下一代计算架构主阵地,正经历历史性位移。
作者 | 程茜
编辑 | 漠影
历经484天,全球AI产业翘首以盼的DeepSeek-V4正式发布、全面开源,其同步甩出的一份硬核技术报告,为算力时代的演进写下全新注脚。
它以系统级创新,将KV Cache规模扩展至百万级上下文;系统性压缩机制的引入,既降低存储与计算的庞大开销,也将计算流水线的深度与复杂度推向新高度,这每一处技术突破,都是对算力发展极限的叩问。
再将时间拨回2025年末,还有一笔打破常规的交易横空出世:英伟达以200亿美元天价拿下AI推理芯片独角兽Groq LPU推理技术的非独家授权,并将核心团队纳入麾下。
DeepSeek-V4的技术演进,为数据流架构释放极限性能提供了适配场景;Groq 被英伟达收编后也同样押注的是数据流架构方向,这一产业新变量已然跻身全球AI产业核心舞台,成为撬动算力革命浪潮的重要力量。
算力革命的洪流奔涌向前,巨头的每一次布局,都暗藏着行业迭代的风向。回望计算机技术的演进,每一次划时代的技术革命,本质上都是一场对算力平台的豪赌,技术路线的选择往往决定了未来数十年的产业格局。
在PC与互联网的时代,英特尔(Intel)凭借x86架构的绝对性能统治了算力疆域,并在此基础上构筑了难以撼动的软件生态帝国。然而,随着HPC与AI浪潮的到来,技术范式悄然切换。英伟达(NVIDIA)以CUDA生态配合TensorCore架构,较x86架构实现了十倍的性能跃迁,确立了其新一代算力霸主的地位,助其登顶全球市值之巅,完成了从图形处理器到AI引擎桂冠的加冕。
因此,英伟达创始人、CEO黄仁勋比任何人都清楚,算力平台的更迭从不温情脉脉。当年英特尔在x86生态的温柔乡中沉睡,未能预见并行计算的浪潮;如今英伟达坐拥CUDA帝国,正直面一个更残酷的现实——当Transformer架构的算力需求每两年暴涨750倍,当单卡算力逼近物理极限,谁会成为新一代的算力平台?
十倍级的代际跃迁往往诞生于架构的颠覆而非工艺的改良。在GTC 2026大会上,英伟达正式推出Groq 3 LPX机架级推理平台,黄仁勋称,Groq 3 LPX平台与Vera Rubin NVL72结合使用的混合架构,可实现GPU强劲算力与LPU极致带宽的完美互补。这迅速引发行业关注。
纵观产业界,除了英伟达这个GPU霸主,正在给自己找一条“非GPU”的退路,此前英特尔被传以16亿美元价格收购SambaNova,后转向深度合作。巨头们的焦虑已写在脸上。
而在国内,大额融资、订单的橄榄枝纷纷抛向鲲云科技、清微智能等。
这些看似分散的热点,其实指向同一个技术原点——可重构数据流架构。
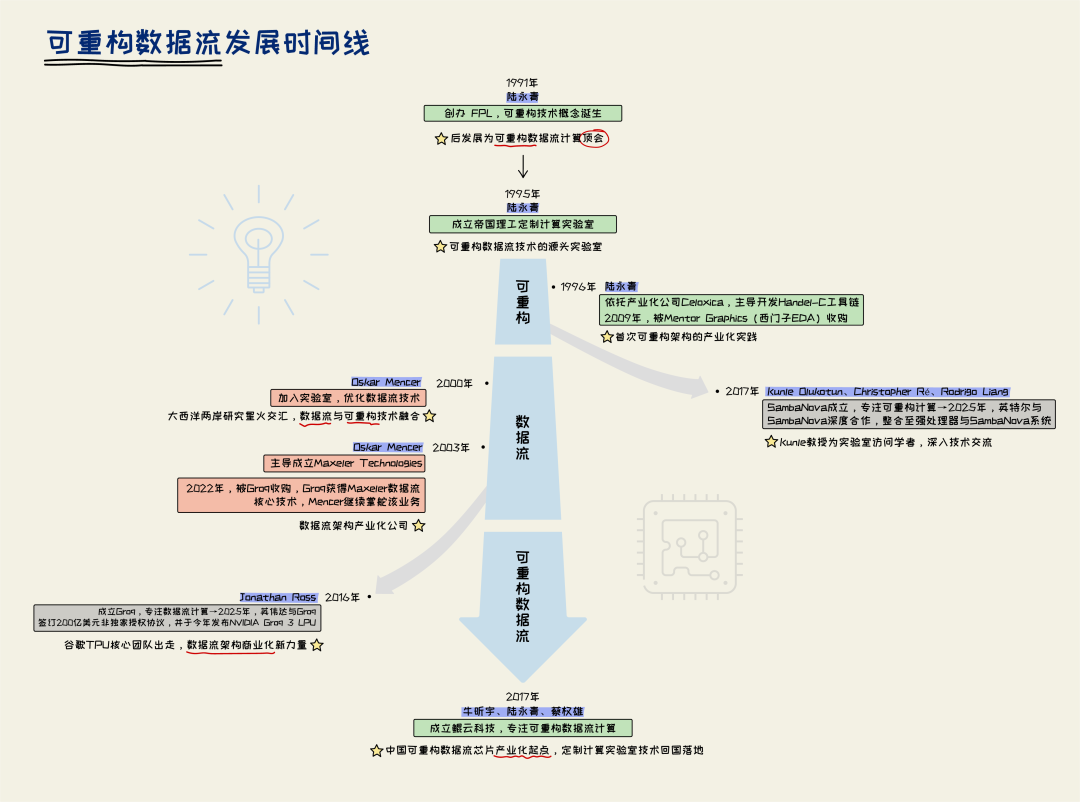
