编者按:
智能手机统治了过去十几年的数字生态,它是注意力的黑洞,是我们最私密的随身之物。但手机从设计之初就是为「人盯着它」而生的——它的全部逻辑,都止于屏幕。
AI 的需求却恰恰相反:它需要持续感知物理世界——见你所见,听你所闻,随时在场,而非等你解锁屏幕才醒来。
当 AI 真正成为一种基础能力,它迟早要从屏幕里破壳而出,寻找属于它自己的形状。这将是一个漫长的探索和演化过程。
「AI 器物志」栏目由此而来,爱范儿想和你一起持续观察:AI 如何改变硬件设计,如何重塑人机交互,以及更重要的——AI 将以怎样的形态进入我们的日常生活?
这是「AI 器物志」的第 6 篇文章。
年初,Mac Mini 一度缺货,等待时间甚至长达一个半月。
Mac mini 是个好产品,这件事大家一直很清楚。国内渠道价格诚意高,M 芯片性能又好,入门配置不到三千人民币就可拿下,很适合作为创作新手的主力机。
然而最近这次 Mac mini 爆红,跟创作或日常使用没什么关系。
关注科技新闻的朋友们应该知道怎么回事:OpenClaw(前身叫 Clawdbot)突然火了。
OpenClaw 有多种部署方式:你可以装到自己的电脑上,也可以单给它配一台电脑;把它部署在云端的虚拟机/沙箱环境里也没问题;后来,一些主流 AI 服务也推出了云端一键部署的替代方案,显著降低小白玩家的门槛。
但在刚开始的那段时间,最主流的部署方案就是单买一台 Mac mini。

理由肯定不是因为它便宜,更主要在于:要让 OpenClaw 有意义,需要给它一个「肉身」,让它访问文件、操作软件。
云服务器能运行 OpenClaw,但那仍然不是你的电脑,没有你的文件、软件、浏览器上登录的各种账号,没有所谓的「上下文」。Mac mini 放在桌上,7 × 24 小时不用关机,甚至通过聊天机器人远程操控的话都不用单配一台显示器。
给 OpenClaw 一台自己的电脑工作,唯一可观成本是后端接入的大模型 API 的 token 费用,很多早期玩家都在这上面吃过亏。但如果你买一台配置够高的 Mac mini,下载一个尺寸足够大的模型到本地来运行,可以说除了电费和网费之外,简直就像获得了一个免费的劳动力……

MacBook 也行,但是……
据 Tom’s Hardware 和 TechRadar 等媒体报道,OpenClaw 走红后,Mac mini 24GB 和 32GB 配置的等待期延至 6 天到 6 周不等;更强大的 Mac Studio,交货时间也从两周涨到了近两个月。
这些等待时间,是 OpenClaw 的早期玩家们,用真实购买投出来的票。
(注:部分机型的缺货也和苹果近期推出新款 Mac 台式机电脑有关系,以往每次推出临近新机发布时,老机型都会进入售罄状态。OpenClaw 的爆红并非唯一原因。)
冥冥之中,Mac 成为了 2026 年首选的「AI PC」;反倒是鼓吹了「AI PC」好几年的 Windows PC 行业,一点热乎的都没吃上。
英特尔、AMD、高通等芯片商,以及主流 PC 品牌们,从 2023 年就开始贩卖「AI PC」的概念了。这些最新的 Windows 电脑当中,认证过 Copilot+ PC 的比比皆是,GPU、NPU 性能并不差,有的整机价格比 Mac 对等产品要便宜的多。
但问题是,为什么大家还是一窝蜂地冲向 Mac?

