
同样的算力,同样的数据,凭什么效果不一样?大多数人的直觉是:模型更大、数据更好、工程师更厉害。但 Kimi 给出了一个更出人意料的答案。
3 月 16 日,月之暗面 Kimi 发布了一项重磅技术报告《Attention Residuals》(注意力残差)。
这项技术针对几乎所有现代大模型都在使用的残差连接结构进行了改造,并在实验中证明,用同样多的算力,新方法训练出的模型效果相当于基线模型花费 1.25 倍算力才能达到的效果。
报告发布后,也毫无意外得到了许多硅谷顶尖 AI 人物的点赞背书。
▲附 GitHub 开源地址:github.com/MoonshotAI/Attention-Residuals
比如马斯克通过社交媒体表示「「Impressive work from Kimi」(令人印象深刻的工作)」OpenAI o1 主要发明者 Jerry Tworek 称其为「深度学习 2.0」的开端。
前 OpenAI 联创 Andrej Karpathy 说「看来我们还没把『Attention is All You Need』这句话按字面意思理解透。」但比起这些夸奖,技术论文背后的信号或许更值得关注:深度学习最基础的范式,正在发生变化。

十年没人动过的地基,被撬动了
过去两年,大模型的竞争主要在「上层建筑」展开:更好的注意力变体、更聪明的 MoE 路由策略、更精巧的对齐方法,大家都在 Transformer 这栋大楼的高层精装修。
唯独有一样东西,从 2015 年 ResNet 论文发表以来,几乎没人动过:残差连接(Residual Connections)。
要理解这项技术,得先知道大模型内部的基本结构。
现代大模型,其实都是由很多层神经网络叠加而成的,少则几十层,多则上百层。信息从底部输入,一层一层往上传递,每一层都对信息做一次加工,最终在顶部输出结果。
可以把它想象成一条流水线上的工人:原材料从第一道工序进来,每个工人对它加工一遍,再传给下一个,最终出来成品。问题是,流水线越长,越难训练。
