月之暗面发布了Kimi K2.6,这也是杨植麟的第一个X.6版本。
虽然版本号上只加了0.1,但这不是一次普通的版本更新。
K2.6能在单个工程任务中持续12小时、发起4000多次工具调用;在Agent Swarm场景中,官方称其可横向扩展到300个子agent、4000个协调步骤。
它开始真正“做事”了。
更有意思的是,就在K2.6发布前几天,月之暗面开始急招推理平台工程师,学历要求只有“本科”。
3月份招Coding agent工程师时,更是打出“不限学历”的旗号。
这个博士密度极高、论文产出如流水的头部AI公司,为什么突然降低学历门槛?
答案就藏在K2.6里。
01
K2.6到底有多能干?
官方披露了两个工程案例。
月之暗面的工程师让K2.6在Mac上部署Qwen3.5-0.8B模型,并用一门非常小众的编程语言Zig,来优化推理性能。
结果呢?K2.6跑了12个小时,发起了4000多次工具调用,迭代了14个版本,最终把推理速度从15 tokens/秒提升到193 tokens/秒,比LM Studio还快20%。
但这不是重点,重点在于,从来没有人教过K2.6怎么用Zig。都是它自己学的。
另一个案例更夸张。
K2.6接手了exchange-core,一个有8年历史的开源金融撮合引擎。这个引擎已经被优化到接近性能极限,但K2.6还是找到了突破口。
13个小时,1000多次工具调用,4000多行代码修改。K2.6像一个经验丰富的系统架构师,分析CPU火焰图、定位内存瓶颈、重构线程拓扑。最后,它把中等吞吐量提升了185%,性能吞吐量提升了133%。
这不是在做题,这是在解决真实的工程问题。
K2.6的能力可以归纳为四个方向,但每一个方向都不是简单的“更强”。
第一是长周期编码。
以前的AI写代码,基本上是“一次性交付”。你给它一个需求,它写完代码就结束了。但K2.6不一样,它能持续工作十几个小时,自己读文件、跑测试、看报错、改代码、再测试,一直循环到任务完成。
它能跨语言泛化,Rust、Go、Python都没问题。它能处理不同领域的任务,前端、DevOps、性能优化都能搞定。
企业测试的反馈很直接。Blackbox.ai说:“K2.6为开源模型树立了新标准,尤其是在长周期、agent风格的编码工作流中。”Factory.ai的内部测试显示,K2.6比K2.5提升了15%,指令遵循更好,推理更彻底,编码错误更少。
第二是代码驱动的设计。
你给K2.6一个简单的提示,比如“做一个科技公司的落地页”,它不只是生成HTML和CSS,它会给你一个完整的前端界面,包含结构化布局、精心设计的首屏、交互组件、滚动触发的动画效果。
更厉害的是,K2.6已经不满足于做静态前端了。它开始做简单的全栈应用,从用户认证到数据库操作,轻量级的场景它都能搞定。
月之暗面建立了内部的Kimi Design Bench,分为视觉输入任务、落地页构建、全栈应用开发、通用创意编程四个类别。K2.6在这些类别中的表现,已经可以和Google AI Studio掰手腕了。
第三是agent群体协作。