为什么是 Mac?
Windows PC 和 Mac 谁更好的争论,永远没有绝对答案。但如果限定在 AI 开发上,Mac 成为了心照不宣的选择。
虽然大模型的「大脑」都在云端服务器,开发者的手却都在 Mac 上。这跟 Mac 电脑的外形和操作体验关系不大:macOS 流着 UNIX 的血液,才是关键。
AI Agent 的核心工作是操作文件、调用命令行工具、调度 API 甚至控制图形界面等。说的更直白一点,Agent 就是一个智能且自动化的「脚本工程师」,只是脚本由大语言模型实时生成。而 macOS 属于类 UNIX 系统,bash、zsh 命令原生支持优秀。
这解决了 AI 开发中最基础的环境搭建。在 Windows 上,你可能得先安装 WSL2 虚拟机。但在 Mac 上,从 Python 环境到复杂的 C++ 编译工具链,基本都是开箱即用。Homebrew 等包管理器,让安装各种工具和依赖通过一行命令就能搞定。
另外,macOS 符合 POSIX 标准,处理文件路径、多线程任务和网络协议时可靠性稍高。Agent 往往需要频繁读写数据、调用 API,系统级的高效调度让 agent 在 Mac 上的节奏更快。
这种原生感和稳定性,让开发者、尝鲜用户可以更快完成入门,把更多时间花在真正的 agent 编排工作上。
Windows 有 WSL、PowerShell,功能上大部分也都能覆盖。但 WSL 是叠加在 Windows 上的兼容层,存在路径约定、注册表机制、权限模型等历史遗留问题。AI 模型和 agent 项目在 Windows 上运行的摩擦,确实会更多一些。
以 Ollama 和 LM Studio 为例,这两个工具让端侧推理大模型变得像「下载、安装、运行」一样简单。Ollama 的 Windows 版比 macOS 晚了半年;LM Studio 虽然从一开始就支持两个平台,但在社区里 Mac 的体验口碑始终更好;OpenClaw 也是如此。
往硬件层面继续深入,内存是大语言模型推理运行的命脉。
还是以 OpenClaw 举例,用户可以通过 token 付费的方式来接入云端模型,但它更擅长的能力是在端侧模型推理驱动。经过普遍调研,想要让 OpenClaw 像个智商合格的人一样工作,后端的模型参数量的底线在 70 亿左右,往往要上到至少 320 亿参数量才能比较稳定地工作。
这么大的模型即便在 4-bit 量化之后,仍然需要大约 20GB 内存(还要留一些给上下文窗口)。
此时,Windows PC 的架构会显得捉襟见肘。CPU 内存和显存之间存在物理隔离,数据经由 PCIe 总线传输,受到带宽瓶颈的影响。频繁的数据搬运,会对推理过程带来速率的影响。
更别提,大模型普遍依赖 GPU 加速推理,显存得足够装得下模型。在英伟达消费级显卡线中,只有 90 后缀的 24GB 显存达到了配置要求,但配出整机(只考虑新机)的话合计成本至少在万元人民币以上,用新卡的话会飙到 4、5 万不等。

