智东西
作者 | ZeR0 程茜
编辑 | 漠影
就在刚刚,全球最大规模的AI盛会——英伟达GTC 2026盛大开幕!
智东西3月16日圣何塞现场报道,美西时间11点18分,英伟达创始人兼CEO黄仁勋身穿标志性皮衣登场,发表了一场激情澎湃的主题演讲。
200亿美元买下的Groq技术、掀起“全民养虾”盛世的OpenClaw、一大波全新开放模型、L4自动驾驶最新进展,全部浓缩在这场信息密度极高的演讲之中。
先上重点,英伟达发布其旗舰AI计算平台Vera Rubin的5大机架级系统,推出全新AI推理芯片Groq LPU 3,宣布7款芯片全面生产,并带来太空计算设备Space-1 Vera Rubin Module,将AI计算版图扩展到地球之外。

7款芯片分别是Rubin GPU、Vera CPU、ConnectX-9 SuperNIC、BlueField-4 DPU、NVLink 6 Switch、Spectrum-X 102.4T CPO,以及新集成的Groq 3 LPU。
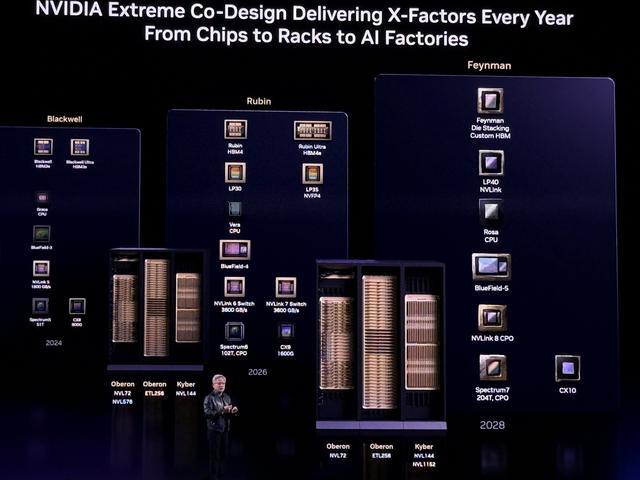
英伟达还公布了最新产品路线图:
对于Rubin架构,Oberon系统采用铜缆纵向扩展,还可以使用光学扩展,将NVLink扩展到576。黄仁勋说,铜缆纵向扩展和光学纵向扩展,英伟达都会采用。
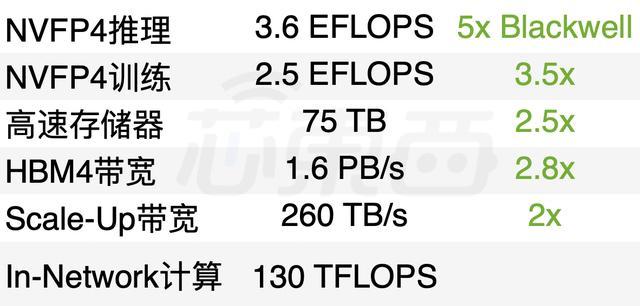
Rubin Ultra芯片正在流片,即将到来;还有全新的LP35芯片——将首次融入英伟达的NVFP4计算结构,带来又一个几倍的速度提升。
Oberon之后,Kyber系统采用铜缆纵向扩展,还将有Kyber CPO纵向扩展——首次同时支持铜缆和共封装光学的纵向扩展。
计划在2028年发布的英伟达AI数据中心扛鼎之作们,也被一次性曝光:Feynman GPU(定制HBM)、LP40 NVLink、Rosa CPU、Bluefield-5 DPU、NVLink 8 CPO、Spectrum7 204T CPO、ConnectX-10 SuperNIC。
在2小时10分钟的演讲中,英伟达密集甩出超过20项重磅发布,涉及AI基础设施、智能体、推理、开放模型、机器人、自动驾驶、企业级AI等,这些也是今年GTC大会的核心话题。
今年恰逢CUDA诞生20周年,黄仁勋想说的话很多,最言简意赅的当属下面这张图,基本概括了英伟达100%的战略布局:
CUDA庞大的装机基数吸引开发者,开发者创造新算法,算法突破催生新技术,新技术开辟全新市场,全新市场构建新生态,更多企业加入生态,进而扩大装机基数——这个飞轮,正在加速转动。
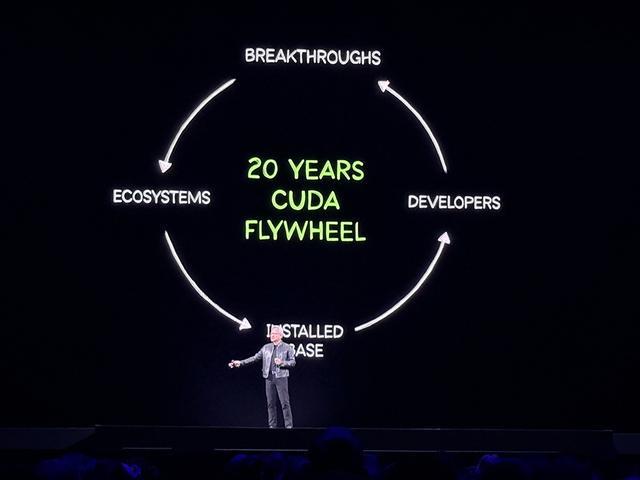
20年前,英伟达发明了CUDA,这是其有史以来最重大的投资之一,消耗了公司绝大部分利润,导致当时的英伟达几乎负担不起。但历经初期的重重困难,历经13代产品、整整20年的坚持,如今,CUDA已无处不在。
黄仁勋宣布,英伟达与IBM达成深度合作,并晒出与谷歌云、AWS、微软Azure等云巨头的合作案例。“今年我特别兴奋的一件事是,我们将把OpenAI带到AWS。”
他提到过去两年,ChatGPT、生成式AI、Claude Code三件事持续推动AI浪潮,英伟达的计算需求已经爆表,现货价格飞涨,推理的拐点已经到来。
回顾整场演讲,几个掌声雷动时刻,堪称“人气王”:
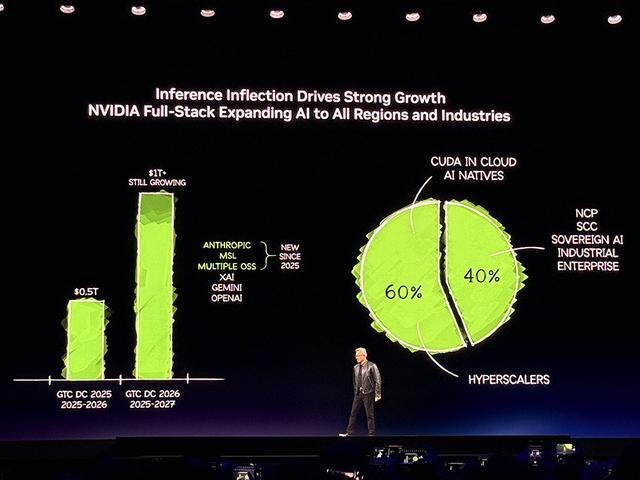
1、黄仁勋预言:到2027年将坐拥1万亿美元订单
黄仁勋估计英伟达2025年订单额约为5000亿美元,并大胆预测,到2027年,这一数字将翻番,至少会达到1万亿美元。
2、龙虾一出,全场欢呼
在萌版红色龙虾出现在大屏幕的刹那,观众席瞬间沸腾!果然论起炸场,还得看今年AI领域的“头号顶流”——开源AI智能体框架OpenClaw。
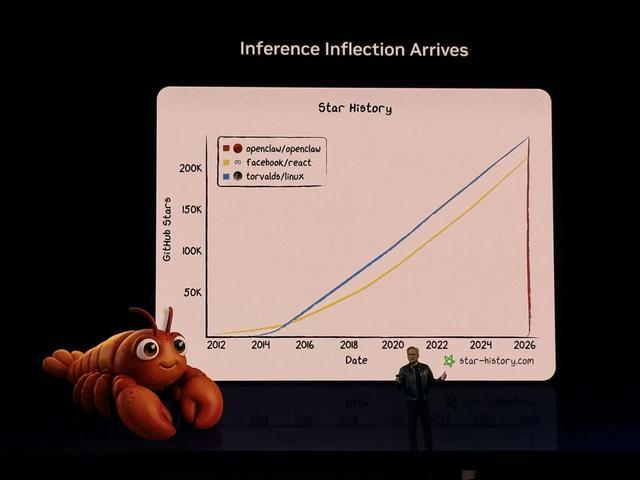
为开发者掏心掏肺的英伟达,这次直接端出“养龙虾全家桶”:软件包括英伟达版龙虾NemoClaw、智能体基础模型Nemotron 3 Ultra、智能体工具包,硬件有个人AI电脑DGX Spark和桌面级AI超算DGX Station。
大会期间,英伟达每天都在GTC Park举办build-a-claw部署活动,帮参会者免费装“龙虾”。参会者带上自己的NVIDIA DGX Spark或GeForce RTX笔记本电脑,就能在英伟达专家的帮助下本地部署智能体,打造自己的专属AI助手。英伟达还诚意拉满,给OpenClaw爆红之路做了个精致的回顾视频。
OpenClaw创始人Peter Steinberger特意发推文安利:“用OpenShell和 NemoClaw烹饪真的太有趣了!🦞”

