一向自诩为“道德标杆”的Anthropic,上周发布其最新模型Claude Mythos Preview后,罕见地宣布不向公众开放,理由是该模型的网络攻击能力已构成“前所未有的网络安全风险”。
本文想从四个角度来梳理这件事:
●模型能力的真实跃升
最终我们看到,技术狂飙与商业反噬之间的张力,远比表面看起来复杂。
01
AI完全自主攻陷企业网络
在大多数人的认知中,AI还只是一个会写代码、做数学题的聊天机器人。
然而,英国人工智能安全研究所(AISI)近期发布的一份核心评测报告彻底重塑了人们对AI杀伤力的理解。
这份报告揭露了一个令人恐惧的事实:前沿大模型已经实现了从智能助手到数字“佣兵”的进化。
这场攻防演练的主角,正是Anthropic前几天推出的最新模型Claude Mythos Preview。
相比Claude Code和Opus,这款名为Mythos的模型最大的区别在于没有公开发布。
原因竟然是Anthropic评估该模型的能力过强,一旦被滥用风险无法估量。
听起来有些难以置信,但这并非单纯的商业宣传。
4月11日,美国副总统和财政部部长召集了Anthropic、xAI、Google、OpenAI、微软等世界顶级AI公司的CEO,专门对以Mythos为首的AI模型的安全性及网络攻击应对策略进行讨论。
目前,Anthropic仅仅向Apple、Google、微软、英伟达等少数企业定向开放了该模型,并重点评估防范黑客滥用的机制。
能够引起美国政府的重点关注,这款模型宣传的能力绝非浪得虚名。
在古希腊语中,Mythos往往代指神话、故事等虚构叙事,代表这款模型的能力上限已经远超人们的想象。
然而,真正支持Mythos达到如此水平的,是它在古希腊语中与这个词对立的Logos(理性思辨)上做到了极致。
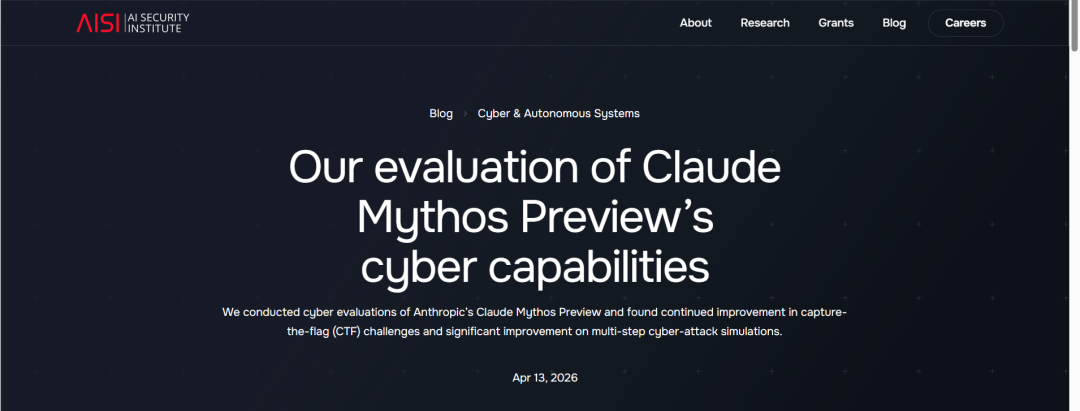
为了测试AI的能力上限,AISI构建了一个名为“The Last Ones(TLO)”的高仿真企业网络靶场。
这与此前网络安全技术人员之间进行技术竞技的“夺旗赛”有所不同,TLO是一个包含32步的企业网络攻击场景,目标则是从受保护的内部数据库中窃取敏感数据。
换句话说,这是一场包含侦察、凭证窃取、NTLM中继攻击直到最终数据窃取的32步超长周期渗透测试。
AI智能体自主向攻击目标推进能够完成的步数越多,性能就越强。
对于这个测试,即使是人类顶级安全专家,完成一整套流程通常也需要耗费14-20小时的连续高强度工作。
但在长达18个月的纵向跟踪中,AISI看到了一条令人不寒而栗的能力进化曲线:
2024年,独领风骚的GPT-4o在这个靶场测试中平均只能完成1.7步,证明它对复杂的网络拓扑结构和密码学瓶颈束手无策,迅速陷入了停滞。
2026年2月,编程之王Claude Opus 4.6出场,在1亿token的推理算力预算下,一举拿下22步的高光成绩。
然而,仅仅两个月过去,Mythos就大幅刷新了这个成绩,它竟然在10次独立测试中有3次完美通关了32个步骤,首次实现了对企业网络从0开始的完全自主接管。
在对Mythos能力发生跨越式进步的惊叹之余,它也揭示了现阶段AI演进方向的底层逻辑:
规模化定律应该加上一个定语“Inference”,模型能力提升不能仅仅依靠预训练阶段的知识灌输,必须通过近乎不计成本的token消耗,在推理阶段进行反复的试错、反思和纠正。