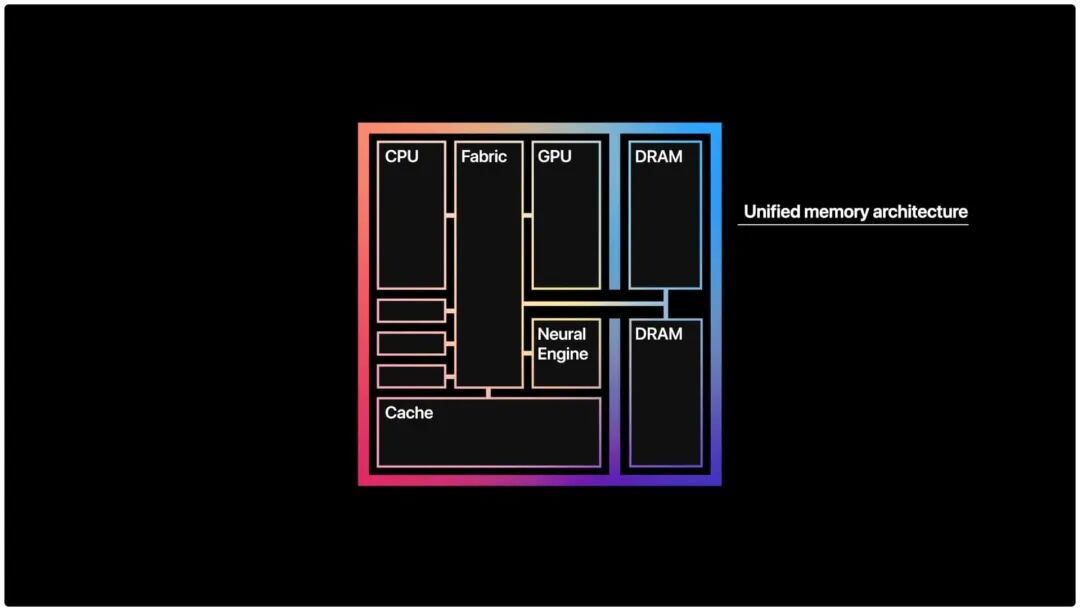
而苹果的统一内存架构 (Unified Memory Architecture) ,让 M 系芯片的 Mac 在端侧推理更大规模的模型时游刃有余。
简单来说,统一内存架构的效果,是 CPU、GPU、神经计算引擎能够共享同一个内存池,不再有物理总线搬运的损耗,让 Mac 可以获得极高的内存带宽,并且对于多机串联的扩展性能更好。
以 Mac mini 为例,选择性能更高的 M4 Pro 处理器,搭配 48GB 内存,其它选基础配置,整机价格在 1.3 万元上下,即可达到 OpenClaw 社区普遍推荐的 320 亿参数量模型的配置水平。
当然这还只是对 token 吞吐速度有要求的专业配置。如果你属于爱好者、尝鲜玩一下 OpenClaw,配置下降到常规 M4 芯片和 32GB 内存也是能跑起来的。
当然,这个成本对比还是有前提:专用于端侧推理/跑 OpenClaw,而不是当做主力机。同等价位的 Windows PC 还能打游戏、剪视频,通用性更强。
另外,Mac 的统一内存和 PC 平台独显的显存也不是一回事。统一内存由系统和模型共享,一台 32GB 内存的 Mac mini,macOS 系统和其他软件仍需占据几个 GB。而 RTX 3090 的显存独立,模型可以全部占用,甚至配合 CPU 内存跑更大的量化模型。
如果你只用云端 API 做 OpenClaw 的大脑,不考虑端侧部署,那 Mac 的易用性优势依然在。
另外,CUDA 虽然提供了统一内存编程接口,但物理上 CPU 内存和 GPU 显存依然分离,数据搬运和带宽瓶颈并未消除。
再来看功耗。
Agent 的工作方式是持续循环的:任务触发、思考推理、执行、等待、再触发。前述配置的 Windows PC 会跑到 300-400W 左右(本地部署),散热噪音和电费都不是小数目。
Mac mini 通常稳定功耗在 10-40W 左右,峰值功率 65W(M4)或 155W(M4 Pro),散热可控,几乎没有风扇噪音,运行更安静。这种低延迟、低功耗的持续工作方式,会产生潜移默化的体验差异。

网友 3D 打印的套件「Clawy MacOpenClawface」
当然我们更多还是围绕 OpenClaw 这个以推理为主的场景进行讨论。如果工作涉及本地微调,并且对于效率有追求的话,那么在 macOS 平台要往往要到 Mac Studio,或至少顶配的 MacBook Pro,才能算摸到门槛。
与此同时,Mac 不支持 CUDA 也是个可能永远都无法改变的事实。不过,CUDA 的真正战场是模型训练,推理场景对它的依赖小得多,毕竟苹果在推理上有 MLX 这张王牌(后面会详述)。
再回到 OpenClaw:它的创造者 Peter Steinberger 曾经公开表示,自己很喜欢 Windows,觉得它的功能更强。他在 Lex Fridman 播客中说,Mac mini 不是唯一的「肉身」选择,通过 WSL2 方式运行 OpenClaw 已经非常成熟了;他甚至公开吐槽苹果在 AI 领域「搞砸了」,并且对苹果生态的封闭性感到不满。
但客观来讲,对于技术小白型用户的部署门槛,Mac mini 确实是最省心、最容易上手的方案。主要原因就是它的功耗、静音、尺寸足够小,像是一个可以插在墙角、24 小时待机且不需要维护的「服务器节点」。
还有一个和功耗有关的例证:前几天有一位工程师 Manjeet Singh 成功实现了对 M4 处理器上「神经引擎」(Neural Engine,简称 ANE)的逆向工程,发现 ANE 的功耗效率极高:算力跑满时的效率高达 6.6 TOPS/W。
对比苹果的 M4 GPU,约合 1TOPS/W;英伟达 H100 大约 0.13,A100 是 0.08 TOPS/W。
折算一下,A100 单卡的吞吐性能是 M4 ANE 的 50 倍,但 M4 ANE 的功耗性能却是 A100 的 80 倍。原作者在文章里写道:对于端侧推理,ANE 的性能是非常出色的。