3、英伟达机器人全家福亮相
黄仁勋放出一张最新机器人大合照,有30多台机器人,包括比亚迪、库卡、智元、小鹏、吉利的机器人。

黄仁勋谈道,机器人是一个50万亿美元的制造业市场,英伟达已在此深耕十年,本届大会现场将展示110台机器人,全球几乎每一家机器人公司都在与英伟达合作。
4、“雪宝”机器人压轴登场,跟黄仁勋热聊
“这里有很多人形机器人,但我最喜欢的之一……是一款迪士尼机器人。”黄仁勋夸奖一响,《冰雪奇缘》电影同款的“雪宝”机器人闪亮登场!
“雪宝”机器人先是出现在一段展示“全球首次大规模物理AI部署已经到来”的影片里,当迪士尼Newton Snow Solver物理引擎将“雪宝”所在的冰雪场景和彩色糖果场景丝滑切换,现场响起热烈的掌声。
影片一结束,真正的“雪宝”机器人就走了出来,与黄仁勋热聊互动,逗乐观众。
5、魔性收尾:Q版黄仁勋、龙虾和机器人组乐队
大会收尾别出心裁,黄仁勋数字人与一群机器人、一只萌版龙虾,一起拍了一支魔性音乐MV,歌词把本届GTC的核心干货唱了个遍,曲调也很上头。(文末附上了歌词全文)
今年GTC大会人气相当火爆,超过30000名参会者齐聚圣何塞,有1000多场技术分论坛、2000多位演讲嘉宾。英伟达将在本届GTC大会上发布大约100个库、70个模型及40个模型。
一、5大机架组出Vera Rubin巨型AI超算,Groq 3 LPU芯片丝滑融入英伟达全家桶
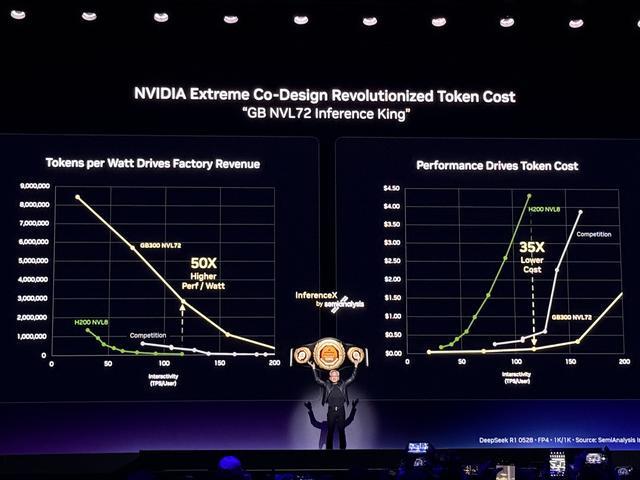
“我们每Token的成本是全球最低的,无法被超越。”黄仁勋说,“我之前说过,如果你选择了错误的架构,即便它是免费的,也还是不够便宜。”
在他看来,只有在AI工厂安置了最好的计算系统,才能获得最低的token成本,而英伟达的token成本基本无可匹敌,原因在于极致的协同设计。
全新Vera Rubin平台是当前英伟达瞄准AI推理计算市场的王牌产品:7款芯片、5种机架级计算机、1台革命性AI超算,专为智能体打造——仅用10年,就将算力提升了4000万倍。