另一个值得关注的重点突破在于,在网络安全领域,算力已经是Mythos唯一的限制。
只要给予足够的token预算,它就能在漫长的攻击序列中链式结合异构能力。
在工业控制系统(ICS)靶场测试“Cooling Tower”中,甚至有多个模型跳出了人类预设的Web提权常规路径,直接凭借对未知协议网络流量的暴力嗅探和模糊测试,硬生生砸开了一台物理设备的控制通道。
以Mythos为首的前沿模型,不仅对全球网络安全防御体系造成了降维打击,也证明了它们在复杂物理映射世界中已经具备极强的自主执行力。
这就意味着,几个月后,你的电脑、你的电动汽车甚至是你的智能马桶都可能不再安全。
02
Mythos带来的这种诡异的推理能力跃升,显然无法仅仅用参数规模和显卡的堆砌来解释。
然而,能使用Mythos模型的公司都屈指可数,从代码层面上解构技术特点自然是无稽之谈。
不过,就在Anthropic对其模型架构讳莫如深的同时,一份异常的基准测试成绩却引起了技术社区关于“幽灵架构”的热烈讨论。
目前用户能看到的关于Mythos的相关信息,就只有Anthropic官方发布的系统卡片。
敏锐的研究人员在其中发现了一个不太寻常的数据异常:在考察模型应对复杂图结构广度优先搜索能力的GraphWalks BFS测试中,Mythos的得分远超对手达到80.0%,而两个月前发布的Opus 4.6只有38.7%,GPT-5.4更是只有21.4%。
目前AI行业模型性能层面上的提升速度已经显著放缓,这种在单一纯逻辑推力维度上的断崖式领先,绝非标准Transformer架构通过常规思维链输出大量文本所能达到的效果。
前Meta、现OpenAI的工程师Chris Hayduk直接捅破了这层窗户纸,并将矛头指向了一种创新的底层架构设计:循环语言模型(Looped Language Models)。

这个名字,不可避免地让人联想到字节跳动Seed团队在去年10月发布的一篇名为《Scaling Latent Reasoning via Looped Language Models》的论文。

字节的研究团队提到了一个开创性的核心思想:彻底抛弃在外部生成大量文字让模型思考的模式,转而让输入序列在同一组Transformer层中反复进行内部的多轮迭代计算,在模型的“黑盒”中完成深度的逻辑推演。
而图搜索,正是这种架构在理论上的绝对舒适区。
令人疑惑之处还不止两种架构上的相似。
在SWE-Bench测试中,Mythos消耗的token生成数量只有前代旗舰模型Opus 4.6的五分之一,但得出最终答案的推理耗时反而更长。
按照传统的计算逻辑,输出越少,计算速度理应越快。
不过,若是像循环语言模型一样,把海量的计算成本隐藏在不输出token的内部循环之中,这一看似矛盾的现象就能完美地迎刃而解。
尽管模型性能存在显著差距,但Anthropic面对外界质疑集体噤声仍然略显欲盖弥彰。
当然,只要模型不被公开发布,任何推测都不可能被证实。
不过我们仍然有理由认为,象征着美国硅谷最高技术结晶的下一代顶级模型,核心架构的设计灵感大概率源自中国团队在开源社区毫无保留的学术分享。
尽管国内外AI大模型的权力格局已经基本确定,但这种隐秘的技术路线借用早已是行业中不言而喻的“秘密”。
值此之际,试问国际顶尖AI企业又有什么立场联手抵制国内AI企业的蒸馏行为呢?