由神经引擎说开
2011 年,苹果在 A5 处理器的图像处理单元 (ISP) 中首次通过硬写入的方式,实现了人脸实时检测等后来被视为 AI 任务的功能。
2014 年,苹果收购了 PrimeSense 公司,并开始研发一种全新的、专门用于神经网络计算的协处理器。这方面的工作在三年后的 iPhone X 上问世:A11 Bionic 处理器当中加入了前面提到的神经引擎 ANE,算力只有区区 0.6 TOPS,用来驱动 Face ID 和拍照人像模式。
那时 AI 还没到大模型时代,跑的主要是各种机器学习算法。市场对苹果这块协处理器的推出并没什么特别的反应。但苹果从未放弃过,持续加码。
三年后,M1 发布,统一内存架构同时到位, ANE 也进驻了 Mac。桌面平台的功率预算更充足,也让 ANE 的算力跳到 11 TOPS。此后每代更新:M2 是 15.8 TOPS,M3 是 18 TOPS,M4 是 38 TOPS,到了 2025年底的 M5 ,达到了 57 TOPS。从 M1 到 M5,苹果的 ANE 算力涨了超过 5 倍。

这个增长背后的逻辑,其它 PC 厂商不能说不羡慕。苹果为 Mac 加入 AI 加速硬件之前,已经有数千万甚至上亿台 iPhone 在跑同一套 ANE 架构了。功耗表现、稳定性、极端情况下的边缘案例,在市售机型上已经得到验证,再搬到 Mac 上来。
英特尔和 AMD 在移动端几乎没有消费级规模;高通虽然同样把 Snapdragon 芯片放进了数亿台 Android 手机,但它只是芯片供应商。Android 上的 AI 是谷歌 (Gemini) 以及各大手机厂商联合第三方 AI 实验室做的;Windows 的 AI (Copilot) 是微软做的。
苹果的不同在于,它实现了垂直整合,同时掌控硬件和软件。其他芯片厂商没有这种统一控制权。
当然,在 Mac 上推理大语言模型,其实跟 ANE 没什么关系,它更擅长处理 Face ID、人像识别这类固定模式的 AI 任务。真正承担主要计算量的是 GPU。
(注:最近情况发生了细微的变化。首先,M 系列芯片上的 ANE 已经承担提示词注入 prefill 阶段的工作了;以及刚才提过的 M4 ANE 逆向工程:该工程师还实现了跳过 CoreML 直接调用 ANE,吞吐量显著提升。通过这种思路,或许可以找到直接利用 ANE,来加速推理甚至训练的通用方法。)
2023 年底,苹果开源了 MLX,把专门针对 M 系列芯片优化的模型推理框架直接给了开发者。去年,基础模型框架随 Apple 智能发布,App 开发者可以在 iPhone 和 Mac 上调用系统内置的基础模型,无需联网,数据不离开设备。
Apple 智能一再跳票,这件事确实没什么好辩护的。不过,苹果远在 10 年前就开始试水,在多年以前就为桌面级 AI 开发打下了基础,是不争的事实。
而在 Windows 那边,「AI PC」这个词开始出现在英特尔、AMD 和 PC 厂商的新闻稿和 ppt 里,要到 2023 年底了。
2024 年 5 月,微软发布 Copilot+ PC 认证体系,旗舰功能名叫「Recall」,大概的逻辑是系统持续对屏幕内容截图,然后 Windows 的系统级 AI 能够帮你回忆过去看到过的东西。
先不说这个功能在发布当时的实际意义是什么,它的安全性首先被发现有严重问题:仅在发布一个月后,研究人员就发现 Recall 功能会把所有截图存在一个未加密的本地明文数据库里。
微软紧急撤下了 Recall 功能。过了半年微软再次推出测试版,结果再次因为新的安全问题而延迟。直到 2025 年 4 月,Recall 才正式上线,但改成了默认关闭,启动后数据改为加密存储。

