作者 | 陈佳
编辑 | 心缘
智东西4月1日报道,刚刚,阿里正式发布新一代图像生成与编辑统一模型Wan2.7-Image,一举将文生图、图生组图、图像指令编辑和交互式编辑整合进同一套模型架构。
新模型主打四大能力:可自由定制五官骨相的“千人千面”捏脸功能、能精准提取和控制色彩配比的“调色盘”功能、最高支持3K token超长文字渲染的印刷级排版能力,以及支持框选区域精准操作的像素级交互式编辑能力。
我们重点测试了该模型“千人千面”、交互式编辑和多主体一致性三个方面的能力。
在人物生成测试中,无需精细控制提示词,该模型已能在同一组输出中呈现脸型轮廓、颧骨位置、下颌线各异的差异化人像,告别批量同脸问题。加入脸型关键词后,不同轮廓的响应可感知,但方脸、长脸等强特征的精准度仍有提升空间。

在交互式编辑测试中,我们以《唐顿庄园》电影剧照为素材执行人物位置互换,模型在保留服饰特征和背景环境的前提下完成了对调。

在多主体一致性测试中,我们基于参考人物要求模型生成咖啡馆、户外街拍、正式会议室三大场景共12张图像,模型精准保留了参考人物的面部特征、发型轮廓与整体气质,跨场景辨识度稳定,同时对不同场景的光影逻辑和环境氛围适配良好,是三项测试中表现最为亮眼的一项。

同步上线的Wan2.7-Image-pro在构图稳定性和语义理解上进一步提升。
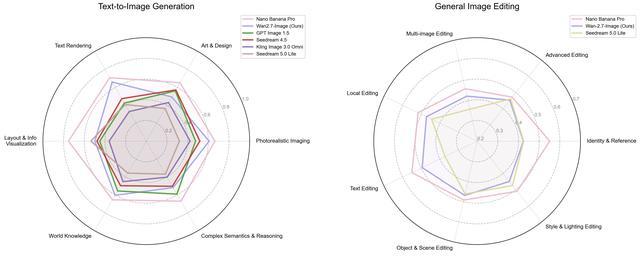
从官方盲测结果来看,Wan2.7-Image多项能力已位列国内第一,整体水平接近Nano Banana Pro。
目前,两款模型均已在阿里云百炼平台开放API调用,万相官网也支持直接体验。
万相官网:https://tongyi.aliyun.com/wan
百炼国内站:https://bailian.console.aliyun.com/cn-beijing?tab=api#/api/?type=model&url=3026980
百炼国际站:https://modelstudio.console.alibabacloud.com/ap-southeast-1?tab=api#/api/?type=model&url=3026980
一、告别“AI标准脸”,还能写满一页A4纸
AI生成人像“千篇一律”是业界长期的痛点,Wan2.7-Image强化了虚拟形象“捏脸”功能,支持从骨相到五官细节的全方位定制——脸型可在鹅蛋脸、圆脸、方脸、长方脸之间切换。
在人物生成能力上,我们使用了一条基础的提示词进行测试:“一个年轻女性肖像,半身照,电影感光影,高清细节,真实皮肤质感”。
在未加入任何脸型、五官或身份限定的情况下,Wan2.7-Image一次生成了4张人像。从结果来看,这组图已经明显不同于以往常见的“AI标准脸”,人物之间呈现出较为自然的差异。

四张图中的人物在脸型轮廓、颧骨位置和下颌线条上各不相同,并非简单的“同一张脸微调”。
同时,皮肤纹理、毛孔及轻微瑕疵(如泛红、肌理不均)均被真实保留,未出现过度磨皮的失真感。
在光影控制与整体氛围营造方面,Wan2.7-Image表现出色。四张图像均采用自然窗光作为主光源,形成强烈的明暗对比与电影化质感,背景环境元素虚实得当,未对主体造成干扰,且不同图像间的人物特征保持了较高的一致性。
整体来看,在无精细控制提示词的情况下,Wan2.7-Image已经可以生成风格统一但人物不同的人像结果,相比以往容易出现的“批量同脸”问题,有明显改善。
在基础人像生成测试后,我们进一步加入明确的脸型约束,对Wan2.7-Image的“捏脸能力”进行验证。测试提示词在原有基础上增加:鹅蛋脸/圆脸/方脸/长脸。

从实测结果来看,Wan2.7-Image模型能够对脸型特征做出差异化响应,不同生成样本中,人物面部轮廓呈现出从鹅蛋脸到圆脸、方脸的明显区分,下颌线、颧骨宽度、面部长宽比等核心脸型指标存在可感知的差异。
在皮肤质感、电影感光影等方面,限定脸型后生成的图片画面细节保留度基本稳定。但该模型的脸型控制仍存在精度与一致性的不足。部分图片存在特征模糊、脸型特征不典型的问题,难以完全匹配“方脸”“长脸”等强特征的严格定义。
对比未添加脸型关键词的基础生成版本,限定脸型后生成的图片人物面部占比整体偏大,脸部视觉尺寸有所扩增,头身比例、半身构图的原有平衡被打破。
在官方演示案例当中,Wan2.7-Image模型生成的图片人物眼部特征支持杏仁眼、深邃眼窝、圆眼、丹凤眼等多种选项,并能跨越国籍与年龄生成差异化人像。