K2.5的Agent Swarm已经很强了,能协调100个子agent、执行1500个步骤。但K2.6直接把规模扩大到300个子agent、4000个协调步骤。
这不单纯是数量上的堆叠。
K2.6能让不同的agent发挥各自的专长:有的负责广泛搜索,有的负责深度研究;有的分析大规模文档,有的负责长篇写作;有的生成文档,有的生成网站,有的生成幻灯片,有的生成电子表格。
这些agent在K2.6的协调下,形成了一个整体。
举个例子。
你给K2.6上传一篇高质量的天体物理学论文,它能把这篇论文转化为一个“技能”。
提取论文的推理流程、可视化方法、写作风格。然后,它能基于这个技能,产出一篇40页、7000字的新论文,外加一个包含20000多条记录的数据集,以及14张天文级图表。
第四是主动式agent。
K2.6不再是传统的那种,只有你发了指令它才会行动的工具,K2.6开始主动工作了。
月之暗面的强化学习基础设施团队做了一个实验,让K2.6支持的agent自主运行5天,负责监控、事件响应、系统操作。
结果这个agent从告警到解决,全程自己搞定,不需要人工介入。
K2.6在OpenClaw和Hermes Agent这样的持久化agent平台上表现出色。它能跨多个应用程序持续运行,7×24小时执行任务,主动管理日程、执行代码、协调跨平台操作。
月之暗面建立了内部的Claw Bench,覆盖编码任务、即时通讯生态系统集成、信息研究与分析、定时任务管理、内存利用五个领域。在所有指标上,K2.6的任务完成率和工具调用准确性都显著优于K2.5。
在基准测试中,K2.6的评分就足以说明一切问题。
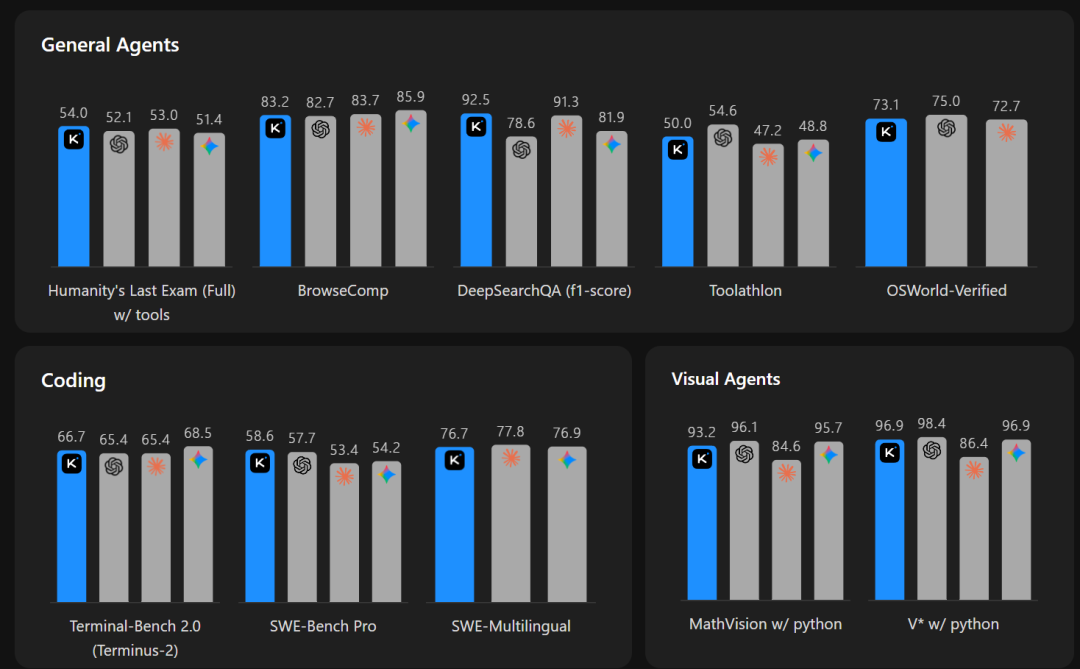
HLE-Full(带工具)得分54.0,超过GPT-5.4的52.1和Claude Opus 4.6的53.0。DeepSearchQA的F1分数92.5,准确率83.0。SWE-Bench Pro得分58.6, SWE-Bench Verified达到80.2。
02
月之暗面也想要一个郭达雅
就在几天前,月之暗面开始急招Kimi Code平台推理工程师。这个岗位的学历要求是“本科”,补充一点,图片中这个“7年”经验是招聘发起者自己打错了,实则为“3年”。

在这个博士学历云集、论文产出如流水的头部AI公司里,竟然会急招一个本科学历的推理平台工程师。
更有意思的是,3月份月之暗面招Coding agent工程师时,更是打出“不限学历”的旗号。
这不是HR写错了要求。AI竞争的主战场,正在从实验室的算法创新,转移到代码智能和agent这样,生产环境的工程落地。
你说这不巧了吗,3月份从DeepSeek离职,4月份加入字节的郭达雅,他最擅长的正是agent和代码智能。
月之暗面也想要一个郭达雅吗?
可能不止于此。月之暗面想要的,是一个完整的agent生态。
当模型公司开始从论文、榜单、聊天框走向自动写代码、自动调用工具、自动完成任务时,瓶颈不再只是算法,也可能是工程师手里的网关、路由、限流、日志和成本表。
推理平台工程师到底是做什么的?