冰冻三尺,非一日之寒,新技术的演进、成熟、落地也非一朝一夕之功。技术的起点不在GPU架构性能瓶颈逐渐明确的当下、亦不在GPU挑战CPU全球算力霸主的时代;它的起点在更早之前,在英伟达还未成立之时,在那个制程工艺快速迭代、CPU仍然统治算力平台的时代,从几个学者的兴趣到学术社区的建立,从一代代实验室技术的传承到产业化的星火燎原,至今已过了三十多年。
让我们把时钟拨回35年前,从牛津大学的一间会议室说起。
01.
帝国理工学院的一间实验室
可重构数据流架构火种诞生(1991-2000)
1991年,牛津大学的一间会议室内,陆永青博士筹备了一场计算机体系架构的研讨会,一种新的架构思路开始被讨论:改变硬件来适配软件应用。
传统架构依赖指令集体系进行计算管理,指令间通过统一的存储地址空间进行配合,造成数据读写与计算的串行关系,影响计算效率提升。
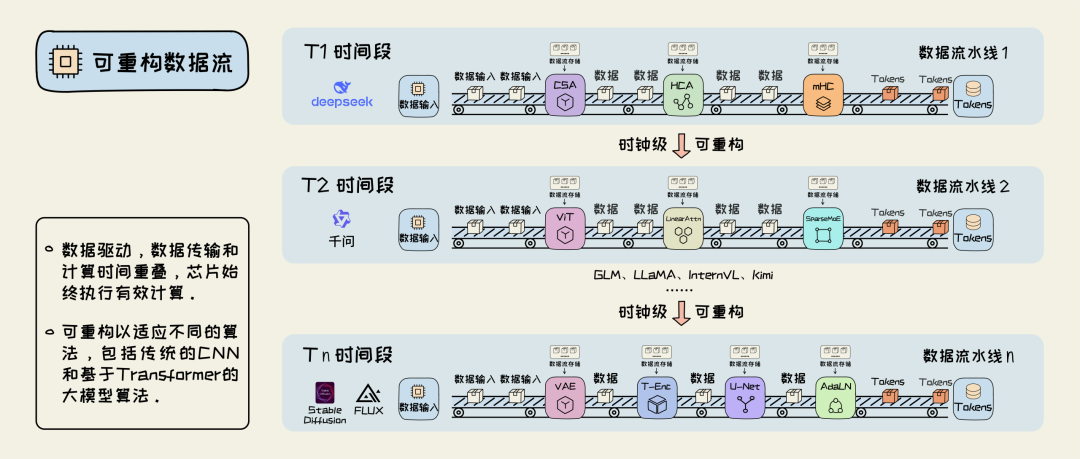
如果在架构设计中将所有指令集移除,依靠深度流水线与数据流动次序控制计算,如下图所示,理论上不存在数据读写带来的计算空闲,可以发挥物理极限性能。与此同时,在运行时重构计算电路,则可以解决计算通用性。
陆永青与其导师Ian Page找到了新的路径,其推出的Occam高层编译方法成为可重构数据流架构历史上首次给出的系统性工程化方案,在这次牛津大学研讨会上发表,成为后来Handel-C编译器的基础:用C语言做硬件并利用现场可编程技术,去兼顾极致性能与架构通用性。
这次研讨会,后来成为欧洲最大的可重构计算顶会FPL(现场可编程逻辑),连同陆永青创立的亚洲顶会FPT、其作为创刊主编创立的ACM TRETS,在此后的数十年间,成为这个新技术路线的主阵地。
不同于英特尔、英伟达所主导的固定硬件架构,改变软件适配不同应用,新诞生的技术专注于完全相反的方向:改变硬件适配不同应用。类比到汽车制造行业,就相当于工厂能够改变流水线配置,从而针对不同车型打造专门的流水线,并通过传送带替代人工搬运来解决数据搬运的时间消耗,这种架构思路通常能带来10倍甚至百倍的性能提升。
▲1991年FPL海报(图源:FPL会议官网)
9月6日,会议结束,从此开创了一个全新的计算架构,就是如今可重构数据流架构的雏形,奠定了该技术未来的核心发展方向。作为创始人的陆永青也成为推动这一领域发展的关键先驱人物。
1995年,他从牛津大学转职帝国理工学院,成立定制计算实验室。作为可重构数据流技术的源头实验室,Groq、SambaNova、鲲云科技这些国内外知名创企的成立、演进,都与这家实验室有着千丝万缕的联系。
技术的终极命题在于更好的落地应用。定制计算实验室诞生初期瞄准的就是可重构数据流架构的两大核心挑战:
• 数据流,面向特定应用场景实现逼近物理极限的计算性能;
• 可重构,在多样化场景的定制化架构间实现灵活切换与通用适配。
后来Occam编译技术被分拆,成立了Celoxica,其Handel-C工具链部分被欧洲EDA巨头Mentor Graphics收购,而这家巨头就是如今大名鼎鼎的西门子EDA。