假设第 50 道工序的工人犯了错,你想纠正他,就得把这个「纠错信号」一路往回传,经过 49 个工人才能传到第 1 个。传着传着,信号就消失了,底层的工人根本不知道自己哪里出了问题。
为了让这么深的网络能够训练起来,知名学者何恺明团队在 2015 年发表了一篇题为《Deep Residual Learning for Image Recognition》的论文,引入了一个关键设计,叫做残差连接(Residual Connections):
每一层在加工信息的同时,还会保留一条「直通道」,把原始输入原封不动地加到加工结果上,再往下传。这条直通道让梯度在反向传播时可以绕过中间的变换,一路流回底层,从根本上解决了深层网络难以训练的问题。
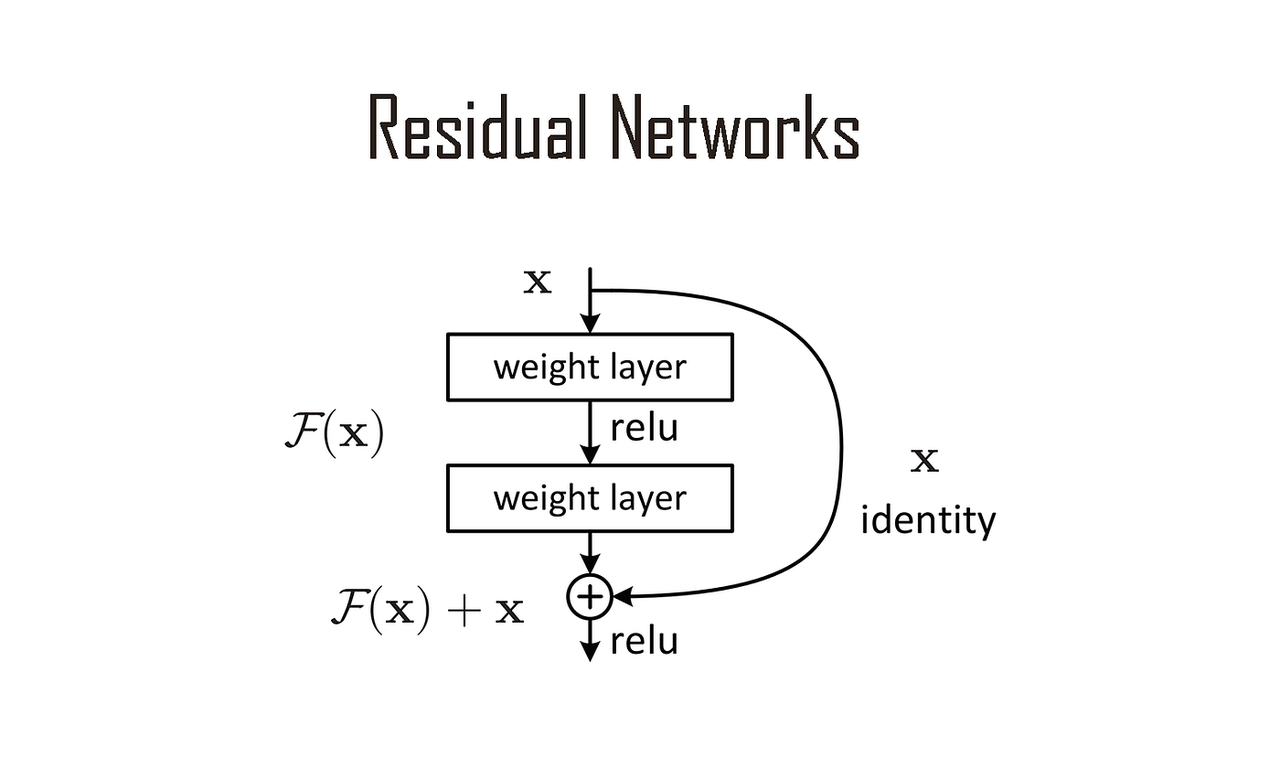
比较通俗的理解是,在每道工序旁边加一条「直通道」,把原材料原封不动地绕过这道工序,直接和加工结果合并,再往下传。这样纠错信号就可以沿着直通道一路畅通无阻地传回底层,不会消失。
这篇论文后来成为计算机视觉乃至整个深度学习领域引用次数最多的论文之一,残差连接也沿用至今,是几乎所有大模型的基石。
残差连接虽然好用,但它做信息聚合的方式非常粗暴:把所有前面层的输出,无差别地等权相加。
还是用流水线来比喻。到了第 51 道工序,这个工人手里拿到的,是前面 50 道工序所有产出物的等量混合,每道工序的产出各占一份,不多不少。他没有办法说「我想多要一点第 3 道工序的原料」,也没有办法说「第 20 道工序的东西对我没用,少给我一点」。
这带来了一个名为 PreNorm 稀释的实际问题 :随着网络越来越深,累积叠加的信息越来越多,每一层自己的贡献在庞大的总量里越来越微不足道。越靠后的层,想要让自己的声音被「听见」,就得输出越来越大的数值,否则就会被淹没。
结果就是,很多中间层其实没在认真干活。已有研究发现,大模型里相当一部分层直接删掉,效果几乎不变,这说明这些层的贡献实际上极为有限。
大多数团队早就知道这个问题,选择绕开它,转而在在现有架构上叠加更好的数据配比、更精巧的训练策略、更长的上下文窗口。这些工作当然有价值,但本质上是在一个已有的技术框架内做增量优化。