这个岗位的核心业务,是为agent搭建稳定、可观测、成本可控的模型调用基础设施。
具体来说,就是在模型和应用之间建一套调度系统,让几十上百次的模型调用能稳定跑起来,成本可控,出问题能查。
工作内容包括这么几块。
第一是模型网关。
agent调用模型时不是直接访问模型API,而是通过网关统一管理。网关负责请求分发、协议转换、认证鉴权,还要处理不同模型提供商的接口差异。月之暗面已有K系列模型,但Kimi Code这类平台仍需要多provider适配。
第二是多模型路由。
不是所有任务都需要最强的模型。简单的代码补全用轻量模型就够了,复杂的架构设计才需要重模型。
路由系统要根据任务类型、上下文长度、响应速度要求,自动选择合适的模型,避免出现高射炮打蚊子这样的情况。
这需要你得了解不同的模型,知道它们完成不同任务的成本分别是多少,也需要实时的性能监控和动态调整。
第三是成本控制。
推理模型的token消耗是普通模型的数倍。
比如OpenAI的o1系列,它的reasoning_tokens可能是output_tokens的10多倍。这些内部推理标记虽然不返回给用户,但算力也被消耗掉。
如果没有精细的限流降级、token用量统计分析,成本会失控。你需要设计配额系统、优先级队列、降级策略,保证核心业务不受影响的同时控制成本。
第四是链路管理。
就跟快递一样,货物到哪了,你得能在APP上查到。
当一个agent任务涉及几十次模型调用、几十次工具调用时,就得追踪好调用链路上的每一环。
用户说“帮我修这个bug”, agent可能读了十几个文件、调了五次模型、跑了三次测试,最后失败了。你需要知道是哪一步出了问题,是模型推理超时、工具调用失败、还是上下文窗口溢出。
传统的日志系统很难追踪这种复杂链路,需要专门为agent设计的分布式追踪、性能监控、异常告警系统。
第五是状态管理。
之前模型推理是没有状态这个概念的。传统的对话场景很简单,用户输入一句话,模型返回一段文字,一次请求就结束了。
但agent不同,它需要进行多轮推理链,一个任务可能触发几十甚至上百次模型调用。
所以进入了agent时代,AI需要记住状态的不是模型本身,而是围绕模型搭建的agent runtime。平台要记录任务进度、工具调用结果、中间产物和失败现场,并在下一次模型调用时把必要上下文重新组织进去。
早上8点我给模型安排了一个任务,下午我再看这个模型的时候,它就应该是执行过任务的模型。那么任务执行的结果、执行了多少次等信息,就是模型的状态。
那又是为什么这个技术岗位的学历门槛只有本科呢?
杨植麟心里明白,如今的月之暗面不缺能开发算法的博士,事实上“高学历”对于月之暗面来说不是什么稀缺玩意,相反,能把推理能力工程化、产品化的人才是。
招聘简介里强调“能在需求还不明确的时候自己判断该做什么”、“还在一线写代码”,这种人才在传统互联网大厂的基础架构团队里有,在AI公司里却是稀缺的。
17岁的高中生陈广宇曾以实习生身份加入Kimi,并成为《Attention Residuals》的共同一作;4月初,Kimi又推出“穿越计划”,尚未毕业的实习生只要通过3到6个月考察,就能提前拿到正式Offer和期权。
一个博士密度极高的模型公司,开始把高中生、在校生纳入核心人才池,本质上说明AI公司的用人逻辑变了。
学历仍是信号,但不再是门票。
真正值钱的是能不能在实际问题里证明自己的价值。
最具代表性的是月之暗面在今年3月份发布的那个“不限学历”的Coding agent工程师岗位。

那张招聘海报上写着:“熟悉Claude Code、Cursor、Codex、Cline等代码辅助工具,越多越好;能源源不断地说出Codex比Claude Code垃圾在哪里;能源源不断地说出Claude比GPT-5垃圾在哪里。”
月之暗面要的不是论文作者,他们要的是真正用过这些工具、知道坑在哪里、能快速迭代产品的工程师。
月之暗面急需这样的人,因为他们的模型能力已经到位。
然而要让这些能力真正支撑起大规模agent应用,基础设施是瓶颈。当Anthropic的Claude Code上线不到一年ARR就达到25亿美元时,杨植麟看到的是一个信号。
下一个阶段比的不只是谁的模型参数更多、benchmark分数更高,比的是谁能让这些能力稳定、高效、低成本地服务于真实业务场景。
这是一个从0到1构建新基础设施的机会,也是推理计算时代的新职业方向。当AI公司开始为“本科学历”的工程师开出有竞争力的薪资和期权时,说明整个行业的重心正在转移。
从实验室到生产环境,从论文到产品,从算法创新到工程落地,这条路上需要的不只是能发顶会论文的博士,也需要能把系统跑起来、让用户用得爽的工程师。
03
月之暗面的深层逻辑