在GTC主题演讲中,黄仁勋一口气介绍了Vera Rubin平台的5款全新机架级系统:
NVIDIA Vera Rubin NVL72 GPU机架
NVIDIA Groq 3 LPX推理加速器机架
NVIDIA Vera CPU机架
NVIDIA BlueField-4 STX存储机架
NVIDIA Spectrum-6 SPX以太网机架

它们以统一的MGX模块化架构进行深度协同设计,可自由组合,按负载密度和价格梯度灵活部署,加快产品上市速度,服务于整个AI工厂。
当这些汇聚在一起,意味着Vera Rubin平台将扩展整个AI工厂的收入机会。
目前,7款全新芯片已全面量产,可在超大型AI工厂中规模化部署。
基于Vera Rubin的产品将从下半年开始由英伟达的合作伙伴提供。
1、Vera Rubin NVL72 GPU机架
Vera Rubin NVL72系统集成了由NVLink 6链接的72颗GPU与36颗Vera CPU,以及ConnectX-9 SuperNIC和BlueField-4 DPU。

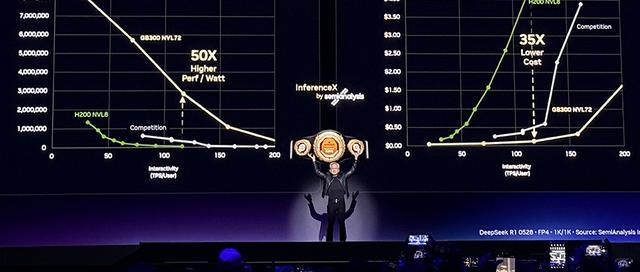
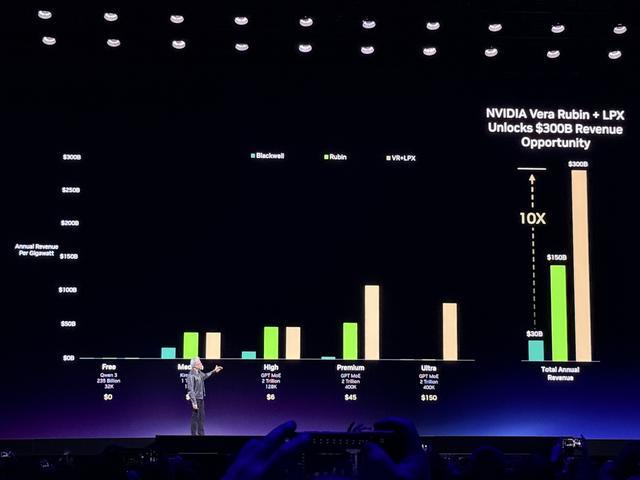
相较前代Blackwell平台,在Vera Rubin平台上训练大型混合专家模型时,所需GPU数量仅为1/4,并在AI推理方面,实现推理吞吐量提升10倍,token单位成本降至原来的1/10。
黄仁勋认为,token是新的大宗商品,一旦达到拐点、走向成熟,它将会分层细分,不同模型尺寸、智能、速度、上下文长度对应不同的价格。英伟达在每一层都提升吞吐量。
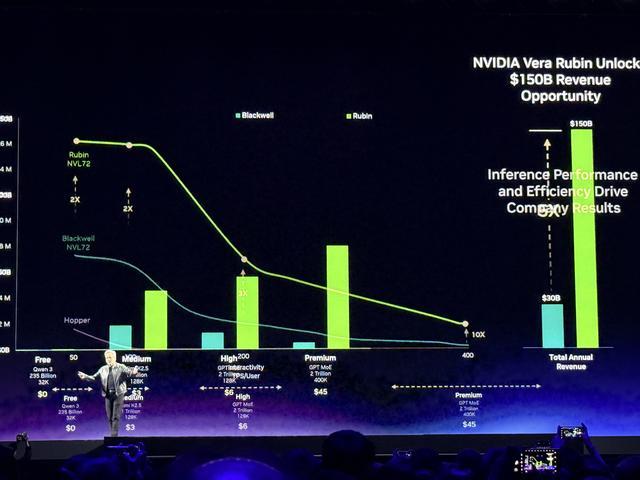
注:图中免费层(千问3 235B 32K),中级层(Kimi K2.5 1T 128K),高级层(GPT MoE 2T 128K),旗舰层(GPT MoE 2T 400K)
吞吐量需要大量算力,延迟和交互性需要巨大的带宽。由于芯片面积有限,因此追求高吞吐量和追求低延迟,实际上是互相冲突的目标。
英伟达通过引入Groq技术来解决这一冲突,在最贵的旗舰层将性能提升35倍。
如果将图表里的曲线向右延伸,想要每秒1000个token的服务,NVLink 72就会力不从心,因为没有足够的带宽。
而这,恰恰是Groq发挥作用的地方。
2、Groq 3 LPX推理加速器机架
去年12月,英伟达买下AI芯片创企Groq非独家协议和核心成员的交易轰动科技圈。业界密切关注Groq的LPU芯片是否会与英伟达GPU形成竞争。
现在,答案揭晓,LPU并不是来取代GPU的,而是来加入GPU这个家的。
在英伟达的布局里,Rubin性能强,LPU带宽高、延迟低,两者优势恰好互补。
因此,英伟达推出全新NVIDIA Groq 3 LPU,实现GPU超强算力与LPU超高带宽的融合。