Kimi 选择的是一条更孤独也更难的路:回到最基础的结构,用第一性原理重新审视那些「理所当然」的设计。
今天凌晨,Kimi 创始人杨植麟在 GTC 2026 演讲中提到:「行业目前普遍使用的很多技术标准,本质上是八九年前的产物,正逐渐成为 Scaling 的瓶颈。」
杨植麟认为,要推动大模型智能上限的持续突破,必须对优化器、注意力机制及残差连接等底层基石进行重构。
一次优雅的「旋转」
Kimi 团队这篇论文的核心突破,其实也来自一个优雅的类比发现。
处理文字序列时,早期的循环神经网络(RNN)也有类似的额外问题:记性差。它读完一整段话之后,早期读到的内容会被后来的内容不断覆盖,等读到最后一个词,前几句说了什么已经模糊了。
后来 Transformer 用注意力机制解决了这个问题,相当于给模型配了一张「全文笔记」,处理每个词的时候,都可以翻回去查任意一个之前出现过的词,而且查哪里、查多少,由当前的内容自己决定。
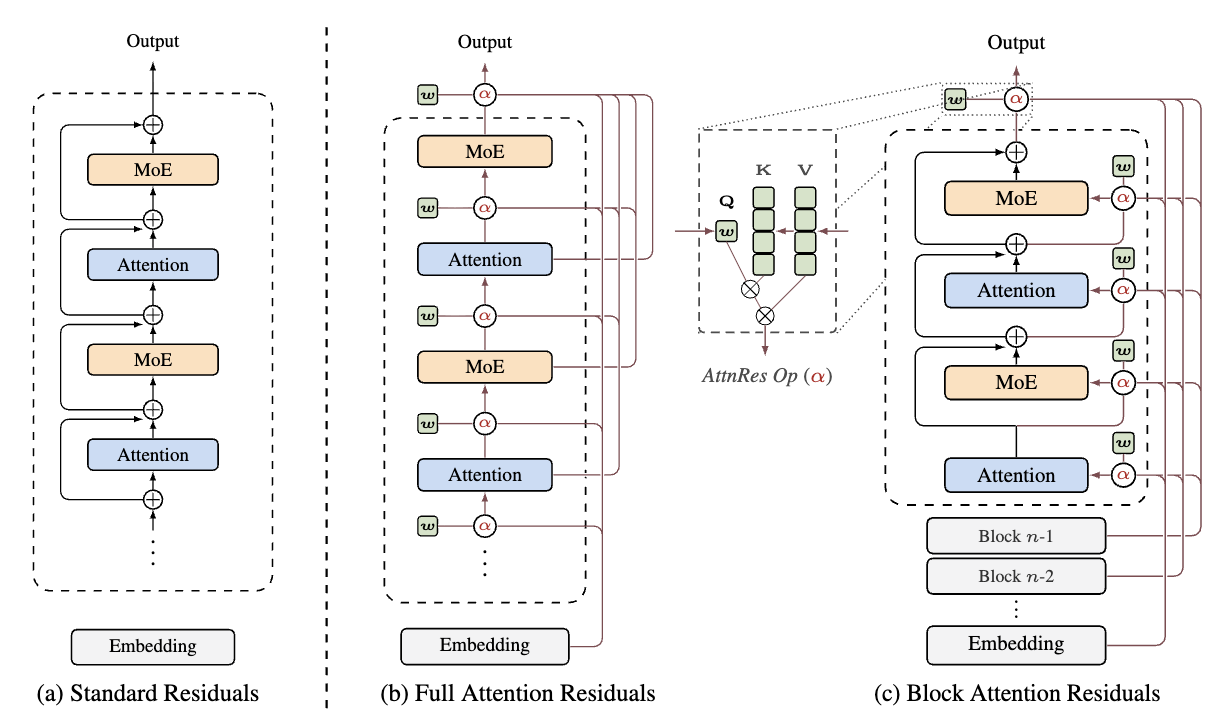
研究人员发现,残差连接在深度方向上碰到的问题,和 RNN 在时间方向上碰到的问题,数学结构完全一样。换句话说,把 Transformer 想象成一张二维的网格:
横轴是序列方向,一句话里从左到右的每个词;纵轴是深度方向,从底层到顶层的每一层网络。传统的注意力机制是沿着横轴工作的,处理某个词时去查同一层里其他词的信息。
而 Attention Residuals 做的事情,就是把完全相同的机制转到纵轴上去,处理某一层时去查前面所有层的输出,决定要参考哪些层、参考多少。操作对象从「同一层里的不同词」变成了「同一个词在不同层里的状态」,机制本身一模一样,好比方向转了 90 度。
既然注意力机制解决了序列方向的问题,旋转一下搬到深度方向上,同样有效。
这里有一个更深层的理论发现值得一提。研究人员通过数学分析发现,过去十年里所有对残差连接的改进,包括标准残差、Highway 网络、mHC 等各种变体,在数学上其实都是同一件事的不同形式,都等价于某种「深度方向的线性注意力」。换句话说,大家一直在朝同一个方向努力,只是当时没意识到。
