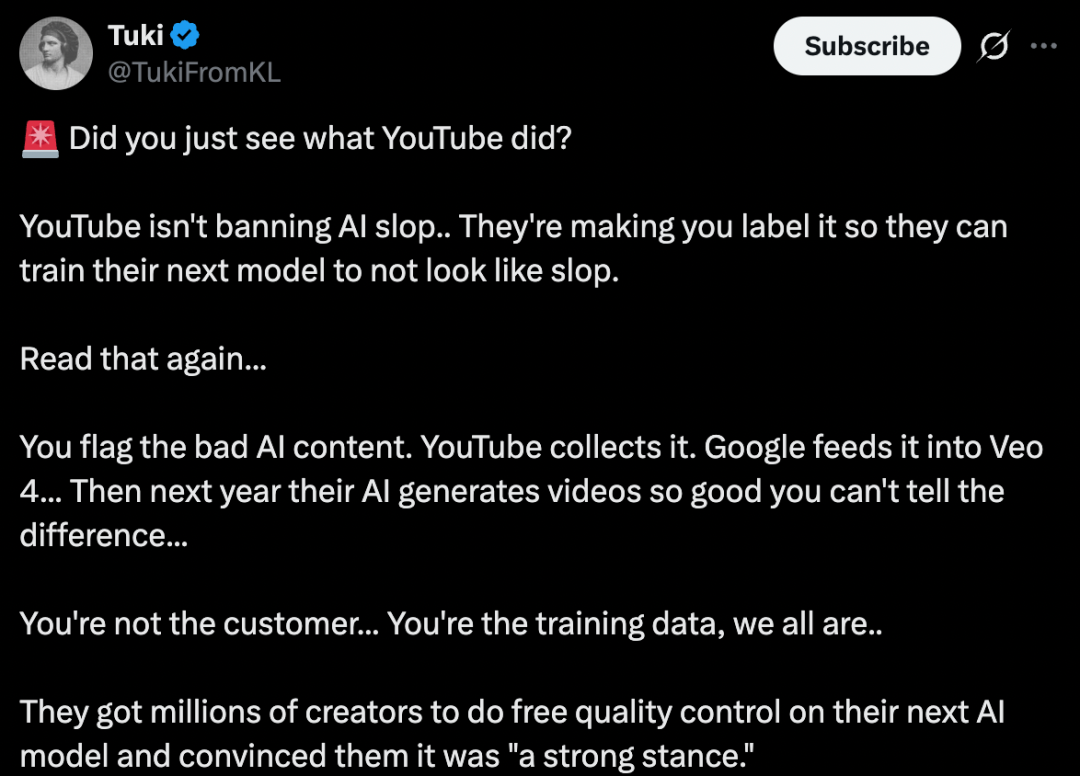
最近,YouTube 向用户发起调查:你刚刚看的这个视频,有没有「AI 烂片」的感觉?
评分从「完全没有」到「极其明显」,由用户自行判断。
官方的解释是,平台希望借此打击泛滥的低质量 AI 生成内容。
消息一出,有人拍手叫好,认为 YouTube 终于出手整治乱象。

有人则认为表面是举报 AI 烂片,实际上在帮谷歌训练下一代 AI。

YouTube 每天有 1.22 亿活跃用户。当这些人开始对 AI 视频逐一打分,他们实际上是在告诉系统,哪些画面、哪些动作、哪些细节,会让人一眼识破这是 AI 生成的。
这批数据,恰好可以直接用于训练谷歌旗下的 AI 视频生成模型 Veo,让下一代模型知道哪里「露馅」了,从而生成更难被肉眼分辨的视频。
与此同时,谷歌还向一家专门为儿童制作 AI 视频内容的初创公司投资了 100 万美元。

