DeepSeek又有新动作了。
不过,这次发布的,依然不是大家期待已久的DeepSeek-V4。
但这并不妨碍它成为一次重磅亮相——DeepSeek联合清华大学与北京大学,共同推出了一套全新的推理系统,名为DualPath。

更重要的是,这套系统并非为常规对话而设计,它所瞄准的,是当下更复杂、也更火热的智能体场景中的核心难题。
DualPath通过重构数据加载方式,大幅提升GPU利用率,让智能体终于在长上下文、多轮交互的真实世界中,跑得更顺畅、更实用了。
既然是三大顶尖机构联手发布的技术成果,论文里自然少不了一堆专业术语,读起来容易让人头大。
不过别担心,这篇文章不讲黑话,只讲人话。带你轻松搞懂:DualPath到底是什么,它厉害在哪。
01
智能体推理:算力成了配角
你可能已经注意到,AI圈的风向变了——从“大模型”变成了“智能体”。
过去用大模型,交互很简单:你输入一段提示词,模型思考几轮,给你一个答案。
到了智能体时代,事情复杂了。交互的双方,不再只是“人”和“机”,还有“机”和“机”。模型不仅要读懂你的话,还要自己去调用浏览器、打开代码解释器、与外部环境打交道。交互次数也从几次,飙升到几十次、上百次。
在这个过程中,智能体每次调用工具所产生的输入输出其实很短,可能只需要几百个token。但问题在于,随着交互轮次增加,上下文会像滚雪球一样越积越大,最终堆积成几十万token的庞然大物。
换句话说,智能体任务呈现出一种奇特的特征:多轮次、长上下文、短追加。
这种模式带来的直接后果是——KV-Cache的命中率,常常高达95%以上。
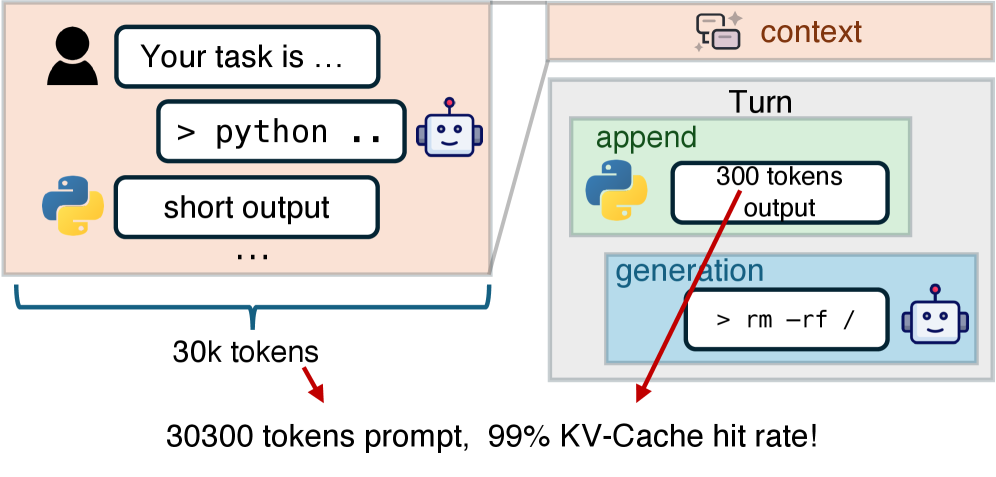
什么是KV-Cache?用一个追剧的比喻就能明白:
假设大模型的推理过程,就像你在追一部连续剧,刚更新到第20集。
第20集的内容,是由前19集的剧情背景(也就是上下文),加上第20集的新剧情(新输入)组成的。
如果没有KV-Cache,就像你得了健忘症,每次看新一集,都得把前面19集从头到尾重看一遍,才能看懂第20集。
而有了KV-Cache,就好比你已经把前19集牢牢记在脑子里,只需要看新的那一集,就能无缝衔接,继续追下去。
对于Transformer架构的模型来说,原理也是一样的。
当智能体完成一次交互,准备处理下一个任务时,它所需要的绝大部分上下文,早在之前的交互中就已经计算过了。直接读取缓存就好,只有极少量新内容需要重新计算。
所以,对计算机来说,KV-Cache的命中率当然是越高越好,因为命中就意味着“省事”。
但“省事”的背后,却藏着一个新问题:
强大的GPU,算几百个token的新一轮交互,可能还不到1毫秒。但在此之前,它需要先拿到那几十万token的“记忆”——也就是几十GB的KV-Cache数据。
