鹭羽 发自 凹非寺
量子位 | 公众号 QbitAI
Scaling即正义?智谱挠了挠头——
很痛苦,而且压力山大……

智谱最新发布的一篇技术博客,画风稍微有点不一样:
没有过去的硬核技术输出,反而大倒苦水从GLM-5以来的各种花式踩坑,官方称之为「Scaling Pain」。
我们的推理基础设施正承受着前所未有的压力,每天都要服务数亿次Coding Agent调用。
过去几周,一些用户在使用GLM-5系列模型执行复杂Coding Agent任务时,遭遇多种异常,比如乱码、复读和罕见字符生成。
而且这些问题在标准推理环境中压根复现不出来!!!

排查数周,团队终于揪出真凶,彻底戳破Scaling Laws路上的隐形Bug。
不仅详细总结了自身遭遇的昂贵教训,还给出了一套极具实操性的避坑指南。
简单来说,如果屏幕前的你正打算给自己的Agent加码,那么这篇来自一线实战的经验总结,建议先反复阅读背诵~

定位关键Bug
事情是酱紫的——
自从GLM-5发布以来,智谱通过观察用户的大规模Coding Agent推理过程,发现了三类异常现象:
乱码输出:内容杂乱无意义;
重复生成:模型不断重复输出相同内容;
生僻字:出现异常字符。
这引起了团队工程师的警觉,于是说干就干,先是通过本地回放用户反馈,重复运行相同请求数百次,结果始终无法触发异常。
换言之,模型本身并非根本原因。
在进一步模拟在线环境后,团队尝试调整PD分离比例并持续提高系统负载,异常现象终于得以复现,在每10000个请求中大约能复现出3-5个异常输出。
这说明,异常现象很有可能出自高负载下的推理状态管理,指向底层推理链路。
但同时也引出了另一个问题,线下的复现率仍低于用户线上反馈的频率,这就意味着现有的检测方法存在遗漏或触发条件尚未完全覆盖。
于是智谱团队继续对异常输出的检测方法进行优化。他们发现投机采样(Speculative Decoding)指标可作为异常检测的重要参考。
投机采样原本用于提升模型推理性能,它先由小模型生成草稿(draft tokens),再由大模型验证是否接受这些token,最终能够在不改变输出分布的情况下提升decode效率。