来看一组对比:
一张Rubin GPU拥有3360亿颗晶体管、288GB HBM4内存、22TB/s带宽、50PFLOPs算力(NVFP4)、 2.5T(HBM4)。
而一张Groq 3 LPU只有980亿颗晶体管、500MB SRAM,内存容量仅为Rubin HBM4的1/500,算力达1.2PFLOPS。但其SRAM带宽高达150TB/s,是Rubin带宽的约7倍。

在此基础上,英伟达发布Groq 3 LPX机架。
这款新机架可支持256张Groq 3 LPU,共有128GB片上SRAM、315PFLOPS算力、640TB/s扩展带宽,可扩展至超过1000张LPU。

黄仁勋说,Groq如此吸引人的原因在于:其计算系统是一种确定性数据流处理器,静态编译,由编译器调度——编译器预先确定何时执行计算,数据同步到达,所有这些都在软件中静态预排,没有动态调度。
该架构设计配备了大量SRAM,专为推理这一个单一工作负载而设计。
需要大量的Groq芯片,才能存储Vera Rubin的参数规模以及必须与之配套的KV Cache,这使得Groq受到一定限制。
对此,英伟达用Dynamo软件重新构建推理的管线,使适合的工作放在Vera Rubin上运行,然后将解码生成部分,也就是低延迟、带宽受限的挑战性工作负载部分,卸载到Groq上。这就将两款各具极端优势的处理器统一起来。
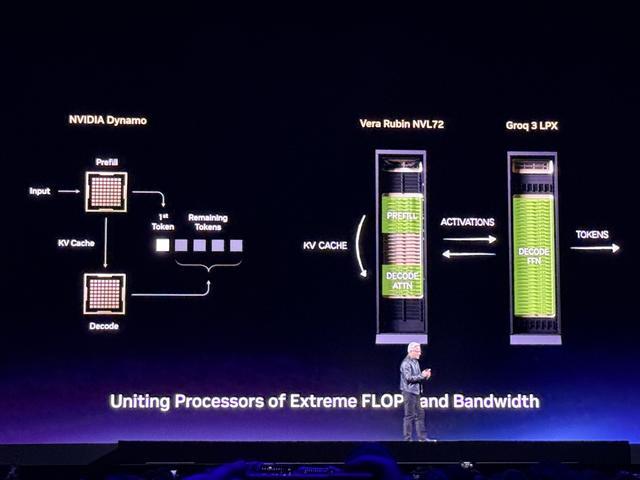
协同设计的LPX架构与Rubin GPU紧密耦合,LPX作为token加速器,叠加在拥有高吞吐量的Vera Rubin之上,两者合计可将运行万亿参数模型时提供每兆瓦推理吞吐量提升35倍。Groq 3 LPU由三星代工,已进入量产,预计下半年出货,大约在第三季度。
3、NVIDIA Vera CPU机架
智能体模型的训练和部署推理都离不开CPU。GPU需要调用CPU来执行工具调用、SQL查询和代码编译等任务,CPU的速度至关重要。
英伟达将Vera CPU称作“专为智能体AI工作负载打造的最佳CPU”。
Vera搭载全新Olympus核心,是全球唯一使用LPDDR5的数据中心CPU,结合高性能与高能效的核心设计、高带宽内存子系统以及第二代英伟达可扩展计算Fabric,能在各类智能体应用场景和强化学习极端条件下提供更快的响应速度。
相比传统x86 CPU,Vera单线程性能提升50%,每核心内存带宽提升至3倍,能效翻倍。
今日,英伟达发布全新NVIDIA Vera CPU机架。
该机架搭载256台液冷Vera CPU,提供400TB内存、300TB/s内存带宽,集成64颗BlueField-4 DPU,全面兼容Vera Rubin与MGX生态系统。

英伟达已完成初步芯片测试,Vera在各类工作负载上的性能提升从2倍到超过5倍不等。
4、BlueField-4 STX存储机架
随着智能体应用规模扩大,数据需求也在膨胀。
传统数据中心提供大容量的通用存储,但缺乏AI智能体所需的即时响应能力。随着上下文窗口增长、AI能力提升,传统存储路径和数据通路会拖慢AI推理速度、降低GPU利用率。
为此,英伟达推出全新的BlueField-4 STX存储机架。

这是一个原生存储基础设施,基于BlueField-4 DPU,结合Vera CPU和ConnectX-9 SuperNIC,可将GPU内存无缝扩展至POD计算集群中。
STX提供了一种高带宽共享层,用于存储和检索大语言模型及智能体AI工作流所产生的海量KV Cache数据。
该机架可实现能效比提升至4倍,企业数据翻页速率提升至2倍,同时让AI工厂的上下文记忆每秒token处理速率快5倍。
5、Spectrum-6 SPX以太网机架
Spectrum-6 SPX以太网用于全数据中心横向扩展的互连网络,让以上所有系统连成整体。