要想用KV-Cache“省事”,就得把这些数据,从硬盘或分布式存储设备里,硬生生地搬运到GPU的显存里。
这就像一个顶级大厨,炒一盘菜只需要1秒钟,但他的助手买菜却要花10秒钟。

于是,智能体推理的最大瓶颈,已经不是算力,而是KV-Cache数据的输入输出速度。
02
现有架构:PD分离
为了提升推理性能,业内普遍采用的架构叫做“预填充-解码分离”,简称PD分离。
简单来说,在这种架构下,GPU集群被分成了两个部门:
一个是预填充引擎,负责处理海量输入文本,属于计算密集型任务,擅长批量处理;
另一个是解码引擎,负责一个字一个字地生成回答,对延迟极度敏感,但受限于内存。
在这样的组织方式下,预填充引擎需要不断从外部存储里加载海量的KV-Cache数据,它的存储网卡几乎随时处于过饱和状态,堵得水泄不通。
与此同时,解码引擎虽然也在正常运行,但它的存储网卡大部分时间却闲着没事干。
一个仓库里,进货的大门被堵死,出货的大门空空荡荡,整个物流线就这样卡住了。

在算力成本高昂的今天,让高性能芯片集群里的硬件资源闲置,简直是极大的浪费。
最直观的解决办法,当然是把进货的大门拓宽——给预填充引擎增加带宽。但在实际操作中,这既不现实,成本也高得吓人。
一个更聪明的办法是:让出货的大门也来帮忙进货——也就是让闲置时的解码引擎,分担一部分“拉取数据”的任务。
03
DualPath:明修栈道,暗度陈仓
来自DeepSeek、清华和北大的研究团队在对现代AI数据中心的研究中得到了灵感。
类似英伟达的AI超级计算机DGX SuperPOD,其架构普遍具备一个重要的硬件特性:网络隔离。
每个GPU一般配备两套网卡:
一是计算网卡(Compute NIC):专门用于GPU之间的跨节点卡间通信,通常配备多张总传输带宽极大;
二是存储网卡(Storage NIC):用于读写硬盘或分布式存储上的数据,通常只配备1张,总带宽相对较小。
在此基础上,研究团队试图充分利用网络传输性能,提出了双路径KV-Cache加载(Dual-path KV-Cache loading)的思路。
先前的架构采用的路径是:让预填充引擎直接通过自己的存储网卡,从硬盘或分布式存储中拉取KV-Cache数据。
而DualPath则是让闲置的解码引擎利用存储网卡从硬盘或分布式存储中拉取KV-Cache数据到其内存,再利用极高带宽的计算网络把数据快速传输给预填充引擎。
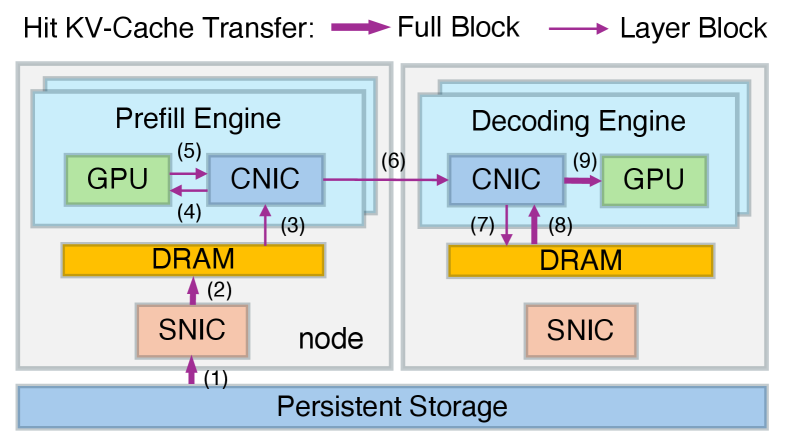
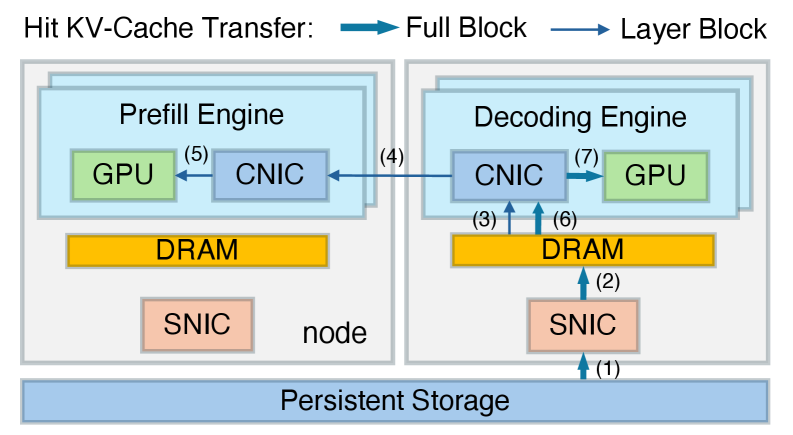
当然,DualPath不会无脑让解码引擎来帮忙,而是会实时监控两个大门的拥堵情况。
如此一来,进货的大门被堵住时,如果暂时没有出货,出货的大门也开始进货,所有引擎的存储网卡带宽都得到了有效利用,不对称带宽饱和问题得以解决。