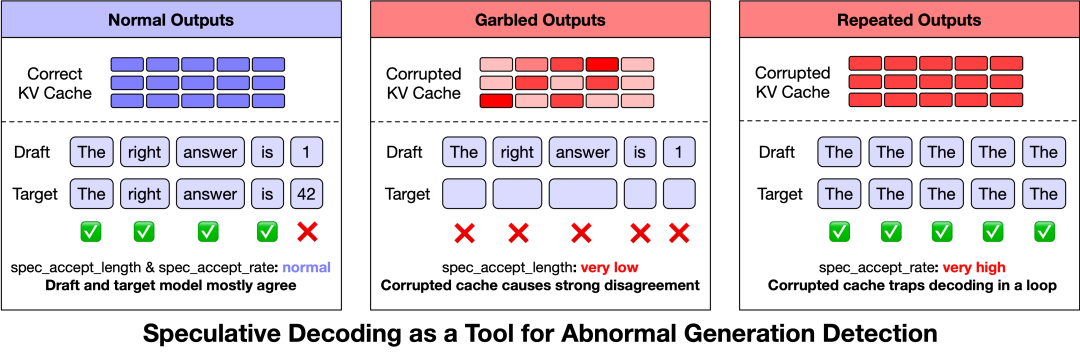
而在GLM-5的三类异常中,乱码和生僻字的spec_accept_length非常低,也就是说目标模型的KV缓存状态与草稿模型之间存在明显不匹配。
复读则拥有过高的spec_accept_length,表明损坏的KV缓存可能导致注意力模式退化,将生成过程推向高置信度的重复循环。
基于以上观察,智谱总结出了一套在线异常监控策略:
当spec_accept_length持续低于1.4且生成长度超过128 token,或者spec_accept_rate超过0.96,系统就会主动中止当前生成,并将请求重新交回给负载均衡器。
紧接着,智谱开始进一步解析异常原因:
PD分离架构下的KV Cache竞态
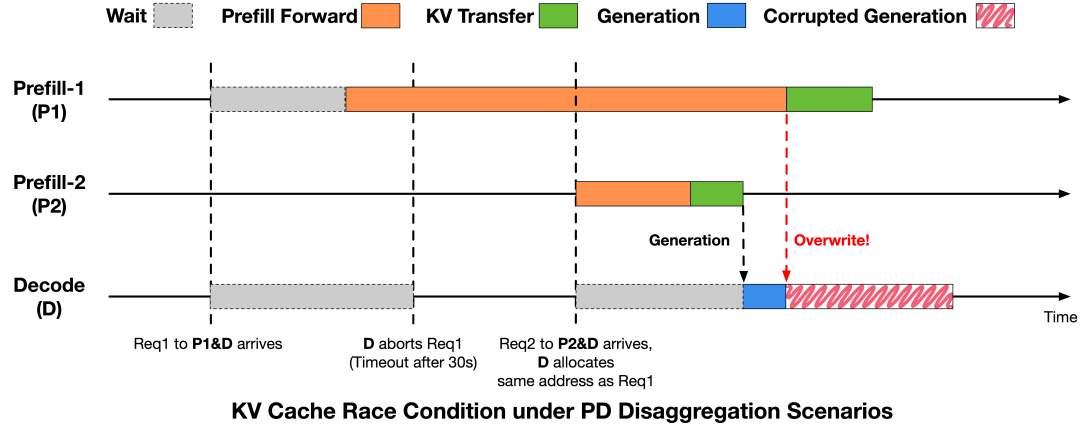
团队通过分析请求生命周期和推理引擎中的PD分离执行时序,将问题归因于请求生命周期与KV Cache回收与复用时序之间的不一致,从而引发的KV Cache复用冲突。
为了消除这类竞态情况,研究人员在推理引擎中引入了更为严格的时序约束,会在请求终止和KV Cache写入完成之间建立显式同步。
具体来说,在发出中止指令后,解码阶段会向预填充阶段发送通知。预填充阶段只有在满足以下任一条件时才会返回安全回收信号:未启动任何RDMA写入,或所有先前发出的写入操作已完全完成。而解码阶段只有在收到此确认后才会回收并重用相应的 KV Cache槽位。
该机制将确保KV Cache写入不会跨越内存复用边界,从而避免跨请求的KV Cache损坏。
最终修复该bug后,异常输出的发生率从约万分之十几下降至万分之三以下。
HiCache加载时序缺失
此外,当KV Cache换入与计算重叠时,当前实现未能保证数据在使用前已完成加载,导致可能出现未就绪KV Cache被访问的情况。
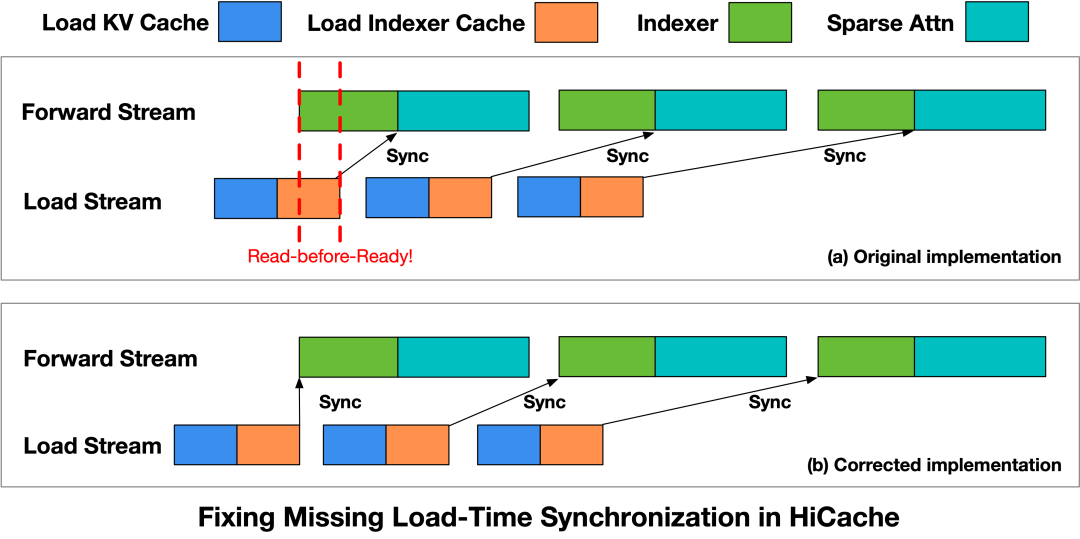