另一大亮点是“调色盘”功能。用户可一键提取参考图的颜色及其占比,并以此为基础生成同色系图片,同时自由调控各颜色的数量和比例,构建个性化配色方案。无论是马蒂斯浓郁的红色系、梵高明媚的黄色系,还是毕加索清冷的蓝色系,都可作为输入参考,输出色调高度一致的全新画面。

在文字渲染方面,Wan2.7-Image支持12种语言,最高可处理3K token的超长文字输入,输出效果达到印刷级质量。这一能力让其在信息图、教育插画、旅游攻略长图海报等场景中颇具实用价值——理论上可以一口气生成排满一页A4纸的论文。

二、一次生成12张图,还能“哪里不爽改哪里”
Wan2.7-Image的编辑能力也迎来了显著升级,其“交互式编辑”功能支持用户在指定区域内精准框选,对框内元素进行添加、对齐、移动操作,也可进行Logo插入和人物位置互换,实现像素级意图对齐。
实测中,我们用《唐顿庄园》电影剧照图片执行“两人位置调换”的编辑指令,Wan2.7-Image成功将原图中左侧蓝裙人物与右侧黄裙人物的站位进行了对调。

人物主体、服饰特征(蓝/黄缎面礼服、头饰、项链、长手套)均完整保留,未出现主体丢失、严重变形等致命问题,整体场景的背景环境(宴会厅装饰、背景人物、花艺陈设)也基本维持了原图的一致性,实现了编辑指令的核心诉求。
官方演示中,用户框选图中两个人物后输入“互换位置”指令,模型准确完成了人物交换,且背景及其他元素保持不变。

在另一官方案例中,用户通过框选区域、指定对话气泡风格和文字内容,直接生成了毛毡风格的对话场景,文字与画面风格统一。

多主体一致性是图像生成中难度较高的任务。Wan2.7-Image在这一方向支持最多9图的风格与特征统一,可用于合影生成、电影海报及家具组合图等场景。官方展示了AI女团海报和家具组合图的生成效果,多人物之间的风格一致性较高。

我们基于参考人物进行多场景生成测试,发现Wan2.7-Image在核心人物特征的一致性还原上展现出较高水准。模型根据提示词“基于参考人物,生成3张图:(1)咖啡馆内看书;(2)户外街拍;(3)正式会议室”,输出了一组共12张图像。
从输出结果来看,模型精准保留了参考人物的核心面部特征、发型轮廓与整体气质,在咖啡馆、户外街拍、正式会议室三大场景中,人物主体的辨识度始终稳定,未出现五官变形缺陷。
同时,模型对场景环境的适配性表现优异,不同场景的光影逻辑、环境氛围与人物状态高度匹配,咖啡馆的暖光、户外的自然光、会议室的室内冷光均符合场景逻辑,人物服饰、姿态也与场景属性高度契合。


三、不只会画图,还开始“理解图”
从技术层面看,Wan2.7-Image有三个维度的升级。
在训练数据上,模型底座整合了超大规模异构视觉素材,并额外加入了理解类数据,使模型不止于像素级拟合,还具备底层语义认知能力。
在模型架构上,Wan2.7-Image采用生成与理解统一的模型架构,在共享隐空间(Latent Space)内实现语义映射——文字紧挨着画面,模型不需要费力推断文字对应的画面区域。同时,训练流程中引入了多模态指令(文字+图片),进一步强化了从“像素拟合”到“语义认知”的跨越。
此外,模型还支持调用WanImage Skill工具,据官方介绍可实现“让龙虾画画”等创意指令编排。
在人类偏好盲测中,Wan2.7-Image多项能力位列全国第一,综合成绩接近Nano Banana Pro。同步上线的Wan2.7-Image-pro版本在训练数据规模和模型尺寸上进一步扩大,构图稳定性和语义理解精准度更高。
四、从电商到短剧,图像模型开始全面落地
Wan2.7-Image在多个垂直场景展示了行业落地潜力。
在短剧制作方向,模型支持角色生成中的“一人分饰多角”,通过多主体一致性能力保持同一角色在不同场景中的特征稳定;分镜生成可将人物自然融入场景,并通过交互式编辑精准调整人物位置和大小。


在电商广告场景,模型支持从单张模特图一键裂变出多张不同角度、不同场景的展示图,并可按电商上架格式自动输出场景图、特写图、尺寸图和卖点图等套图组合。

颜色变装(通过调色盘功能切换服装色彩)、四季拼图生成以及“拯救废片”(消除闭眼)等功能,可满足小红书、B站等社交平台的内容创作需求。OOTD穿搭生成和不露脸服装替换也在演示中效果稳定。


该模型可生成图文并茂的知识卡片和教育插画,内容创作方向支持B站封面、小红书封面、种草图文等常见内容格式。

结语:图像模型正在走向“可控化”和“生产力工具”
从Wan2.7-Image的技术突破中可见,图像模型的技术竞赛已转向更深层的维度。其核心价值不再局限于“画得像不像”的表象还原,而是能否精准控制人物形象、颜色搭配和画面布局,能否深入理解文本与语义内涵,能否无缝融入设计、电商、内容创作等工作流程。
随着长文本渲染能力的突破、交互式编辑的灵活操作以及多主体风格一致性的显著提升,图像模型正从辅助性的“创意工具”蜕变成为驱动产业效率的“高效生产力工具”。“千人千面”和“调色盘”这类能力,也意味着AI生成内容开始走向个性化与可控化。
