部分名字能够正确识别,但也出现了译名不统一的问题。比如“戴维·希泽(David Schizer)”并没有被识别成常见译名,部分外国人名中间的分隔点“·”也出现缺失。
日常聊天问题不大,但如果是新闻写作、法律文件或正式场景,后续还是需要人工再核对一遍。
三、中英文混说准确率很高,“外企黑话”也能听懂
如果说方言是困难模式,那中英文混说,则是豆包输入法目前完成度较高的一部分。
无论是人名、英文缩写,还是各种办公场景的常用语,它都能较稳定地识别出来。而且,它对于中英文切换时的断句和标点处理,也比传统输入法自然很多。
原句:Jennifer,晚上跟Global的会议改到明天早晨7点,你记得reschedule一下。还有换个大点的meeting room,因为FinanceEric and HR的Susie也要参加,还有提前把要讲的topic再go through一遍。辛苦跟Laura说下,会上帮忙记下meeting minutes。so far我就想起这么多,如果有新的update我再跟你sync。

很多时候,用户输出并不需要刻意放慢语速。整体主观感受下来,中英文混说场景的准确率,大概率已经可以稳定达到95%以上。
对于外企办公的人来说,这部分功能其实是比较实用的。
四、能清理语气词,但暂时还不会“主动润色”
相比识别能力,“智能纠错”其实是这次最让人期待的功能之一。它涉及一个问题:AI到底应该“忠实记录”,还是主动让AI帮你改。
从实际测试来看,豆包输入法目前整体偏向前者。比如一些简单语气词,像“嗯”和“呃”之类,它确实可以自动清理。
但更复杂的口语化重复、逻辑跳跃或者临时改句,它目前还不会主动帮你重写。
例如们在测试时说:“我想11点……不对,是11点半,请李铭喝咖啡。”

最终输出里,“11点”并不会被自动删掉,而是完整保留了用户原本的修改过程。
包括一些讲话过程中不断反复修改句子的情况,它也不会主动整理成更通顺的书面语言,尽量保留原话。

目前,市面上一些AI语音输入产品,如Typeless和智谱AI输入法(小凹),已经开始覆盖“自动润色”“自动改写”等功能。它们会主动删除废话、重组句子,直接帮用户优化表达。
相比之下,豆包输入法当前的策略会更保守一些,强调对原始表达的保留。
五、改错一次之后,它就会记住你的写法
个性化改词,是这次体验里最实用的功能之一。
比如在人名场景里,语音识别经常会遇到同音字问题。
第一次输入时,系统可能会给出错误写法。这时候,用户只需要手动修改一次。等到第二次再语音输入同样的人名时,豆包就会优先采用用户之前修改后的版本。

长期使用后,这种“记忆”也是是明显感知到的。除了人名之外,一些公司名、产品名或者固定术语,也存在类似情况。这类高频专有名词,其实是很多人日常语音输入里最容易反复修改的部分。
结语:不需要键盘了?或许我们更需要一个麦克风
相比键盘输入,语音输入最大的优势,其实一直都是“更快”。
而在AI能力加入之后,语音输入也不再只是简单“转文字”了。实时修正、自动断句、上下文记忆,以及更高的识别准确率,都开始让它变得更实用。
与此同时,语音输入的使用场景也在扩大。
过去,很多人只会在开车、走路时偶尔使用语音输入。但现在,随着轻声识别、抗噪等能力出现,办公室、咖啡店、图书馆等环境,也开始能够正常使用。
某种程度上,AI语音输入法正在重新改变人与电脑的输入方式。或许未来很多人想打字,第一反应不是找键盘,而是先找麦克风。