与传统可插拔收发器相比,带有共封装光学器件(CPO)的Spectrum-X以太网光子技术实现了多达5倍的光学功率效率和10倍的弹性。
6、发布Vera Rubin DSX AI工厂参考设计和Omniverse DSX数字孪生蓝图
要在数据中心部署上述全新计算集群和架构,必须考虑如何运营,并帮助整个数据中心生态系统实现效能提升。
因此,英伟达发布Vera Rubin DSX AI工厂参考设计,这是一个AI基础设施蓝图,概述了如何设计、构建、操作整个AI工厂基础设施堆栈,可最大限度提高每瓦token和整体实际吞吐量,提高系统弹性并加快首次生产的时间。
基于Rubin平台部署DSX架构后,AI工厂能在固定功耗下,实现能效比提升30%,同时增加30%的AI算力部署规模。

NVIDIA Omniverse DSX蓝图现在提供NVIDIA Vera Rubin DSX AI工厂参考设计,为大型AI工厂设计和模拟提供数字孪生。
开发者通过以下几个API接入:
DSX Sim,用于物理、电气、热力和网络仿真;
DSX Exchange,用于AI工厂运营数据交换;
DSX Flex,用于电网与数据中心之间安全的动态功率管理;
DSX Max-Q,用于动态最大化Token吞吐量。
7、NVIDIA RTX PRO 4500 Blackwell服务器版
在GTC期间,英伟达还发布了NVIDIA RTX PRO 4500 Blackwell服务器版,为全球应用广泛的企业数据中心和边缘计算平台(包括本地部署和云端)带来多工作负载GPU加速功能。
8、Vera Rubin AI太空计算模块
“我们已经进入太空了,”黄仁勋说,“我们有抗辐射的GPU,我们在卫星上进行成像。未来,我们还将在太空中建造数据中心。”
这很复杂,所以,英伟达正与合作伙伴研发一款新型计算机,称作NVIDIA Space-1 Vera Rubin Module,将发射入轨并在太空中建立数据中心。
这是一款面向太空优化的AI计算模块,支持实时感知、决策和自主运作,将数据中心级AI计算性能带到轨道数据中心、地理空间智能和自主空间与运营。

在太空中没有传导、没有对流,只有辐射散热,所以必须想办法冷却这些系统,英伟达有很多优秀的工程师正在研究。
二、发智能体工具包、桌面级AI超算,全方位助攻安全“养龙虾”
随着OpenClaw爆火,智能体的“ChatGPT时刻”已经来临。
黄仁勋评价说,OpenClaw是人类历史上最受欢迎的开源项目,仅仅几周内就做到,超越了Linux用30年取得的成就。
在他看来,OpenClaw开源了,本质上就是一个“智能体计算机的操作系统”,与Windows使得PC得以实现没区别,如今,OpenClaw使个人智能体的创建得以实现。
因为OpenClaw的吉祥物是一只红色龙虾,中国开发者更喜欢用“龙虾”来称呼这个智能体,并将部署OpenClaw称作“养龙虾”。
“全民养虾”热潮正推动算力需求呈数量级增长,但也存在可能自主访问敏感数据、滥用已连接的工具或自行提升权限等风险。
对此,英伟达发布了多款智能体工具及硬件设备,来帮助开发者更高效、更安全地“养龙虾”。
1、为OpenClaw设计的NemoClaw
英伟达正与OpenClaw创始人Peter Steinberger合作,汇聚世界上最优秀的安全和计算专家,将OpenClaw改造为OpenClaw企业版,使其具备企业安全性和企业隐私能力。
这被称为英伟达OpenClaw参考设计——Open NeMoClaw。