为解决这一问题,团队重构了HiCache读取流程,同时引入数据加载与计算之间的显式同步约束。
在启动Indexer算子之前,先插入一个Load Stream同步点,确保相应级别的Indexer缓存已完全加载。Forward Stream只有在数据准备就绪后才会进行计算,从而消除了read-before-ready的问题。
应用此修复后,在相同的工作负载条件下,由执行时序不一致引起的异常被消除,系统终于得以稳定。
Prefill侧优化
事实上,这两种Bug都指向了同一个常见的系统瓶颈:
在长上下文的Coding Agent Serving任务中,Prefill阶段已经成为影响系统性能的主要因素。
于是为了缓解Prefill阶段在高并发下的内存和带宽压力,团队另外设计了KV Cache分层存储方案——LayerSplit。
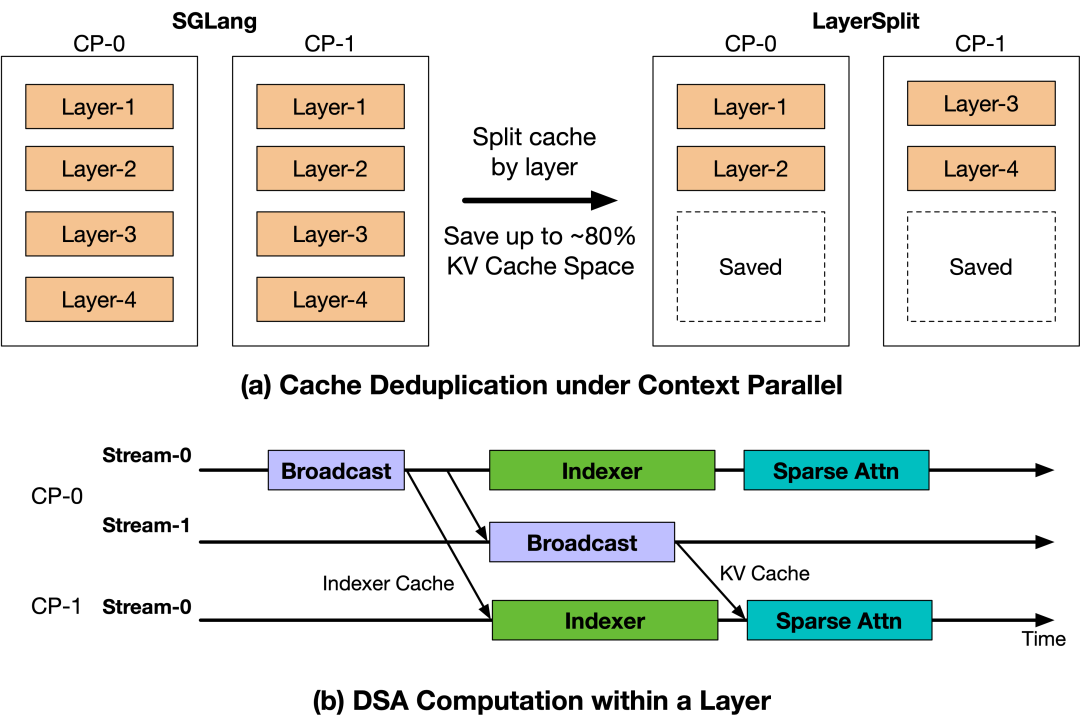
在该方案中,每个GPU只存储部分层的KV Cache,显著降低了每个GPU的内存占用。然后在执行Attention计算前,将对应层的KV Cache广播给其他相关rank。
为了降低通信开销,还进一步设计有KV Cache广播与indexer计算的重叠机制,将通信延迟隐藏在计算过程中。这样唯一的额外通信开销就来自Indexer Cache的广播,其大小仅为KV Cache的八分之一,整体通信成本可以忽略不计。
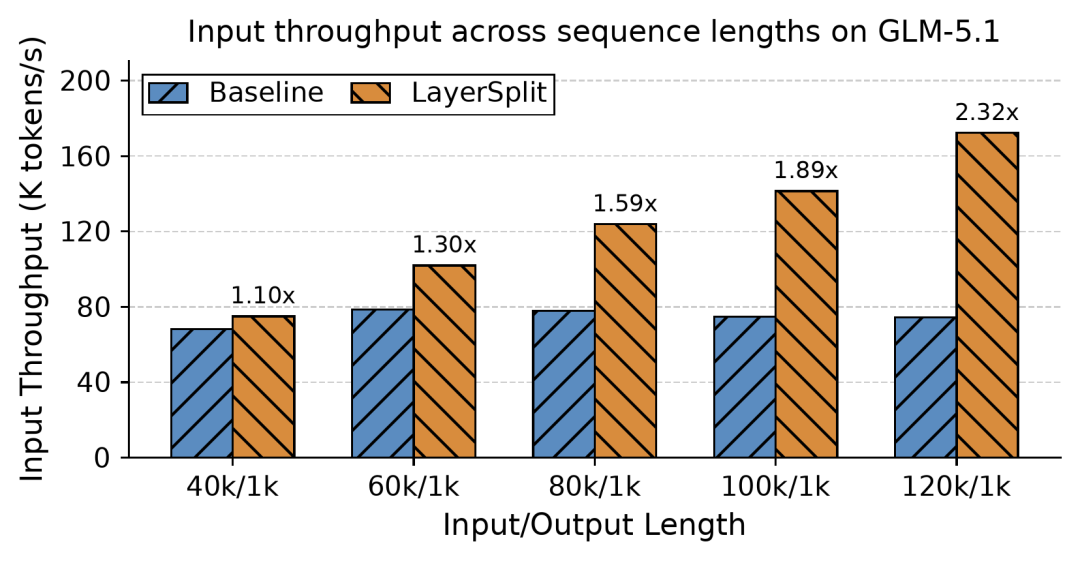
团队将LayerSplit和GLM-5.1结合发现,在Cache命中率达到90%、请求长度在40k到120k区间内时,系统吞吐量提高了10%到132%,且随着上下文长度的增加,收益也随之增长。
总体而言,该优化显著提升了系统在Coding Agent场景下的处理能力。
同时智谱也认为,当智能真正进入高并发、长上下文的Coding Agent场景后,维护推理基础设施的输出质量变得至关重要。未来大规模AI需要的不仅是Scaling Law推动的能力增长,还必须有等量级的系统工程支撑。