Celoxica的诞生,首次将可重构数据流架构从理论构想淬炼为可供产业使用的算力方案。陆永青与德国学者Markus Weinhardt所奠定的流水线矢量化方法,也借此完成了从学术创想到工业基座的蜕变,为即将到来的技术浪潮埋下了决定性伏笔。
02.
大西洋两岸火种交汇
三代学者接力啃下产业化难题(2000-2016)
与此同时,大西洋彼岸的斯坦福大学,亦点燃了可重构数据流架构的研究火种。
同为各自技术路线的奠基学者,陆永青与Flynn为多年朋友。Flynn教授虽然一直钟情于指令集架构研究,但他在Bell Labs工作的学生Oskar Mencer却对硬件数据流架构情有独钟,由他主导推进的StReAm,正是面向自适应计算设计的典型数据流架构。
在奥地利FPL会议上,陆永青与Mencer相识,大西洋两岸的研究星火正式交汇,其后Mencer加入帝国理工任教职人员,他们合力推动数据流电路的极致优化,通过将流水线中所有软件移出,让硬件流水线获得逼近物理极限的性能,实现每个计算单元每个时钟周期都进行有效计算。

▲陆永青(左一)、Oskar Mencer(左二)获帝国理工学院卓越研究奖(图源:帝国理工学院官网)
随着研究不断深入,可重构数据流架构与产业界的结合日益深厚,金融、医疗、石油勘探都成为这一技术路径发挥作用的场景。2003年,雪弗龙石油的油田勘探工作受算力瓶颈制约,Mencer打造了高性能加速计算平台,实现了油田钻井效率的百倍提升。
这之后,Mencer主导成立的Maxeler Technologies将上述研发成果产业化,后来他慢慢专注于Maxeler的管理,逐渐淡出定制计算实验室。
Maxeler的数据流计算系统客户可谓大名鼎鼎,包含金融领域的JP Morgan、Citibank,能源领域的雪弗龙、ENI,还有英国Daresbury、德国Jülich等国家级超算中心。Maxeler与这些客户的合作证明,可重构数据流架构已经成为企业关键业务的刚需算力载体。
Mencer之后,海内外学者前赴后继。
陆永青教授创办的帝国理工定制计算实验室成为北美、欧洲、亚洲学术讨论与交流的交汇点。Michael Flynn之后多位指令集技术体系学者到定制计算实验室交流访学,其中就包括斯坦福大学的Kunle Olukotun教授。多年后,Groq收购了Mencer创办的Maxeler Technologies,而Groq正是当时Olukotun创立的SambaNova在美国最大的竞争对手,亦是这种全球技术交流下的必然。
随后,协助陆永青管理实验室的,同样是一位香港学者:本硕博均毕业于香港中文大学的蔡权雄。他在定制计算实验室主导了CUBE与Axel集群两大标志性项目,为可重构计算的规模化验证打下了重要工程基础。
其中,CUBE将64颗FPGA在一个超大型印刷电路板上用Torus互联结构组成更大计算节点,谷歌TPU团队用2D Torus将TPU互联也采用了类似思路。