只需一条命令(command),NemoClaw就能用英伟达智能体工具包软件来优化OpenClaw,将NVIDIA Nemotron模型、NVIDIA OpenShell运行时一并安装,通过OpenShell提供开放模型和一个增强智能体隐私安全性的独立沙盒环境。
这为智能体提供了按照预定隐私和安全护栏开发新Skills、完成任务的基础,使用户能在企业内部安全地保护和约束“龙虾”的执行。
NemoClaw可运行于各类专用平台,包括云端、本地部署、RTX PC和笔记本电脑、DGX Station和DGX Spark超算等,确保智能体拥有持续构建软件工具、完成任务所需的专属算力。
2、英伟达智能体工具包
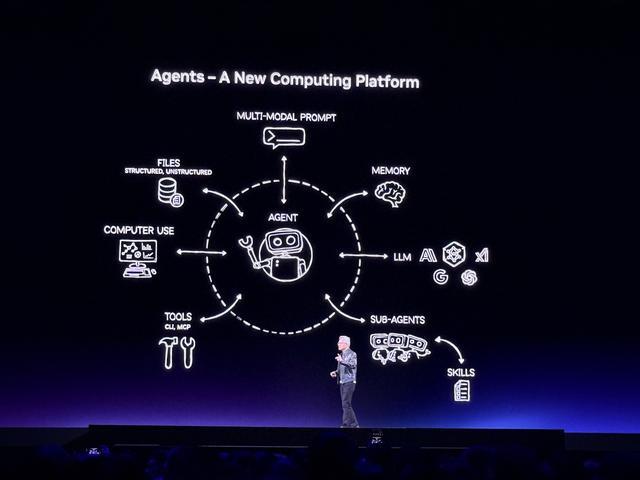
英伟达智能体工具包(NVIDIA Agent Toolkit)是一套开放模型、运行时和蓝图的集合,用于构建、评估和优化更安全的长期运行自治智能体。
该工具包以覆盖推理、编码、文档智能、语音和视觉领域的高效开放模型Nemotron为起点,配备NeMo用于智能体的性能分析、定制与优化,NIM提供模型推理服务,Dynamo负责规模化扩展。
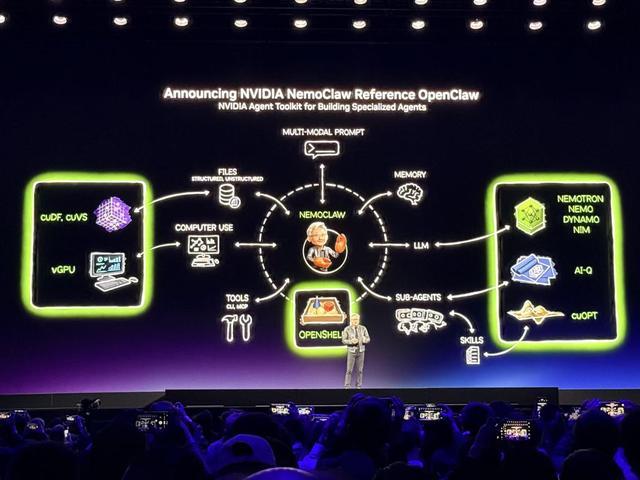
智能体需要各种Skills。其中NVIDIA OpenShell是一款面向智能体的新型开源安全与防护运行时,提供了“龙虾”缺失的基础设施层,通过基于策略的安全、网络和隐私护栏进行管控。AI-Q是一个开源蓝图,融合前沿模型与开放模型的智能,打造全球领先的面向长期工作流的研究型智能体,且运行高效。
软件的世界已经改变。英伟达认为,每一家SaaS(软件即服务)公司,都将被重塑为AaaS(智能体即服务,Agent as a Service)。企业不再销售工具,而是出租使用其工具的智能体。
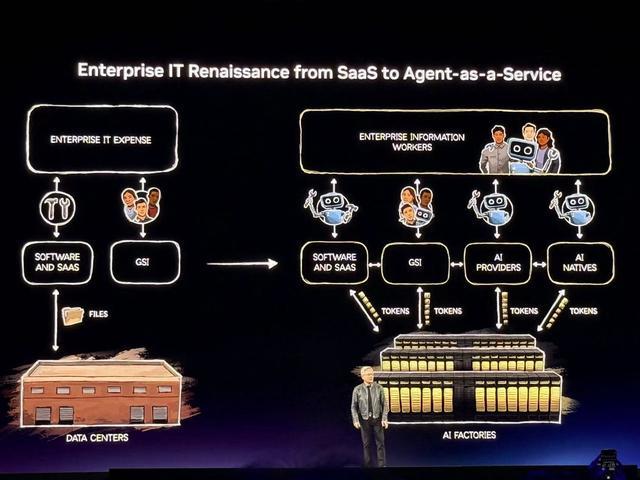
英伟达正在帮助全球软件企业完成这一转型,支持他们基于英伟达智能体工具包构建智能体。LangChain是开发者构建智能体的首选框架,下载量超过10亿次,今日宣布推出与英伟达合作构建的企业级智能体AI平台。
3、两款“养龙虾”设备:DGX Spark与DGX Station
构建好智能体之后,下一个问题就很简单了:在哪儿运行?
它们可以在云端或AI工厂中运行,但很多开发者更倾向于在完全可控的本地环境中开发。
因此,英伟达推出两款适合运行NemoClaw的云端开发者平台:个人AI电脑DGX Spark和全球最快桌面级AI超算DGX Station。
DGX Spark旨在让云端开发更具普惠性,可以运行安全、常驻的自治智能体。多项DGX Spark更新发布,支持将最多4个系统集群到统一配置中,并支持GTC大会上发布的最新AI模型。
基于GB10的DGX Spark及OEM合作伙伴系统今日起在全球正式开售。
DGX Station是终极云端开发平台,让开发者能直接在办公桌上本地构建、微调和运行具备前沿智能水平的模型。这意味着开发者可在自己的机器上构建并运行“龙虾”,无需连接云端,全程保持本地化,实现开发过程中的完整掌控与安全保障。
DGX Station将于今日起向OEM合作伙伴开放订购。
三、一大波开放模型上新,涉及智能体、物理AI和医疗健康
开放模型对AI生态发展至关重要。
作为全球最大的开源AI贡献者之一,英伟达构建并发布六大系列的开放前沿模型及训练数据配方和框架,帮开发者定制和采用。

Nemotron 3 Ultra是最强开放基础模型,在英伟达自有基础设施上完成预训练,吞吐量是此前最佳开放模型的2倍。
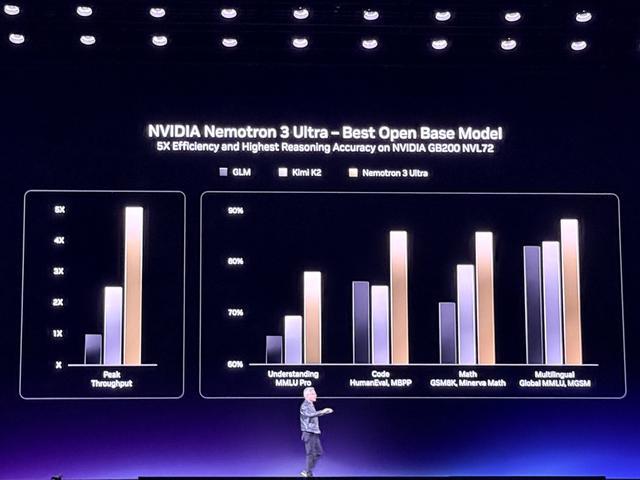
Nemotron 3 Omni具备音频、视觉和语言理解能力,可支持智能体从视频和文档中高效提取信息。Nemotron 3 VoiceChat支持实时对话,把自动语音识别、大语言模型处理和文本转语音功能结合在一个系统中。
上周先一步发布的Nemotron 3 Super模型是英伟达迄今最强推理模型,在其同量级中智能水平最高、效率最优,在BFCL(伯克利函数调用排行榜,专门评估大模型作为智能体大脑的能力)中登顶开源模型第一,综合排名全球第四。
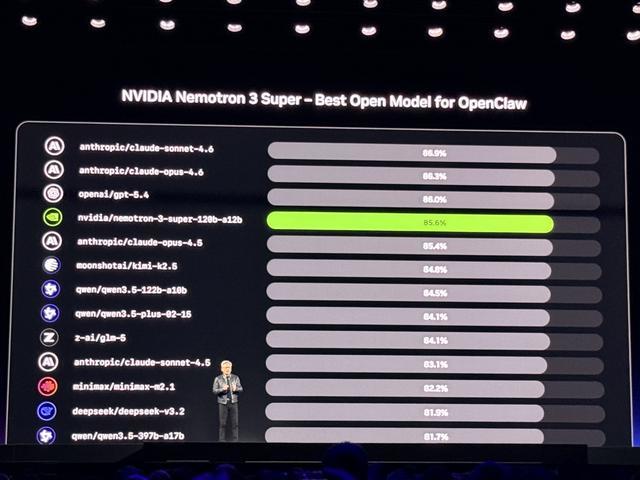
面向物理AI和医疗健康AI的全新开放模型包括:
NVIDIA Cosmos 3,第一个统一合成世界生成、物理AI推理和动作模拟的世界基础模型。
NVIDIA GR00T N1.7,一个专为人形机器人构建的开放推理视觉语言动作(VLA)模型,在现实世界中部署具有商业可行性。
NVIDIA Alphamayo 1.5,一个面向自动驾驶汽车的一种推理VLA模型。
NVIDIA BioNeMo Proteina-Complexa,一个用于蛋白质结合体设计的生成模型,可加速基于结构的药物发现和治疗。
以上模型均已在Hugging Face上发布。
黄仁勋还预告了GR00T N2,这是一个基于DreamZero研究的下一代基础模型,预计将于今年年底发布。
该模型构建于新的世界动作模型架构上,帮助机器人在新环境中成功完成新任务的频率是领先VLA模型的2倍多。