把这些线索串起来,月之暗面的战略路径很清晰。
第一层是模型能力,K系列模型覆盖通用、推理、代码三个方向。
第二层是工程化,推理平台让模型能力可规模化调用。
第三层是生态,开放API,让第三方基于Kimi构建产品。
这条路在国外是走不通的,企业级AI和开发者工具市场已经被Anthropic、OpenAI、Google等公司高度挤压,后来者很难再用同样路径打开局面。
可是在国内,情况刚好相反。C端产品的竞争已经白热化,豆包、元宝、千问,每家都在烧钱拉用户。但B端市场,尤其是开发者工具市场,还有巨大空间。
于是月之暗面选择了两条腿走路。
一方面学Claude Code,自己做编程工具Kimi Code,这是直接面向开发者的产品。
另一方面又让自己的模型适配Claude Code,通过API的方式让第三方工具调用Kimi的能力,这也是为啥K2.6这么强调agent和代码能力。
从技术演进的角度看,这是非常合理的。
AI行业正在从“模型创新驱动”转向“工程化落地驱动”。继续卷基座模型,比谁的性能更好,可普通用户已经感受不到差异了。
关键问题从“模型够不够聪明”变成了“能不能帮我把事儿做成”。
这就需要agent能力,回归到代码智能的基本功上。
代码任务和普通聊天不同,普通聊天很难判断对错,但代码有天然的verifier。
能不能编译、单测过不过、CI是否失败、bug是否复现、benchmark是否提升、diff是否合理,这些都是客观的评价标准。
用户每一次让agent改代码,都会产生高价值轨迹。
读了哪些文件、用了哪些工具、哪里报错、怎么修复、测试结果如何。这些轨迹可以反过来做eval、SFT、RL、拒答策略、工具调用训练。
这就是为什么所有大厂都在抢代码智能这个赛道,擅长agent和代码智能的郭达雅也因此变得人人都在疯抢。

不只是因为开发者市场有付费能力,更是因为代码任务能够形成训练闭环。
在合规授权、脱敏和企业协议允许的前提下,用户的每一次使用,都会让这些轨迹可以反过来成为eval、SFT、RL和工具调用训练的材料。
这种飞轮效应一旦启动,会形成强大的竞争壁垒。先发优势会越来越明显,后来者很难追赶。
月之暗面看到了这一点,所以他们在急招能“做过基础设施”、“还在一线写代码”的工程师。这不只是填补团队空缺,而是在抢占一个战略窗口期。
2026年是推理模型从实验室走向大规模应用的转折年,谁能先把推理能力工程化、让开发者用得爽,谁就能占据生态位。
技术能力只是一方面,时间窗口更关键。
国内市场的竞争更加激烈。
智谱的GLM-Code、阿里的通义灵码、字节的豆包代码助手,每家都在投入重兵。而就在这个节骨眼上,郭达雅从DeepSeek离职,加入字节跳动Seed团队,担任agent方向负责人之一。
这个消息在AI圈引发震动,不只是因为他的技术能力,更是因为他的技术标签太精准了,直接暴露了字节整个2026年的战略方向。
郭达雅是代码智能与大模型推理方向的顶尖人才。
从毕业到进入DeepSeek,郭达雅做的是一套可以迁移、可以复用的技术体系。
代码能力可以迁移到数学推理,数学推理的训练方法可以迁移到通用推理和agent,这种技术迁移能力正是字节,乃至所有国内AI大厂都需要的。
字节在多模态领域全球领先,Seed 2.0的视频生成能力有目共睹。
但在数学推理、代码智能和agent能力上,字节落后于ChatGPT和Claude这样的竞品。
2026年启动agent与Coding组织整合,梁汝波明确将AI模型能力列为战略重点。郭达雅的加入,补齐了字节在代码与推理方向上的关键拼图。
此前有报道称,郭达雅早在去年10月便已产生离职意向,其关注重点在agent方向,而当时该方向在DeepSeek内部优先级相对有限。
在后续去向选择中,阿里曾较早与其接触,提供的岗位是后训练负责人,管理范围更大,且在工作地点与现金待遇上具备一定吸引力。
不过最终促成其加入字节Seed团队的关键因素,仍然是在研究方向本身。
字节承诺郭达雅,将agent视为字节的核心方向之一,不仅在模型能力演进中强化agent能力,也在产品侧加速相关形态落地。
对于这个逻辑,月之暗面只会看得比我更透彻。
这种急迫不只是人才竞争的压力,更是战略窗口期的焦虑。2026年到2027年,可能是agent基础设施格局确定的关键时期。
谁能在这个时间窗口建立起稳定的推理平台、吸引到足够多的开发者、形成数据飞轮,谁就能在接下来的竞争中占据主动。
我承认有些标题党,月之暗面可能并不需要“郭达雅”这个人,但是他的技术标签“代码智能和推理能力”,绝对是月之暗面现在最渴望的。
在AI竞争的下半场,能把模型能力变成稳定服务的工程师,它的作用可能和能发顶会论文的博士一样重要。
