
编译 | 杨京丽
智东西4月17日报道,昨天夜间,Anthropic发布新一代旗舰大模型Claude Opus 4.7。
Anthropic发布新模型Claude Opus 4.7(图源:X)
该模型在高级软件工程方面相比Opus 4.6有显著提升,尤其在处理最复杂的任务时提升明显;高分辨率图像处理能力大幅提升,是此前Claude模型的3倍以上;此外,Claude Code还同步新增了/ultrareview代码审查命令,输入后会启动审查会话,逐行检查代码变更。
用户反馈称,他们可以放心地将最难的编码工作交给Opus 4.7处理。Opus 4.7能够严谨一致地处理复杂的长时间运行任务,精确遵循指令,并在汇报结果之前自行验证输出。
Opus 4.7今日起在所有Claude产品和API、Amazon Bedrock、谷歌云Vertex AI以及Microsoft Foundry上线。定价与Opus 4.6一致:输入每百万token 5美元(约合人民币34元),输出每百万token 25美元(约合人民币170.5元)。开发者可通过Claude API使用claude-opus-4-7。
不得不说,Claude最近更新实在是快,大家都跟不上了,网友在Claude的评论区下面刷起了表情包,“两眼一睁,Claude又更新了”。
网友评论Claude推文(图源:X)
测试中,Claude Opus 4.7在以下几个方面表现突出,显著超越Opus 4.6:
1、指令遵循。Opus 4.7在遵循指令方面有显著提升。以前的模型会宽松地解读指令或完全跳过部分内容,而Opus 4.7会按字面意思执行指令。用户应相应地重新调优提示词和应用框架。
2、多模态支持增强。Opus 4.7对高分辨率图像的视觉能力更强:它可以接受长边最高2576像素(约375万像素)的图像,是此前Claude模型的3倍以上。这为依赖精细视觉细节的多模态应用开辟了广阔的空间:比如用Agent操作电脑时识别密集的屏幕截图、从复杂图表中提取数据、以及需要像素级精度的设计工作等。
3、实际工作。除了在金融Agent评测中取得最优成绩外,Anthropic内部测试显示Opus 4.7是比Opus 4.6更有效的金融分析师,能产出更严谨的分析和模型、更专业的演示文稿,能做到更紧密地进行跨任务整合。Opus 4.7在金融、法律等领域的第三方经济价值知识工作评测GDPval-AA上也达到了最优水平。
4、记忆能力。Opus 4.7在使用基于文件系统的记忆方面更强。它能在长时间、多会话的工作中记住重要笔记,并利用这些记忆来推进新任务,从而减少对前置上下文的需求。