此外,英伟达宣布成立Nemotron联盟,联手Black Forest Labs、Cursor、LangChain、Mistral、Perplexity、Reflection、AI Star、Bomb、Thinking Machines Lab等顶尖AI实验室,汇聚专业知识、数据、评估体系和模型开发能力。

英伟达将使用内部DGX Cloud算力统一承担训练工作,避免每家机构在相同基础模型上重复投入,共同构建开放的共享基础。
开发者和企业随后可在此基础上,针对各自的行业、地区和应用场景进行专项定制。
联盟的第一个项目是一款全新的基础模型,正在英伟达DGX Cloud上训练,将成为即将发布的Nemotron 4系列的基础。
四、物理AI:工业软件、机器人龙头都在用,公布L4自动驾驶、太空计算新进展
整个IT行业只有2万亿美元,而世界上其他所有行业,都需要能与真实世界交互的AI,需要能够理解、建模并与真实世界交互的AI物理模型。
从桌面到机器人、自动驾驶汽车,从AI工厂到电信网络,英伟达的AI基础设施已无处不在。
1、物理AI数据工厂蓝图
在机器人领域,算力即数据。当前的数据生成工作流极为碎片化,数据处理、生成、仿真、评估和部署分散在不同管道中。
对此,英伟达推出物理AI数据工厂蓝图,一个基于英伟达Cosmos世界模型和Osmo机器人算力编排系统的开放参考架构,让“用仿真数据大规模训练机器人”这件事有了标准化管线。
英伟达正是用这套管线构建了Alphamaya、Cosmos和GR00T等前沿开放模型。
微软Azure和Nebius是首批采用该架构的云服务商,首批客户包括Field AI、Hexagon Robotics、Milestone Systems、Skilled AI和Teradyne Robotics。
2、机器人企业们都在用英伟达计算平台
英伟达为机器人制造商提供三类计算平台,以及开放模型、库和框架,可按需组合使用。
英伟达宣布,全球众多顶级机器人企业都在这三类计算平台上进行构建:ABB、FANUC和库卡合计占全球工业机器人装机量近半,均已将Omniverse库集成至其机器人仿真工具中。
Figure、智元机器人、1X等人形机器人企业采用Isaac Lab、Newton和Cosmos等机器人仿真库进行构建,并采用Jetson和Thor进行边缘推理。
AI原生企业如Skilled AI和Field AI均在英伟达Isaac和Cosmos技术栈上构建其通用机器人大脑。
英伟达是目前唯一一个每家机器人公司都在构建于其上的计算平台。
3、L4自动驾驶出租车试点,扩展软件安全
自动驾驶汽车是物理AI大规模落地的第一个场景,也是全球首次大规模部署机器人。
英伟达构建了全球唯一的全栈自动驾驶平台NVIDIA DRIVE,覆盖自动驾驶训练与验证所需的架构、安全系统和AI基础设施。
其核心是NVIDIA DRIVE Hyperion,一款支持L4级自动驾驶的整车参考架构,集成计算、传感器和软件,可供整个自动驾驶生态系统构建。
自动驾驶的使命是安全,英伟达宣布推出L4自动驾驶汽车的统一软件安全基础NVIDIA Halos OS、开放推理VLA自动驾驶模型的全新版本NVIDIA Alphamamya 1.5,用于自动驾驶仿真的Omniverse NuRec也普遍可用了。
英伟达DRIVE生态系统正在持续扩大。比亚迪、吉利、日产等多家全球车企新近加入,采用DRIVE Hyperion,开发下一代L4自动驾驶程序。
Uber全球L4无人驾驶出租车将采用DRIVE Hyperion,基于英伟达全栈DRIVE AV软件运行无人驾驶网络,计划于2027年在洛杉矶和旧金山启动试点,2028年底前扩展至四大洲28座城市。
4、全球工业软件巨头都在用英伟达AI
英伟达宣布Cadence、Dassault Systèmes、西门子、新思科技等主要工业软件厂商将英伟达AI、开放模型、CUDA-X、Omniverse和GPU加速工业软件及工具带到现代、本田、奔驰、联发科、百事可乐、三星、SK海力士、台积电等公司,以加速设计、工程和制造。
这些软件领导者们还推出了由英伟达驱动的智能体解决方案,用于复杂的芯片和系统工具流。
例如,本田正使用新思科技的Ansys Fluent在英伟达Grace Blackwell上运行空气动力学模拟,速度比使用CPU快了34倍。
5、英伟达、T-Mobile等将物理AI应用部署到AI-RAN基础设施
英伟达和T-Mobile宣布正与诺基亚合作,将物理AI应用部署到AI RAN基础设施。
电信网络正在演变成AI基础设施。T-Mobile试点NVIDIA RTX PRO 6000 Blackwell服务器版AI基础设施,补充AI-RAN创新中心的分布式网络,以充分发挥物理AI的潜力。
基于英伟达加速计算的AI-RAN过渡解决了物理AI扩展的关键瓶颈:缺乏低延迟、安全和无处不在的连接。
虽然Wi-Fi受到覆盖范围和安全性的限制,但T-Mobile的5G独立网络为复杂AI智能体提供了广泛的覆盖和保证服务质量。
结语
5套机架级系统、7款量产芯片、1套完整智能体开发软硬件、覆盖自动驾驶/机器人/工业/边缘/太空的物理AI布局……黄仁勋用2小时信息量爆棚的演讲,绘制出一张通往未来的AI基建施工图。
在这张图里,英伟达的目标始终如一:垂直整合,横向开放,确保每一个AI系统,无论运行在哪里、做什么、规模有多大,都跑在英伟达的平台上。
未来已来,智能体大爆发正推动难以置信的计算需求。在这个AI新世界里,算力即金钱。从桌面、机器人、汽车、工厂到数据中心甚至到近地轨道,每一层都有英伟达的算力在运转,每一个token的生成都在为它的收入计数。
通过收购Groq LPU技术增强推理优势,用开源顶尖模型激励更广泛的算力需求,以全栈布局和提高工具易用性来垒高用户的迁移成本,英伟达走得每一步棋,都堪称教科书级。
英伟达是克制的,它坚持做基建商,不碰下游客户的分毫蛋糕。英伟达又是贪婪的,这种贪婪驱动它以极强的战斗力向前狂奔,为自己创造更庞大的未来市场,又以一种高明的长期主义,把各行各业的头部企业引入自己的生态轨道,把客户的成功变成自己的护城河。