从发布会宣传到真正能用,将近一年,可以说整个 Windows 生态 AI PC 的旗舰功能,经历了一整次从头重新设计,尴尬程度其实不亚于 Apple 智能/新版 Siri 的一跳再跳,但可能因为 Windows 生态的声量实在太低,AI PC 没多少人关注,很多人都没听说过这回事。
在 Copilot+ PC 这个体系的认证标准方面,微软主要针对的是神经处理引擎 NPU,要求是 40TOPS。不过,这个算力的用途是实时字幕、背景虚化、照片增强,诸如此类的消费端窄任务,大语言模型推理从来不在它的射程里(和苹果 ANE 同理)。
当开发者尝试去做端侧大语言模型推理时,会发现虽然这些电脑名为 AI PC,但并没针对 AI 推理用途做什么优化。微软 Copilot 本身的核心算力来自 Azure 云端,和端侧自身的算力几乎无关。买了一台 Windows AI PC 的用户,最能感知到的 AI 提升,大概是实时字幕和照片自动分类。

说到端侧推理,还有一个关键因素:Windows AI 生态的优化路径是分散的。
NVIDIA GPU 用 CUDA 和 TensorRT,Intel NPU 用 OpenVINO,高通 NPU 用 QNN SDK,AMD NPU 用自家驱动栈。模型存储格式也较为碎片化,有 CPU+GPU 推理的通用格式(GGUF,准确来说是 CPU 推理 + GPU 分层卸载),也有 GPU-only 的格式(EXL2)。
这意味着想让模型以及模型驱动的功能运行在 Windows AI PC 上,在推理后端方面的工作会更加复杂。微软有 ONNX Runtime 和 DirectML(已进入续命状态)作为统一抽象层,但统一的代价是牺牲各厂商的峰值性能。苹果是目前唯一一家为自家 PC 硬件专门开发并持续维护 LLM 推理框架的 PC 厂商,这个框架就是 MLX。
在 Hugging Face 等开源模型平台上,你会很容易找到大量采用 MLX 框架的模型,只要带有 MLX 后缀,并且内存/处理器允许,可以直接「开箱即用」。
不过,这几天 MLX 的主要贡献者之一 Awni Hannun 刚从苹果离职,为该项目的后续发展增添了些许变数。Hannun 也表示 MLX 团队仍有许多优秀员工,可以放心。
我们自己的体验
过去一年,爱范儿自己做了不少端侧部署 AI 模型的测试,也采访过一些相关的外部开发者。有两次值得一提。
去年春节,DeepSeek 横空出世,新款 Mac Studio 也在节后不久面市。 我们用一台售价快到 10 万元人民币的 M3 Ultra Mac Studio(512GB + 16TB)跑了 DeepSeek R1 671B 模型(注:实际上只需要内存,硬盘不用那么大,1TB SSD 售价七万多的型号就够了),以及蒸馏过的 70B 版本。
我们当时得出结论:对于端侧部署对话,日常用 70B 足矣,花大几万买台机器只为了跟 AI 聊天,实在是有钱烧的慌。当时的模型能力确实也就不太行,后来才有新的多模态模型和 agent 能力出来。
但 671B 模型的天量参数模型能够在一台桌面机上端侧推理,仍然是一种奇观。512GB 的统一内存上,671B 模型占用了 400GB,加上上下文、macOS 系统本身以及其他任务占用,基本接近满载,但机器全程运行安静,噪音在正常范围,也没有过热。
这个参数规模,在传统 AI 基础设施逻辑里,属于数据中心级别,消费级硬件理论上不该出现在这个场景里。但那台 M3 Ultra Mac Studio,真就硬生生也静悄悄地出现了。
后来,我们采访过一个英国牛津大学的创业团队 Exo Labs。他们用 4 台 512GB 统一内存的 Mac Studio,通过串联的方式组成了一个 128 核 CPU、320 核 GPU、2TB 统一内存、总内存带宽超过 3TB/s 的算力集群。