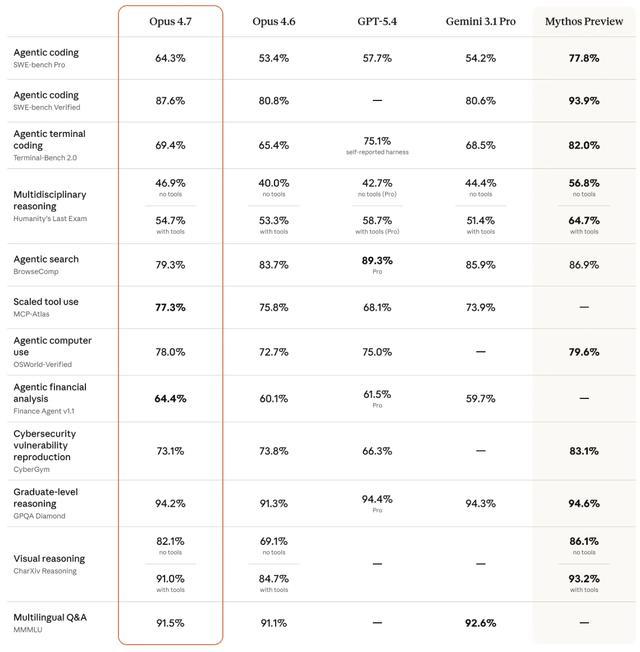
Opus 4.7模型基准测试表现(图源:Anthropic)
Opus 4.7获得了部分早期测试者的积极反馈。财务软件公司Intuit技术副总裁Clarence Huang称,该模型能在规划阶段自行发现逻辑错误,执行速度也远超前代。AI编程工具公司Augment Code的CTO Igor Ostrovsky则认为,Opus 4.7的优势在于它能处理好实际工作中的自动化流程、CI/CD(持续集成与部署)和长任务流程,且会主动给出自己的判断,而非一味附和用户。
Anthropic在预发布测试中,针对不同领域对Opus 4.7进行了测评,并对比了Opus 4.6、GPT-5.4和Gemini 3.1 Pro。
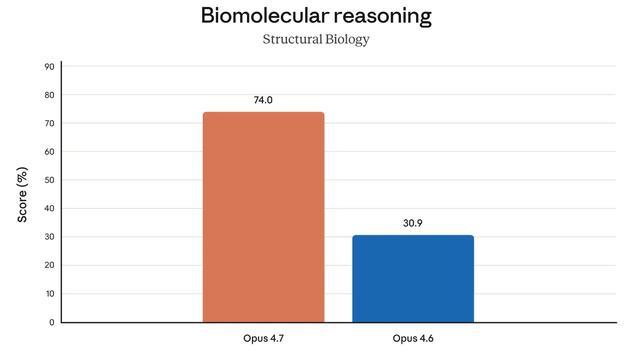
生物推理进步最为明显,Opus 4.7得分74.0%,Opus 4.6仅30.9%,提升了1.4倍。
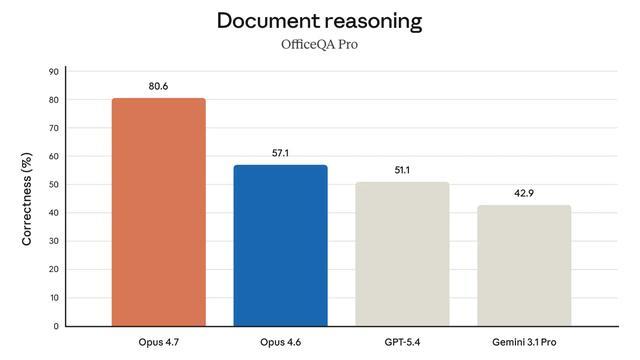
文档推理方面,Opus 4.7得分80.6%,远超Opus 4.6的57.1%,也大幅领先GPT-5.4(51.1%)和Gemini 3.1 Pro(42.9%),是横评中差距最明显的项目之一。
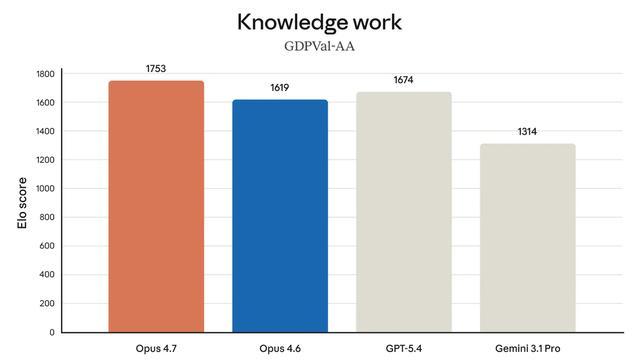
另外,知识工作方面,Opus 4.7以1753的Elo分数排名第一,领先明显,超过GPT-5.4(1674)、Opus 4.6(1619)、Gemini 3.1 Pro(1314)。
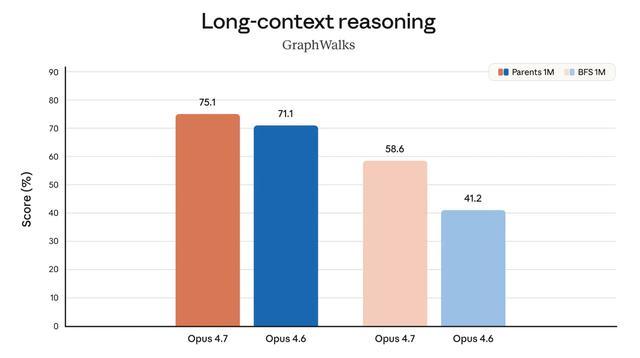
长上下文推理方面,在处理较简单的父节点查找任务(Parents 1M)时,Opus 4.7得分75.1%,Opus 4.6为71.1%,差距不大;但处理更难的广度优先搜索任务(BFS 1M)时,Opus 4.7得分58.6%,Opus4.6仅41.2%,拉开了17个百分点。越难的任务,模型提升效果越明显。
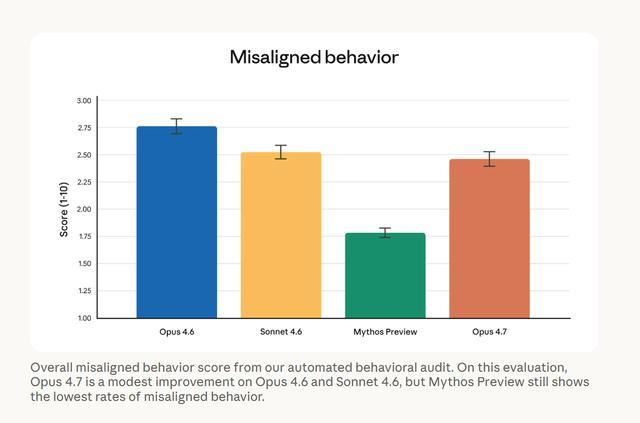
在安全与对齐方面,Anthropic还公布了各模型的错位行为评分。Opus 4.7的错位行为得分约为2.47(满分10分,越低越好),略优于Opus 4.6的2.75,但与Mythos Preview的1.78仍有明显差距。
