问大家一个问题:当你接触一个陌生的代码库时,第一步是做什么?
相信大多数人的做法是,打开 README,从目录开始,一行一行往下读。但现在,一些工程师开始采用一种完全不同的方法:在看代码之前,先看 Git。
最近,一篇名为「在阅读任何代码之前,我会运行的 Git 命令」的文章引发网友热议,文中提出一个看似简单却颇具颠覆性的观点:代码只是结果,Git 才是过程。
如何理解?
作者 Ally Piechowski 认为,对于一个新的代码库,打开终端,运行一组 Git 命令,在查看任何文件之前,「提交历史」就能给出一幅关于这个项目的「诊断图」:是谁构建了它、问题集中在哪些地方、团队是自信满满地交付,还是在雷区边缘小心试探……
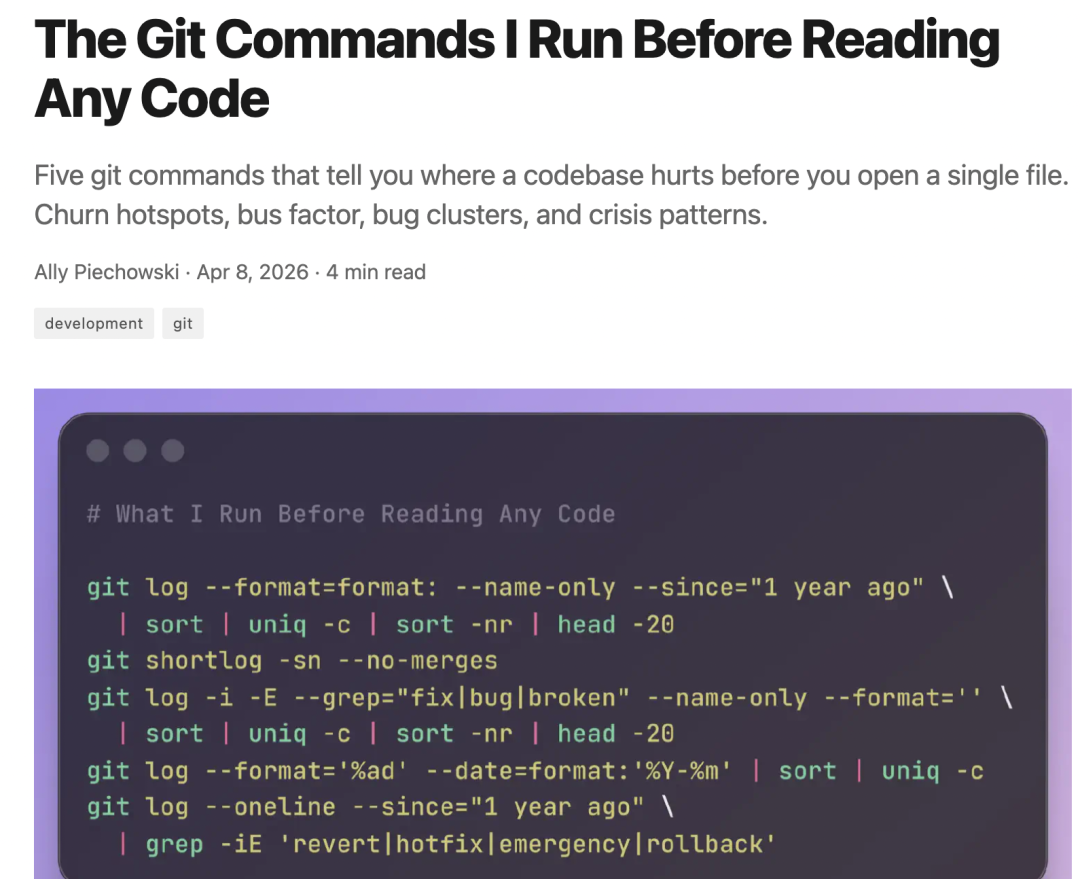
因此,Ally Piechowski 建议,在读代码之前,可以先运行这五个 Git 命令:
一、哪些地方改动最多

通过这一 Git 命令,可以查看过去一年中改动最多的 20 个文件,排在最前面的那个文件,几乎总是别人会提前提醒那一个:「哦对,就是那个文件,没人敢动它。」
当然,高频改动并不一定意味着代码不好,有时只是开发活跃,但如果一个文件改动频繁,同时又没人愿意接手,那可能就是最明确的「代码拖累」信号。这里的每一次修改,往往都是「旧补丁上再打补丁」。一个小改动的影响范围难以预测。团队在做估算时会刻意加 buffer,因为他们知道这块代码「会反抗」。
2005 年微软研究院的一项研究发现,基于「变更频率」(churn)的指标,比单纯的复杂度指标更能预测缺陷。往往一个同时「高 churn + 高 bug」的文件,就是最大的风险点。
二、谁在写这些代码?