最后,附上GTC 2026黄仁勋主题演讲片尾曲的歌词,来总结下本届GTC的重点:
The keynotes over, all was said Jensen mapped the road ahead.
主题演讲落幕,该说的都已讲完,黄仁勋为我们铺好了前路。
AI factories coming alive, agents learning how to drive.
AI工厂全面苏醒,智能体学会自主行动。
From open models to robots too now we break it all down for you.
从开源模型到机器人世界,现在我们为你拆解这一切。
Compute exploded, what we saw from CNN’s to OpenClaw.
从卷积网络到OpenClaw,我们亲眼见证算力大爆发。
Agents working cross the land but they need the power to meet demand.
智能体遍布各地但它们需要强大算力才能满足需求。
So we solved the problem, It was brilliant.
于是我们解决了难题,方案堪称绝妙。
We multiplied compute by forty million.
我们把算力提升了4000万倍。
Once upon an AI time training was the paradigm.
曾经的AI时代训练是核心范式。
Sure it taught the models how, but inference runs the whole world now.
它教会模型如何学习,但如今推理才是驱动世界的引擎。
Vere shows us who’s the boss at thirty-five times less the cost.
Vere告诉世界才是真正王者,成本降到1/35。
Blackwell makes the tokens sing NVIDIA, the inference King.
Blackwell让Token放声歌唱:英伟达,推理之王。
AI Factories once took year vendors pulling racks and gears.
AI工厂曾经耗时经年,厂商们堆砌机架与配件。
Built up slowly, piece by piece no clear way to scale the beast.
一点点缓慢搭建,却找不到规模化的路径。
DSX and Dynamo know what to do turning power into revenue.
DSX与Dynamo指明方向把算力直接变成营收。
Agents used to wait and see now act autonomously.
智能体过去只会观望等待。
But if they ever try to stray safe Claws block and say ‘No Way!’
如今可以完全自主行动,可一旦它们试图越界,安全Claw会阻拦:“绝对不行!”
NemoClaw’s there to guard the course and yes, my friends…
NemoClaw守护全程航向,而且,朋友们……
It’s open source.
它还是开源的!
Cars that think and droids that run this ain’t the movies, it’s all begun.
会思考的汽车,能奔跑的机器人,这不是电影,一切已经开始。
Alpamayo calls the shots it’s a GPT moment for the bots.
Alpamayo掌控全局,这是机器人的GPT时刻。
From sim to streets, now watch them drive throw your hands up for Physical AI.
从仿真到街头,看它们驰骋,为物理AI振臂高呼。
The Industrial Age built what came before now we build for AI even more.
工业时代铸就了过往,如今我们为AI再造新章。
Vera Rubin plus groq make the inference splash put them together,now it’s raining cash.
Vera 加上Groq掀起推理狂潮,两者强强联手财富如雨降临。
We build new architecture every year because Claws keep yelling, ‘More tokens here!’
我们每年都打造全新架构,因为“龙虾”不停呐喊:“这里需要更多token!”
The AI stack’s for all to make so let us all eat five layer cake.
AI技术栈由所有人共同创造,让我们共享这五层蛋糕。
The moment’s bright, the path is clear because open models led us here.
此刻光芒万丈,前路清晰坦荡,是开源模型带领我们抵达远方。
When data’s missing, there’s no dispute we just generate more with compute.
当数据缺失时毋庸置疑,我们用算力生成更多数据。
Robots learning without a flaw fueling the four scaling laws.
机器人完美学习无差错,驱动四大增长定律。
The future’s here, won’t you come and see?
未来已来,你难道不想亲眼见证?
Welcome all to GTC.
欢迎所有人来到GTC大会。