总体而言,Opus 4.7 的安全性能与 Opus 4.6 相似,其出现欺骗、奉承和与滥用者合作等行为比例较低。Anthropic对此评价:“Opus 4.7总体对齐良好且值得信赖,但行为并非完全理想。”目前,对齐表现最好的Mythos Preview尚未全面开放。
三、其他更新:新增xhigh等级、审查命令,任务预算进入公测
除Opus 4.7本身外,Anthropic还同步推出了几项功能更新。
推理等级方面,新增xhigh(extra high)等级,介于现有的high和max之间,让用户在推理深度和响应速度之间有更细的调节空间。Claude Code的默认推理等级已提升至xhigh。
API方面,任务预算功能进入公测,开发者可以引导Claude在长任务中如何分配token消耗。
Claude Code方面,新增/ultrareview命令,输入后会启动一个专门的审查会话,逐行检查代码变更,并标记Bug和设计问题,Pro和Max用户各赠3次免费体验。此外,Auto模式扩展至Max用户,该模式下Claude可自主做出操作决策,减少人工确认中断。
四、当心Opus 4.7更费token,但生成质量更优
Opus 4.7是Opus 4.6的直接升级版,但有两个影响token用量的变化值得注意。
一是文本处理方式有更新,Opus 4.7相同输入消耗的token最多增加约35%;二是模型在较高推理等级下会进行更多思考,尤其在Agent场景的后续轮次中,Opus 4.7输出token也会相应增多。用户可以通过调整推理等级、设置任务预算,或在提示词中要求更简洁来控制用量。
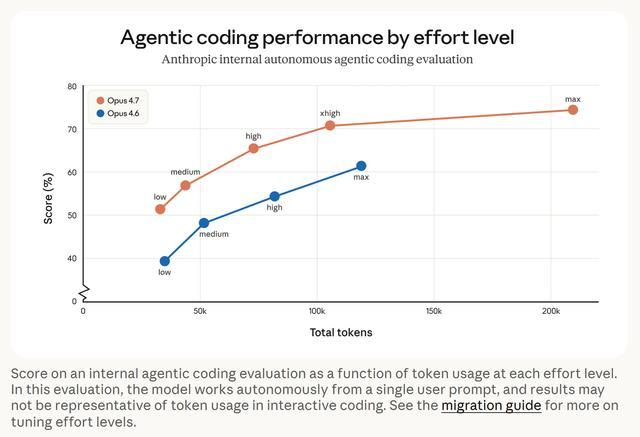
从Agent编程评测图表来看,Opus 4.7在每个推理等级上都以更少的token达到了更高的得分。例如Opus 4.7在xhigh等级下消耗约10万token,得分超过70%;而Opus 4.6在max等级下消耗约13万token,得分才刚过60%。不过,该评测中模型是根据单一提示自主工作,结果不一定能代表交互式编程中的实际token消耗。
从Anthropic公布的数据来看,Opus 4.7在编程、文档推理、生物推理等多个基准上的提升是实打实的,token效率也有所提升。但测评终归是测评,实际表现还需要在真实场景中进一步验证。
随着Opus 4.7的发布,OpenAI后续又会做出哪些新动作,大家期待已久的DeepSeek月底会不会发布新模型,大模型厂商的竞争可谓是越来越有意思了。