而 AttnRes 的核心思路在于,把注意力机制从「处理文字序列」的维度,移植到「跨越网络深度」的维度上。
具体做法是,给每一层配备一个小小的「查询向量」,就像给每道工序的工人配了一张需求单。工人在开工前,先拿着需求单去翻所有前面工序的产出,根据相关度算出一套取用比例,再按这个比例把需要的原料混合起来。
这样一来,每一层不再是被动接受所有前面层输出的等权叠加,而是主动、有选择性地决定要从哪些层提取多少信息,比例还会根据当前任务的内容动态变化。每层只新增一个向量和一个归一化操作,参数量的增加对整个模型来说几乎可以忽略不计。
为了保证训练初期稳定,这个查询向量必须初始化为全零,相当于让工人一开始什么偏好都没有、平等对待所有前序产出,等训练推进了再慢慢形成自己的判断。
值得一提的是,研究人员也测试过一个更激进的版本:让查询向量不再是固定参数,而是根据每一层当前的输入内容动态生成。这个版本效果确实更好,损失值进一步下降。
但最终没有采用,原因是推理时这种方式需要顺序读取内存,会增加延迟。这个取舍体现了贯穿整篇论文的工程哲学,理论上更优的方案,不一定是实用上应该选的方案。
大模型的新技术,最后都得过这一关
全量 AttnRes 在小规模实验中很好用,但一到大规模训练就遇到了麻烦。
它需要每一层都能访问所有前面层的输出。模型有一百多层,每层的输出都得保存在内存里,还要在不同计算节点之间来回传输,内存和通信开销随层数线性增长,在大模型上根本承受不起。
Kimi 团队的解法很实在:Block AttnRes。把网络所有层划分为若干个 Block(48B 模型中分了 8-9 个 Block,每个 Block 约 6 层),Block 内部沿用传统残差连接,Block 之间使用 softmax 注意力。打个比方——不必给每层楼都装电梯,在关键楼层之间架设快速通道就够了。
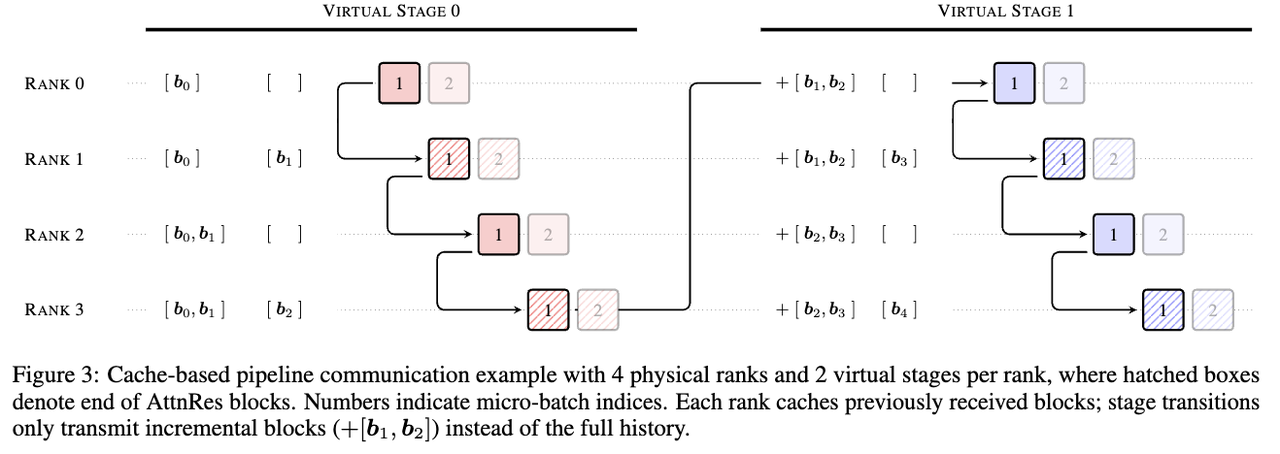
这样,需要保存和传输的数据量,从「所有层的数量」降低到「块的数量」,开销大幅缩小。实验发现,分成约 8 个块就能保留全量方法绝大部分的性能提升。