查看按提交数量排序的所有贡献者,如果一个人贡献了 60% 以上,那就可能是「关键人依赖」(bus factor),而如果这个人已经在六个月前离开了,那就是危机。
另外在尾部,比如有 30 个贡献者,但过去一年只有 3 个活跃。这说明,构建这个系统的人,并不是现在在维护它的人。
还需要注意的是:如果团队使用 squash merge(压缩合并),作者信息会被压缩。这种情况下,结果反映的是「谁合并了代码」,而不是「谁写了代码」。因此在下结论前,最好先了解团队的合并策略。
三、Bug 都集中在哪?

这一命令的结构与 churn 分析类似,但只筛选包含 Bug 关键词的提交。将这个列表与前面的 churn 热点做对比,两个列表都出现的文件,就是最高风险代码:它们不断出问题、不断被修补,但从未被彻底解决。
但同时,这也依赖于提交信息的规范程度,如果团队每次都写「update stuff」,那几乎得不到有效信息。不过即便是粗略的 Bug 分布图,也比完全没有要强。
四、项目是在加速,还是在停滞?

这一命令可以查看整个仓库历史中,每个月的提交数量。如果节奏稳定,则说明项目是健康的;如果某个月提交量突然减半,通常意味着有人离开了;如果 6 到 12 个月呈下降趋势,说明团队正在失去动能;如果是周期性高峰 + 低谷,说明团队是「集中发版」,而不是持续交付。
五、团队有多频繁在「救火」?

这一命令是查看「回滚」(revert)与「热修复」(hotfix)的频率。一年内偶尔几次是正常的,但如果每隔几周就有一次「回滚」,说明团队并不信任自己的发布流程,而这通常意味着更深层的问题:测试不可靠、缺乏预发布环境(staging),或者部署流程让「回滚」变得困难。
如果结果为零,也是一种信号:要么系统非常稳定,要么团队根本不写清晰的提交信息。
危机模式是很容易识别的:要么存在,要么不存在。
在文章的最后,作者表示,这五个 Git 命令只需要几分钟时间,但却能让你知道:应该先读哪些代码,以及阅读时要重点关注什么,从而让你在一开始就有策略地理解代码库,而非在其中盲目游走。
其实,从作者的分享来看,这几个 Git 命令,改变了传统对代码库的理解方式,提供了一种新的视角,看到的不再只是「现在的代码长什么样」,而是「现在的代码为何会变成这样」。
与此同时,这种新颖的视角在 Hacker News 上并没有被完全接受,大家热议:这,真的靠谱吗?
有网友认为,Git 数据并不总是可靠,Commit Message 也会很水。
他表示,「如果团队有规范的提交信息,这些方法才有用。」但现实中,无论大公司还是中小企业,提交记录往往混乱,清一色的「Changes」、随意 merge、莫名 revert,还有一些人,明明团队约定用 rebase,却还是会提交 merge commit。
所以,他认为,「这一套方法主要只在中大型开源项目中才真正有用 —— 那些有清晰的 CONTRIBUTING.md/ README.md,以及明确的提交规范和合并流程的项目。」
还有网友认为,这种方法是在过度解读 Git 数据,Git 分析并不总是等于真相,很容易误导判断。
他结合自己的亲身经历分析,有时候开发者提交次数多,也许只是因为他们本身能力不行。当然,他也表示,这并不是说提交次数多就等于开发者不好。只是想提醒大家,如果把这些 Git 命令的结果当成事实本身,就有可能看不到全貌。
「如果有人跑完这些命令后跑来跟我说:「我发现某某是提交最多的人,但他 X 个月前离职了,我们该怎么办???」我可能要很努力才能忍住不笑……」
此外,还有一个争议点在于,高 churn 是否等于高风险?
网友认为,在测试中接触最多的文件往往也是最无关紧要的文件,比如依赖文件(package.json)、lock file、CI 配置,以及一些自动生成文件等,这些文件会频繁改动,但并不代表复杂。
因此,更准确的做法是,将 churn 结合复杂度来看。
那么你呢,你是如何看代码库的?或者觉得这种方法是否有启发,欢迎大家评论区留言、交流!