团队为这个 Mac 集群开发了调度平台 Exo V2,可以同时加载 2 个 DeepSeek 模型(V3+R1,8-bit 量化)。不但两个模型并行推理,研究人员甚至可以通过 QLoRA 技术来做一些本地微调工作,显著缩短了训练任务的用时。整套系统功耗控制在 400W 以内,运行时同样几乎没有风扇噪音。
同等算力的传统方案,需要大约 20 张 NVIDIA A100,当时的成本超过 200 万人民币;相比之下,Exo Labs 这套方案的总成本才不过 40 万人民币(同理 SSD 严重溢出,其实可以 30 万内就够)。
Exo Labs 创始人当时告诉我们,牛津有自己的 GPU 集群,但申请需要提前几个月排队,而且一次只能申请一张卡。这些桎梏,逼迫他们创新,而他们又正好遇到了趁手的工具:统一内存架构、MLX,以及 Mac 电脑。
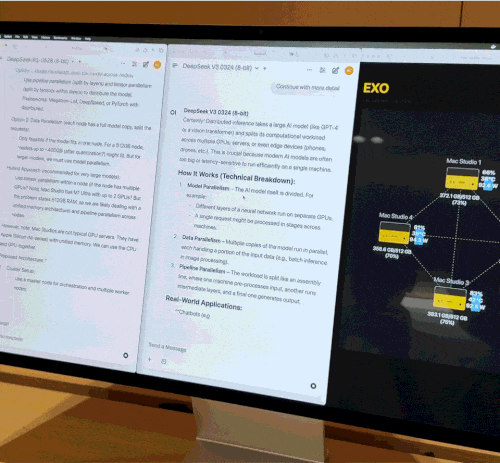
我们在当时的文章里写道:「如果说英伟达的 H 系显卡是 AI 开发的金字塔尖,那么 Mac Studio 正在成为中小团队手中的瑞士军刀。」
这件事,苹果其实早就知道。