Axel集群则是用32台异构计算节点,每个计算节点包含FPGA加速卡、GPU加速卡、高性能CPU,节点间用InfiniBand和Gigabit Ethernet互联,成为支撑实验室多年科研工作的核心算力平台。
▲CUBE项目论文主页
啃下这两块硬骨头后,对工程实现充满热情的蔡权雄投身工业界,挑战“芯片”这一大工程,后续加入英国芯片企业Imagination Technologies负责 SoC芯片研发。
毕业于复旦大学的新一代的实验室负责人牛昕宇成为推动可重构数据流向ASIC演进的关键人物。
凭借高度可编程性,FPGA曾长期作为定制计算实验室研发与产业化的主力平台。其多粒度可重构特性可完美适配各类可重构数据流架构,实现极高的算力利用率,但比特级重构依赖大量SRAM,在芯片面积、功耗与重构延迟上付出数倍乃至十倍代价。
这让可重构数据流架构的优势被现有验证平台自身的巨大开销抵消,性能增益被严重抹平,尤其在与英伟达新一代旗舰芯片的正面交锋中,二者峰值算力差距悬殊,在实际应用层面难以展现其性能优势。
从成立鲲云科技后的技术与产品方向来看,当时牛昕宇已经意识到必须要找到足够深的应用场景做ASIC芯片,才能彻底释放这一架构的全部潜能。
而当时时代抛给他们的命题是:究竟哪个战场,才拥有足够磅礴的算力需求,足以支撑起这样一颗全新架构ASIC芯片的诞生?

▲陆永青(左)、牛昕宇(右)(图片来自网络)
时值2011年前后,这个问题在实验室内部无人能解,放眼全球业界亦无定论。可编程逻辑解决方案供应商Tabula曾以通信领域为突破口,融资逾两亿美元大举推进,最终未能打通产业化通路。
面对前路迷雾,实验室在仿真计算、生物计算、金融计算与机器学习场景探索的研究成果陆续发表,几乎覆盖了当时所有具备潜力的高性能计算场景。在实践中,牛昕宇与陆永青给出了最务实的答案:既然方向未明,便广撒网、逐场试炼。
站在2026年回望,答案已不言而喻,真正承载起磅礴算力需求的,正是彼时方才萌芽的全新算法浪潮:深度学习。然而在十五年前,探索者们只能靠一次次试错与返航,慢慢拼凑出完整的技术版图。从实验室同期发表的成果中不难窥见,其研究重心逐步收敛:从各类通用应用,聚焦到卷积与矩阵运算,最终锚定深度学习加速。
在这条没有前路可参照的长期主义创新道路上,陆永青以600余篇高水平论文,构筑起可重构计算领域坚实的理论与技术根基,成为国际上少有的三院院士(IEEE Fellow、英国计算机学会会士与英国皇家工程院院士),在这一领域拥有无可替代的学术地位,其研究成果深刻影响了赛道内一系列关键方向的发展。
从陆永青奠基开创、点燃可重构计算的学术火种,到蔡权雄、牛昕宇等人接力传承、持续添薪,三代人跨越二十载深耕不辍,让可重构数据流架构与深度学习的交汇之路,从模糊理念走向清晰图景探索。
03.