在具体的工程实现上,团队还做了两项优化。
训练端设计了跨阶段缓存机制,在流水线并行训练中每次切换阶段时只传输新增的那一小部分块数据,而不是每次都把全部历史重新传一遍,实测整体训练额外开销不超过 4%。
推理端设计了两阶段计算策略,把一个块内所有层的查询打包成一次矩阵运算统一处理,把重复的内存访问摊销掉,最终推理延迟增加不超过 2%。
那实验效果怎么样呢?研究人员测了五个不同规模的模型。
结果显示,Block AttnRes 在全部规模上均以更低的验证损失领先于基线,且改善幅度随规模增大而稳定保持。按拟合曲线推算,在相同的计算量下,Block AttnRes 相当于基线模型用 1.25 倍算力才能达到的效果。
在 48B 参数(3B 激活)规模的 Kimi Linear 架构实验中,Block AttnRes 展现了极强的泛化性:在全部 15 项主流评测基准中,其表现均持平或优于 PreNorm 基线模型。
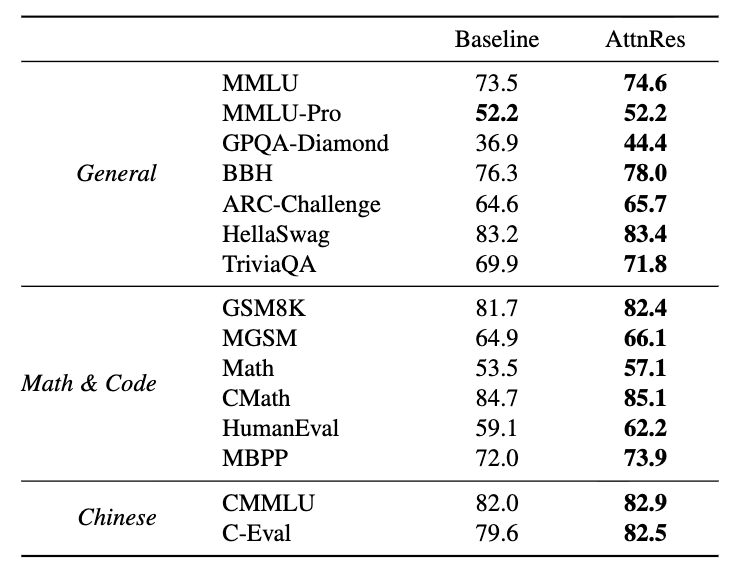
例如,在博士级科学推理 GPQA-Diamond 上实现了 7.5% 的飞跃,在数学 Math (+3.6%) 及代码生成 HumanEval (+3.1%) 任务中也录得了显著增益 。
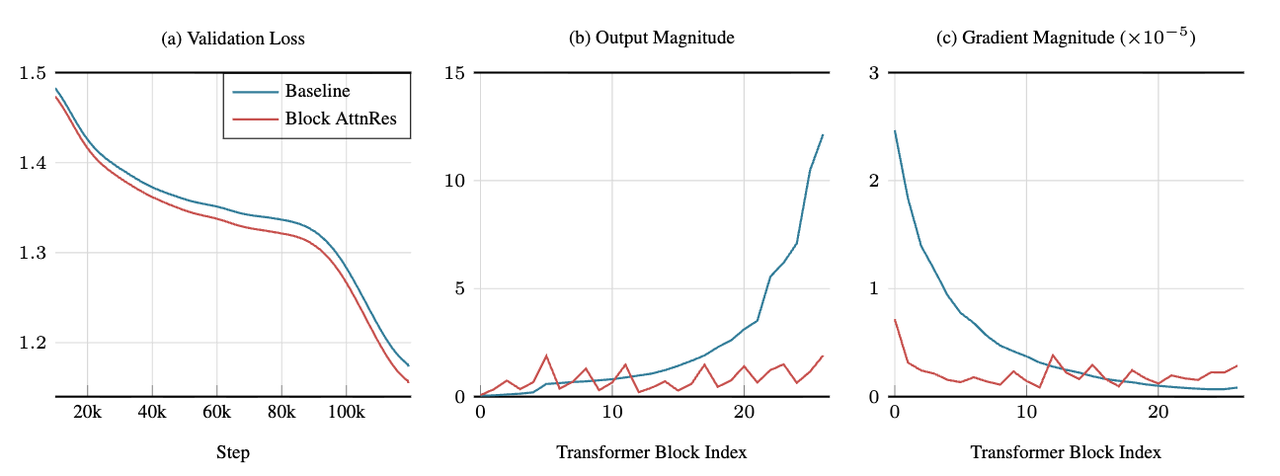
从训练过程来看,基线模型的各层输出数值随深度单调增大,印证了 PreNorm 稀释问题;而 AttnRes 的各层输出数值在块边界处得到重置,呈现周期性变化,各层梯度分布也更加均匀,说明更多的层真正参与到了有效的学习中。
此外,研究人员还可视化了训练后模型学到的注意力权重,发现了几个有趣的规律。
每一层仍然最依赖直接前一层的输出,局部性依然是主要的信息流通方式。但同时出现了一些跳跃性的连接,比如某些层会稳定地回溯到很早期的层,还有些层会特别关注最初的词嵌入输出。
另一个规律是,注意力层和 MLP 层的「回望」模式不同:注意力层倾向于关注更广泛的历史,MLP 层则更依赖近邻层。这与两者在模型中的功能分工是吻合的。