事实上,这家公司已做了同样的事情整整十五年。
每当我们打开浏览器、登录银行账户或是在网购平台下单,屏幕上总会跳出一个熟悉的小方框,要求点击几张图片,或是在一个勾选框旁边打上对勾。
我们以为这只是一道防止机器人入侵的安全关卡,实则在那短短十秒钟里,我们正在为一家市值数百亿美元的科技巨头,无偿完成一项极具商业价值的工作。
这套系统叫做 reCAPTCHA,它是互联网史上规模最大、也最鲜为人知的数据采集行动。
那道「验证码」,从来都不只是验证码
故事要从 2000 年前后说起。
彼时,垃圾邮件机器人正在席卷互联网,论坛被大量刷帖,用户收件箱被塞满无用信息,各类网站急需一种方法来区分真实的人类用户与自动化程序。
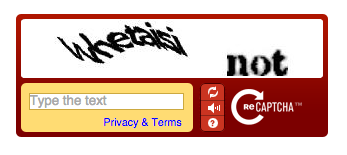
卡内基梅隆大学教授路易斯・冯・安发明了 CAPTCHA,这是一种将文字扭曲变形、只有人类才能辨认的图形验证码。
冯・安意识到,每天有数以百万计的人在这些验证码上消耗认知精力,如果这些精力能被同时引导去做另一件有价值的事,会怎样?
2007 年,他推出了 reCAPTCHA。
验证码不再显示随机乱码,转而呈现来自真实书籍的扫描图像,那些计算机尚无法自动识别的古旧文字。用户每完成一次验证,就等于帮助完成了一小段古籍的数字化。这些书来自《纽约时报》历史档案与谷歌图书项目,总量超过 1.3 亿册。
2009 年,谷歌收购了 reCAPTCHA。真正大规模的数据采集,就此开始。
到 2012 年前后,辨认扭曲文字的时代走到了尽头,谷歌有了新的需求。
谷歌的街景采集车正在将地球上的每一条道路拍进镜头,然而原始照片只是数据。要让 AI 真正读懂这些图像,就必须知道画面里哪里是红绿灯、哪里是人行横道、哪里是店面招牌。
这一过程在机器学习领域叫做「数据标注」,是训练计算机视觉模型不可缺少的环节,也是一项造价高昂的工程,行业市价通常在每小时 10 至 50 美元之间。
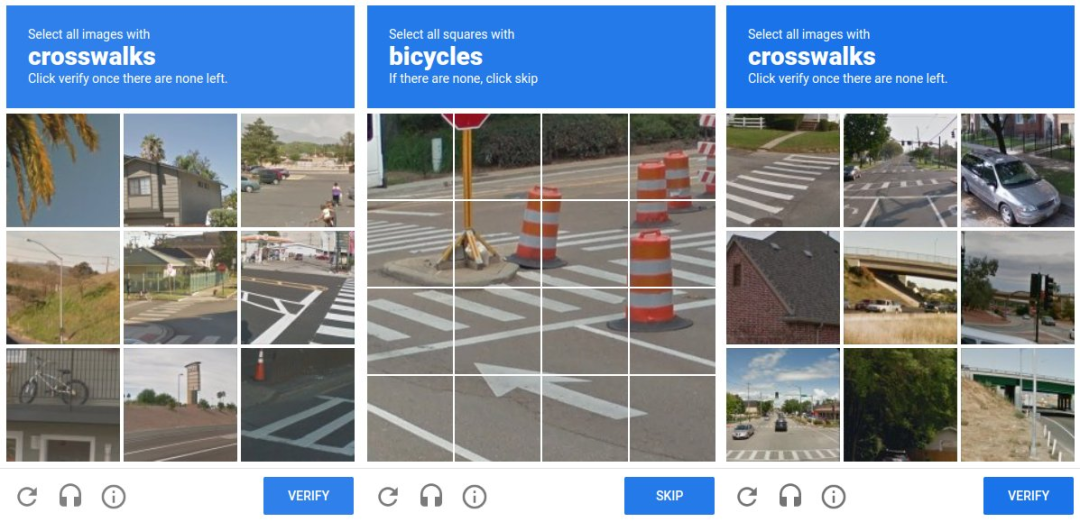
谷歌就把标注任务嵌进全球每个人每天都绕不开的东西里。reCAPTCHA v2 改变了界面,用户面对的是一组来自谷歌街景的真实照片,被要求「点击所有包含红绿灯的方块」,或「选出每一处人行横道」。
看起来仍是一道安全验证,背后的每一次点击,都是在为谷歌的计算机视觉模型打上精确的训练标签。
巨大的规模
鼎盛时期,全球每天有 2 亿个 reCAPTCHA 被完成,每次耗时约 10 秒,折合每天超过 50 万小时的人工劳动。按数据标注行业最低市价估算,谷歌每天从中获取的免费劳动价值高达 500 万美元。
reCAPTCHA 几乎无处不在,每一家银行、每一个政务平台、每一个电商网站,都将它嵌入了登录入口。用户根本没有绕行的余地,想访问自己的账户,就必须先完成标注。
这种强制性,是其他任何数据采集方式都无法企及的。Scale AI、Appen 等专业标注公司雇用了数十万名工人,有时时薪不足一美元,但即便如此,也无法达到 reCAPTCHA 所覆盖的规模与密度。
这些数据最终流向了两款产品。
一是谷歌地图。作为全球使用最广的导航工具,它识别路牌、定位商家、理解城市地理的底层能力,有相当一部分建立在这些人工标注之上。而那些完成标注的人,大多只是想查一下账单余额,或是在网上下一张订单。
二是 Waymo。这是谷歌旗下的自动驾驶项目,2016 年独立运营。自动驾驶汽车要在真实道路上安全行驶,必须以近乎完美的精度识别红绿灯、行人、停车标志等数千种视觉信息,这些识别任务所需的核心训练数据,正是由数以百万计、对此毫不知情的普通用户通过 reCAPTCHA 完成标注的。如今 Waymo 估值 450 亿美元,2024 年完成超过 400 万次付费载客,仍在持续扩张。
2018 年,reCAPTCHA 推出第三个版本,这一次连验证题都消失了。系统在后台静默运行,追踪用户的鼠标轨迹、页面滚动速度和光标停留位置,通过分析这些行为模式来判断访问者是否为真实人类。这些行为数据,同样源源不断地流入谷歌的 AI 训练体系。
冯・安当年的构想,在某种程度上称得上是对人类认知资源的一次创造性调度,把人们原本就要花在垃圾过滤上的精力,引导去做一件真正有意义的事。这个出发点,本身并无恶意。
但有人认为,谷歌将一套用户别无选择、必须使用的安全机制铺设至整个互联网,而后将产出的海量数据悄然收割,转化为价值数百亿美元的商业产品。整个过程中,用户不仅一无所获,甚至连知情的权利都未曾拥有。
今天 YouTube 对 AI 视频打分这件事,似乎也是把用户自发的行为,包装成一项有益于平台生态的举动,同时将产生的数据悄悄收入囊中,用于喂养下一代商业产品。