下一代算力平台之争:
从群雄并起到三分天下(2017年至今)
2017年,AlphaGo的火热与谷歌TPU的出世,为可重构数据流架构的AI芯片产业化铺平了最后的道路。帝国理工定制计算实验室核心团队:实验室创始人与两代实验室负责人回国创立鲲云科技,正式启动了中国的产业化征途。
与此同时,大洋彼岸的硅谷,一场同样聚焦可重构数据流技术的算力角逐同步启幕。SambaNova与Groq相继成立,成为搅动全球AI芯片格局的新生力量。
Groq由深度参与谷歌第一代TPU研发的Jonathan Ross带领核心研发阵营创办。为打造数据流技术壁垒,2022年3月,Groq收购了定制计算实验室在鲲云之前的产业化企业Maxeler,将其核心技术纳入麾下,在后续产品迭代中深度融合数据流相关技术,构建起自身的技术竞争力。

而与Groq并肩站上赛道的SambaNova,由斯坦福大学两位教授Kunle Olukotun、Christopher Ré,以及甲骨文前高管Rodrigo Liang联合创立。
作为核心技术灵魂人物,Kunle Olukotun教授早年深耕多核CPU计算领域,后将研究重心转向可重构计算,与帝国理工学院定制计算实验室建立合作。可以看到,在创立SambaNova前后,Olukotun教授于2018年出席了鲲云科技在深圳主办的全球人工智能应用创新峰会,同场的MIT的Arvind教授,曾从事早期动态数据流架构的研究工作。这是一次技术产业化的早期碰撞。

▲Kunle Olukotun教授(左三),Arvind教授(左七)(图片来自网络)
时代浪潮下,全球算力赛道技术演进逐步走向深水区。彼时少有人关注的可重构数据流技术交流日深,而同期崛起的企业路线渐渐分野,最终在可重构数据流计算的版图上,镌刻出三大核心技术方向:数据流架构、可重构架构,以及兼具二者优势、融合创新的可重构数据流架构,开启了三足鼎立的技术博弈时代。

▲可重构数据流架构赛道三条技术路线(智东西制表)
数据流路线以谷歌TPU及Groq为代表,从谷歌TPU的脉动阵列,到Groq LPU,始终围绕深度学习构建极致硬件流水线,一路向着物理性能的天花板突进。
2016年,谷歌发布第一代TPU,以片内固定计算阵列为骨架,凭借二维数据流执行模式,实现确定性、高吞吐的强悍算力输出。时至今日,TPU的产业地位已如日中天:AI独角兽Anthropic高达210亿美元的巨额订单、Meta数十亿美元的采购协议纷纷投向谷歌,苹果、SpaceX等科技巨头亦成为其潜在重要客户,数据流架构的战略价值尽显无遗。
Groq的诞生,是谷歌第一代TPU核心团队对“无指令集”理念的极致贯彻。创始人Jonathan Ross深谙脉动阵列之痛,为Groq LPU选择了一条最激进的路径:彻底抛弃冯·诺依曼架构的指令调度,将硬件打磨为一条刚性的超级流水线。2024年2月,Groq凭借运行Llama 2 70B时十倍于同期GPU的生成速度与极低延迟,一战成名,让世界看到了架构的性能神话和在大模型推理时代的统治力。
可重构阵营,SambaNova凭借硬件动态重构能力,可在电路运行时灵活改变结构,通用性远超传统数据流架构。在其白皮书设计中,计算单元互联采用可重构架构,核心计算基于SIMD核,终究难以摆脱指令集束缚,无法触及无指令集数据流流水线的极致性能。国内可重构芯片技术的代表企业是清华系的清微智能,探索算力可重构方向。
鲲云科技则是可重构数据流阵营的代表企业,其架构本质集可重构与数据流优势:数据流以硬件流水线形式提供极限性能,可重构以动态可重构调整硬件电路提供通用性。鲲云科技发布的初代产品CAISA3.0(全球首款可重构数据流量产芯片),第三方测试数据显示,相较于同期英伟达产品,CAISA3.0实现了高达11.6倍的芯片利用率提升与134.93倍的延迟降低,以量级优势展现了可重构数据流架构的潜力。第二代芯片CAISA430量产和进一步落地,其在深度学习和大模型推理等模型支持上延续了同等的性能代际优势。

综上,一众先锋企业入局可重构数据流领域,开启产业化征途。点点星火就此汇聚,东西方顶尖技术力量形成呼应,终成席卷下一代计算架构的燎原之势。
04.
可重构数据流性能神话之后
规模化商业化突围
正如开篇所言,大道至简,一代算力平台的崛起,终究要回归产品层面的两大核心拷问:其一,能否实现性能与延迟的十倍跃迁?其二,能否构筑可积累、可演进的算力生态,支撑规模化商业落地?