AttnRes还带来了一个对未来模型设计有参考价值的发现。研究人员在固定总计算量和参数量的前提下,枚举了 25 种不同的深度与宽度组合,对比基线模型和 AttnRes 各自偏好的最优架构。
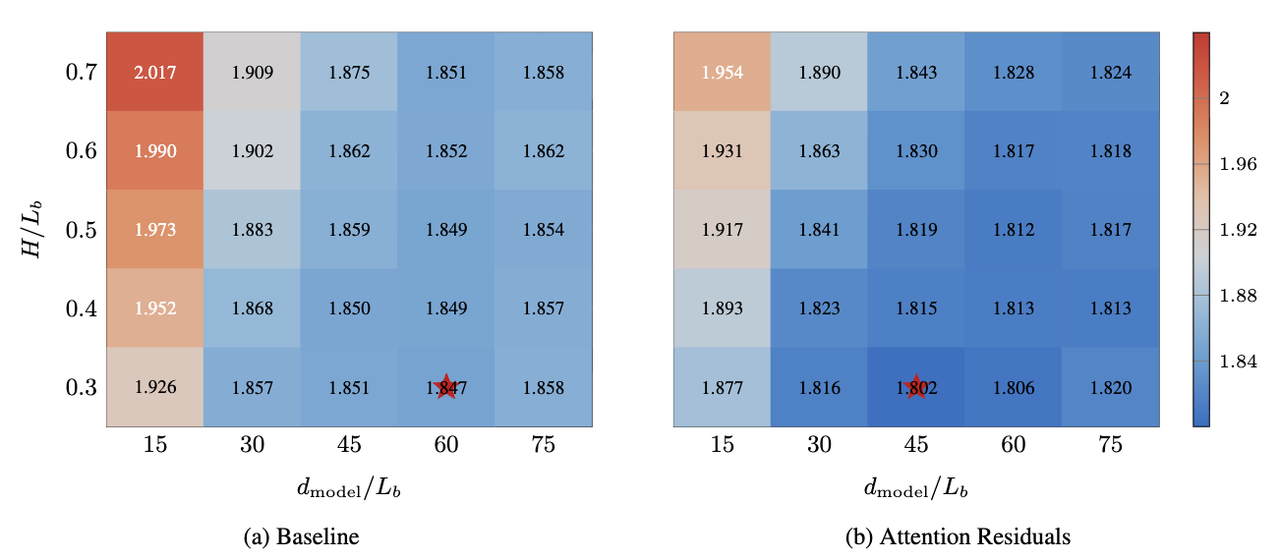
结果发现,标准残差连接偏好「更宽、层数更少」的模型,而 AttnRes 的最优点偏向「更窄、层数更多」的模型。这说明 AttnRes 能够更有效地利用深度,让每增加一层都真正产生价值,而不是让深度变成一种边际效益递减的堆砌。
这个发现的含义不止于此。它意味着 AttnRes 不只是在原有架构上打了一个补丁,而是从根本上改变了网络深度的利用效率,也为未来设计大模型时如何分配深度与宽度的资源提供了新的参考依据。

杨植麟曾提到,十年前不是没有好想法,而是没有算力去验证。现在有了足够的资源和「缩放阶梯(Scaling Ladder)」,那些被搁置的问题才终于能被认真答一遍。
大佬点赞的背后,是一个时代在转弯
一个中国团队在最底层的架构创新上获得硅谷顶级人物的实质性认可,这件事本身十分罕见,他们认可的不只是论文成果本身,更在于Kimi 这篇论文指向了一个全新的方向:优化已经从 attention、MoE 这些上层模块,深入到了最底层的残差连接。
在 GTC 2026 演讲中,杨植麟还披露了一连串底层技术创新:MuonClip 优化器实现了相比 AdamW 2 倍的计算效率提升——要知道 Adam 优化器自 2014 年以来几乎未被撼动,属于深度学习的「不可触碰之物」;Kimi Linear(KDA 架构)在 128K 到百万级超长上下文下实现 5-6 倍的解码加速;Vision RL 的跨模态训练甚至让纯文本 benchmark 也提升了约 2.1%。
杨植麟把这些创新概括为三个维度的 Scaling 框架:Token 效率 × 长上下文 × Agent Swarms。
「当前的 Scaling 已经不再是单纯的资源堆砌,而是要在计算效率、长程记忆和自动化协作上同时寻找规模效应。」