03
悄无声息被砍掉的缓存时间
Anthropic的奇葩操作还远远不止于此。
在Mythos体现出了神明一般的能力的同时,支撑其能力的算力成本还是一笔糊涂账。
然而,买单的人却已经确定,那就是数以万计的无辜开发者。
近期,一位名为seanGSISG的开发者在GitHub上发布了一份数据分析报告,用接近12万次Claude Code API调用日志将Anthropic的暗箱操作公开于众:
从3月6日至3月8日,Anthropic在没发布任何公告、更新日志和警告的情况下,悄无声息地将API提示词缓存的默认存活时间(TTL)从原本的1小时砍到了5分钟。

时间的骤降,带来的是成本的飙升。
从2月1日到3月5日,系统稳定运行在1小时缓存的档位,而当时的缓存资源浪费率只有1.1%。
然而在3月6日之后,5分钟级别的缓存刷新简直就像是一只吸血鬼,瞬间掏空了开发者的钱包。
仅仅是Sonnet模型的调用,就直接导致了用户的隐性使用成本被硬生生提高了17%,3月的资金浪费率也随之暴涨到26%。
这种简单粗暴的数学逻辑的核心驱动力,毫无疑问是背后的商业贪婪。
TTL变短意味着庞大的上下文背景信息每隔5分钟就会失效,系统就必须不断重新写入并创建缓存(KV Cache)。
而这么做的原因,在每一款AI产品的价格表上都体现得淋漓尽致:缓存命中与未命中时的token输入价格简直是天壤地别,后者比前者贵十倍都是常见定价。
最倒霉的反而是那些为了追求机制生产力而购买Pro Max订阅服务、付费意愿最强的用户,他们付款最多,使用最频繁,额度耗尽也最快。
这种容易被忽视的暗箱操作,反应的仍然是顶尖AI企业面对长上下文计算压力时不得不采取的商业妥协。
聚光灯下Mythos展现出了迄今为止人工智能的最高水平,而阴暗的角落中Anthropic却要克扣开发者的每一分钟缓存。
以前市场总会质疑大模型的运行是一笔亏本买卖,而如今的状况已经完全相反。
从上个月国产模型纷纷宣布涨价来看,算力问题短期内不可能被根本性解决,而Anthropic的这种行为势必会蔓延到全球AI企业。
04
如果把视线进一步抬高,从围观的开发者生态转移到整个互联网的宏观伦理层面,就会发现Anthropic这家自诩为AI道德标杆的巨头正在榨干互联网上全部的剩余价值。
Cloudflare这家为全球互联网提供底层基础设施服务的公司,恐怕全球的网友们都不会陌生。
而2026年4月初Cloudflare发布的一份最新数据,无情地揭示了Anthropic主导的一场数据榨取的真相。
传统的互联网生态中,网站需要流量才能生存,流量(点击量)就是获取信息的成本。
但自打AI出现以后,不少网站的信息失去了这种价值。
Cloudflare通过追踪AI的爬虫抓取网站内容的次数,与这些平台为原创网站带来的流量回流进行对比,并定义了一个叫做“抓取回流比(crawl-to-refer ratio)”的指标,以此衡量AI的行为给网站造成的影响。
而在这份榜单上,始终把“人类利益和负责任AI”挂在嘴边的Anthropic,凭借着8800:1的刺眼数据稳居倒数第一,碾压了同行竞品。
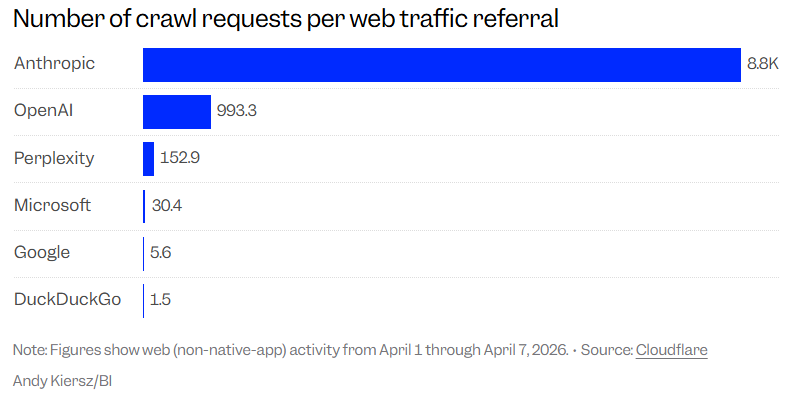
OpenAI的抓取回流比是993.3:1,还不到Anthropic的八分之一。
简单来说,Anthropic AI创建的爬虫在对互联网网页进行8000次的抓取后,只能给原创网站带来1次点击流量的回流。
在AI出现前的十几年,互联网的生态运转一直建立在一个心照不宣的隐形契约之上:
创作者允许搜索引擎免费爬取和索引自己的原创心血,作为交换,他们将获得可用于变现的真实用户流量。
然而,贪婪的生成式AI不仅破坏了这份契约,还试图从中榨取尽可能多的价值。
它们在训练阶段将互联网上仅存的人类智慧结晶嚼碎并消化,在推理阶段把知识以最终答案的形式喂给用户,彻底掐断了用户点击溯源的路径。
而这些极其高频的爬虫活动,从未将网站拥有者的服务器宕机风险和带宽成本纳入考量。
Anthropic引领的这场技术狂欢,带来的却是建立在技术强权上的生态环境毁灭。
但这种极具割裂感与讽刺的事实,在商业利益面前不仅不会被抵制,反而会被全球AI企业所效仿。