Groq、鲲云科技等公开的基准测试数据已足以验证可重构数据流架构对第一个核心问题的回答:它确实带来了数量级的性能颠覆。
而随着DeepSeek-V4正式发布,数据流架构的天然优势进一步得到证实。这类架构的性能天花板,恰恰依托于更深、更复杂的计算流水线:流水线层级越长、数据链路依赖越繁复,数据流架构在指令级并行调度、细粒度数据局部性挖掘、异步执行隐藏访存延迟上的先天优势,就越能被发挥出来,性能增益也愈发显著。
然而,性能的突破只是入场券,生态的壁垒才是护城河。在被收购前,Groq通过Groq Cloud提供Token服务,其架构的通用性与生态的可积累性,外界难以窥探全貌。反观国内,鲲云科技CAISA系列芯片已覆盖2000余家生态客户,实现行业遍地开花。清微智能TX系列芯片亦规模落地。国内企业用商业进展回答第二个核心问题:可重构架构或可重构数据流架构,因为具备可重构能力,其算力平台具有积累生态的能力。
另一面,则是科技巨头对未来版图的精准收编。巨头们看重的不再只专注于短期的产品迭代,而更看重那些在长达十几年的孤独探索中沉淀下来的顶尖人才与底层技术专利。其中最具代表性的是Groq和SambaNova。
去年年底,英伟达掏出200亿美元天价,与Groq签订非独家授权协议,收编整个团队。Groq的技术已被整合进英伟达最新的Rubin平台,今年GTC大会上英伟达发布NVIDIA Groq 3 LPU,基于Groq 3的LPX机架预计将在今年下半年上市。

▲NVIDIA Groq 3 LPX机架系统(图源:英伟达官网)
同年10月,英特尔被传以16亿美元(折合人民币111亿元)收购SambaNova。今年2月尘埃落定,转向合作,整合英特尔至强处理器、GPU、网络与存储以及SambaNova系统,迎接推理机遇。
英伟达与英特尔相继向这两家新锐抛出橄榄枝,标志着行业双巨头在现有布局之外,再落一枚至关重要的差异化战略重子,直指持续爆发式增长的AI推理市场核心腹地。
而这,正是可重构数据流架构真正大展宏图的主场。
两类企业路径各异,却在时代浪潮下殊途同归:一方以规模化落地让技术红利普惠产业,一方以巨头生态融合让前沿创新深度扎根。二者相向而行,共同将可重构数据流计算架构推向全新的历史高度。
在这场波澜壮阔的技术变革中,陆永青院士创立的定制计算实验室从学术探索走向工程实践,再经由鲲云科技等企业推向产业规模化落地。这一路演进,中国学者和芯片企业走出了一条自主可控、全球引领的差异化突围之路,为中国在下一代智能计算架构竞争中抢占了宝贵的战略先机。
05.
结语:三十载潮涌
中国芯的未来
不同于“中国英伟达”式的追赶叙事,可重构数据流这类专注于底层创新的架构,在早期曾经历漫长的沉寂与不被理解。国内首批AI芯片企业几乎同期而立,在英伟达笼罩行业的八年阴影里坚守深耕,直至2025年前后才迎来资本化加速。一路走来,它们始终直面创新者的终极拷问:如果路线不及巨头,凭何争锋?如果路线足以颠覆格局,为何巨头未曾布局?
八年后,黄仁勋在GTC大会上亲自发布Groq 3 LPU,给出了答案。
更具时代意义的是,当全球产业界重新审视可重构数据流架构时,中国团队已在这一领域深耕三十余年——从帝国理工的源头实验室到中国的产业化落地,技术创新的源头与产业化主阵地,正在发生历史性的位移。

这一位移并非偶然。回顾中国芯片产业三十年,从"市场换技术"的合资模式,到"跟随式创新"的追赶叙事,底层架构的“从0到1”始终是最难的命题。可重构数据流架构的突围路径提供了另一种可能:当学术源头、工程验证、产业化形成完整链条,且核心团队始终主导技术演进时,中国首次在计算架构的"无人区"拥有了与硅谷同步创新、甚至局部领先的能力。其所讲述的也不再是“中国英伟达”或“中国Groq”故事,而是在全球范围内进行源头创新的“中国源头故事”。
八年前,当这一赛道尚处蛮荒、巨头尚未入局时,深圳的产业生态为这场"源头创新"提供了关键土壤——完整的电子产业链降低了流片门槛,丰富的应用场景加速了技术验证,而敢于在“无人区”下注的资本与政策环境,则让长周期创新成为可能。
从“海外技术输入”到“本土创新输出”,下一代计算架构的主阵地转移,本质上是一场关于"创新生态"的长期主义胜利。
接下来,让我们拭目以待。