一家公司,同时在优化器、残差连接、注意力架构、跨模态训练这些底层战场上全线推进,这种打法在行业里相当特立独行。
这也是为什么 Jerry Tworek 会说出「深度学习 2.0」这样的判断。当然不是说 Attention Residuals 这篇论文就能颠覆一切,更多是它代表了一种方法论的回归:不再满足于在已有框架上修修补补,去重新审视那些被所有人当作「已解决问题」的基础设施。
如果残差连接可以被重新设计,那么 Adam 优化器呢?层归一化呢?位置编码呢?深度学习的基础范式本身正在发生变化,这扇门一旦推开,后面的故事就不再是线性外推能预测的了。
Karpathy 那句「Attention is All You Need 还没被理解透」的感慨,大概也是这个意思。
过去几年,中国 AI 团队的贡献更多集中在工程落地和应用创新上,在底层架构理论方面的原创性突破相对稀缺。Kimi 这篇论文走的是一条完全不同的路线——一个统一的理论框架,一个优雅的工程实现,加上严谨的大规模实验验证。
当然,Kimi 这篇论文还有留下不少需要解决的问题。论文的大规模验证是在 48B 总参数(3B 激活参数)的模型上完成的,这个规模放在今天的第一梯队里并不算大。在真正的千亿乃至万亿参数模型上,1.25 倍的等效优势能否稳住,目前还是个问号。
同时论文展示的也只是预训练阶段的收益,经过指令微调、RLHF 等后训练步骤后,AttnRes 的优势是否会被稀释,缺乏数据。
但话说回来,这些局限恰恰也是想象力的来源。一个仅需约 100 行代码改动、增加不到 4% 训练开销的轻量修改,就能在 48B 规模上带来这样的提升。
当它被应用到更大规模的下一代模型上时,收益的天花板在哪里,谁也说不准。
Attention Residuals 抬高了 Token 效率的天花板,Kimi Linear 拓展了长上下文的边界,Agent Swarms 指向智能体协作的未来。当这三条技术线在下一代模型中汇合,呈现出的可能就是新的范式转变。
在 AI 这座通天塔的工程上,所有人都在争着往上添砖加瓦,而 Kimi 低头往路基重重地凿了一锹,恰好撬动了深度学习的地基。
作者:莫崇宇,李超凡