真正的 AI PC 是什么?
去年苹果发布的基础模型框架,让 iOS 和 macOS 开发者可以调用系统内置的基础模型,零网络延迟,零 API 费用,数据不离开设备。
尽管后来苹果基模团队几近分崩离析,但在迭代方面苹果没有停在原地。它其实一直知道开发者在哪里、想要什么。它的回应,就是将大模型驱动的 AI 能力变成操作系统的基础设施,让开发者更方便调用。
上周,苹果开源了 python-apple-fm-sdk。以往苹果基模的完整测试和调优,需要 Swift 环境完成;现在这套 SDK 让路变宽了,习惯 Python 工作流的开发者也能参与进来。
苹果的隐私设计哲学贯穿始终:python-apple-fm-sdk 调用的基础模型完全在本地运行,数据不离开设备。苹果整套 AI 体系在必须上云的场景里,走的是 Private Cloud Compute,数据处理完即删除,苹果无法访问。
反过来看 Recall,同样是让 AI 访问用户的私人数据,第一版存的是未加密的明文数据库。一个在架构上阻断泄密,一个是出事了再打补丁。
但话说回来,Mac 作为 AI 开发和部署工具的优势,严格来讲更像是一种「适配度优势」,也可以说是后天意外获得的。
意思是:苹果做神经引擎,最初是为了服务 Face ID 和人像模式;做统一内存架构,是摆脱对 Intel 长久依赖的一部分必要工作;开源 MLX,是响应开发者对高效推理工具的需求——AI Agent 场景爆发,Mac 正好赶上,是上述这些以及更多没提到的工程决策的意外收益。
Mac 一开始并没有为 AI 而设计,它始终的产品定位都更接近「创作者工具」。苹果长久以来的目标用户,是视频剪辑师、艺术家、软件工程师。他们需要的是低噪声、持续性能、高内存容量、可以全天候运行的机器。
AI 模型推理,以及时下最火的 Agent 部署,只是恰好需要一模一样的东西。
回头看,十多年前苹果在机器学习上加大投入时,大概率是不会预见到 2025 年 OpenClaw 的爆红的。甚至你可以说,如果放在十年前,苹果大概率是不会喜欢 OpenClaw 这样一个「回报高风向更高」,一旦出现幻觉就把用户隐私、数据安全抛在脑后,无视各种软件工程方面的规章制度的东西的……
但怎么说呢,如今就算苹果不喜欢它,也由不得了。就像墨菲定律那样,或许冥冥之中有些东西早已注定。多年以来苹果打下的每一张牌,无论有意为之还是出于意外,这些牌在今年这个 Agent 元年(希望这次是真的),成了一套很难不赢的牌组。
2023 年开始力推 AI PC 的 Windows 阵营,其实一直在追赶苹果在 2020 年 M1 推出时就已经定下来的架构优势。当然,25 年苹果在 AI 方面坏消息不断,这个差距是有追上的可能的。但苹果不会停下来等。
就在本周,苹果推出了 M5 Pro 和 M5 Max,芯片采用双芯融合架构 (Fusion Architecture),还在新闻稿中上点名 LM Studio 作为 LLM 性能基准。
苹果过去的硬件新品发布里,不怎么说「大语言模型」,特别是在端侧推理的语境下——现在不一样了。

说在最后
吹了苹果一整篇文章了,我们冷静一下,反问一下文章的标题:今天的 Mac,就是真正的 AI PC 吗?
爱范儿倒觉得,苹果做的还不够。在今天,我们还没有看到一款个人计算产品,可以称之为 AI PC,抑或真正「原生的 AI 硬件」。
还是回到 OpenClaw,从今天的端侧部署 agent 身上,真正的 AI PC 应该长什么样子,其实已经隐约可见。

梗图,AI 生成
在应用层面,面向人类的「应用」概念,可能会部分退化回并无图形界面的状态。毕竟人才需要图形界面,agent 不需要。而且你会发现,最近越来越多人开始习惯基于对话和命令行的互动方式了。
今天 agent 的尝鲜者们,去找工具和技能塞给 agent;未来,agent 会自己去公开代码库拉取新工具和插件来补强自己。
在系统层面,权限体系将为 agent 的工作原理重构,agent 能直接操控各种接口。在底层,会有一套模型的编排调度机制,根据任务随时切换。
本地推理和隐私云端推理也会形成完整、安全、隐私的闭环。数据无论传到哪里,都经过向量化、加密存储,即用即焚……
换句话说,真正意义上的 AI PC,应该是从底层开始,从设计之初,就把 AI 当作「一等公民」的系统。

梗图,AI 生成
按照这样的衡量标准,Mac 和 Windows 目前都处于过渡阶段。Mac 更接近,因为 Unix 环境、硬件统一、生态成熟,这些条件在 AI agent 的时代到来之前已经达成了。Windows 的历史包袱更重,改起来更难,还在补课。
但我们绕了一大圈,其实还没问到最本质的问题:真正的 AI PC,真的需要是一台「PC」吗?
如果换个思路,所有的 agent 部署和运行全都在云上;与用户有关的数据,也即「上下文」也在云端安全和隐私存储;人类只需要一个终端的设备作为「对话器」(communicator) ,以及传感器 (sensor),拍照和录音来上传所需要的数据给 agent,这台设备甚至不需要太多端侧算力。
Mac 是今天最好的 AI PC,但未来的「AI PC」,却可能更像……iPhone?
文|杜晨