研究团队经过严格的带宽分析证明,在常见的预填充和解码节点配比下,DualPath在使存储网卡带宽饱和的同时,计算网卡的带宽也不会成为新的瓶颈,能够覆盖绝大部分实际部署场景。
04
虽然数据的流向多绕了一大圈,实际推理效率却能大幅提升,想法看起来很美好。
但想要在以微秒级别运行的系统中落地,还有相当重量级的挑战摆在眼前:
一是大量数据引入带来的混乱:
让解码引擎帮着一起拉取历史记忆数据(KV-Cache)确实是个好主意,但也会带来巨大的风险。
GPU在推理过程中,需要频繁地与集群中的其他GPU进行“集体通信”,完成数据的同步和结果的交换,这种通信对延迟极其敏感,慢一点都不行。
如果解码引擎开始下载几个GB的KV-Cache数据,火山喷发一般的数据流就可能挤占网络带宽,如果GPU之间的集体通信不幸被阻塞了,推理过程还是会卡住。
为了解决这种混乱的情况,研究团队在网卡层面上设置了一个高速上的“交警”:
GPU之间的通信必须具有最高的优先级,它有走VIP通道的权力,无论如何都要保证正常运行、不许堵车;
拉取KV-Cache数据的任务则只有普通优先级,VIP通道没车的时候它才能上路,只要GPU通信任务出现,它就得立刻避让。
这位由计算网卡(CNIC)扮演的“交警”必须彻底隔绝两种数据流量,确保解码引擎拉取数据绝对不能影响GPU之间的集体通信。
二是如何动态分配任务:
人们的各种需求意味着智能体的推理任务总是动态变化的,有时请求多,有时请求少,有的请求长,有的请求短。
如果这位“交警”指挥不当,那就必然会帮倒忙。例如,预填充引擎的带宽明明没有饱和,却非要绕远路让解码引擎去拉取数据。
如何实时通过负载均衡(Load Balance)来动态分配任务,是这位“交警”必须面对的数学难题。
为此,研究团队设计了自适应请求调度器,让系统在运行时根据存储网卡的队列长度、GPU计算负载以及请求特征,动态选择最优的数据加载路径。
在引擎间,它不仅会监控每个GPU当下的计算负载,也就是待处理的token数量;还会同时监控底层分布式存储在每个节点上的磁盘读取队列长度。
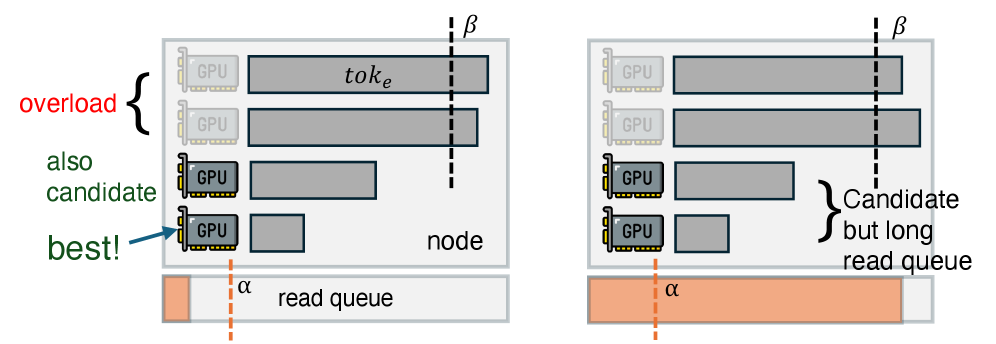
这样,新的请求总会被智能分配到读取队列最短、GPU最闲的那个引擎进行加载。
在引擎内,由于多张GPU被绑定在一起干活,所有的GPU必须同时干完手上的活才能进入下一个环节,这就是注意力机制的同步。
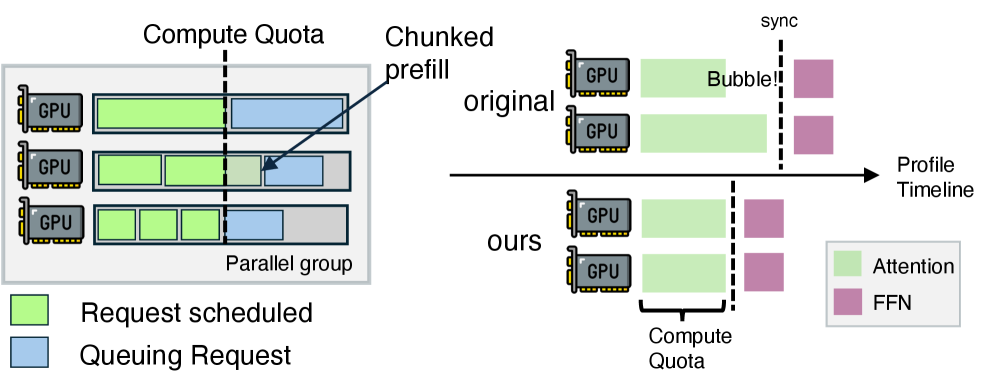
为了防止拿到短任务的GPU“干等着”拿到长任务的GPU,它需要使用基于计算配额的批处理选择算法,把长任务分割为短任务,这样多张GPU计算注意力机制的时间就能基本对齐,尽快进入到下一个环节。
到这里为止,DualPath面对的问题就都解决了。
05
实测:吞吐量翻倍!
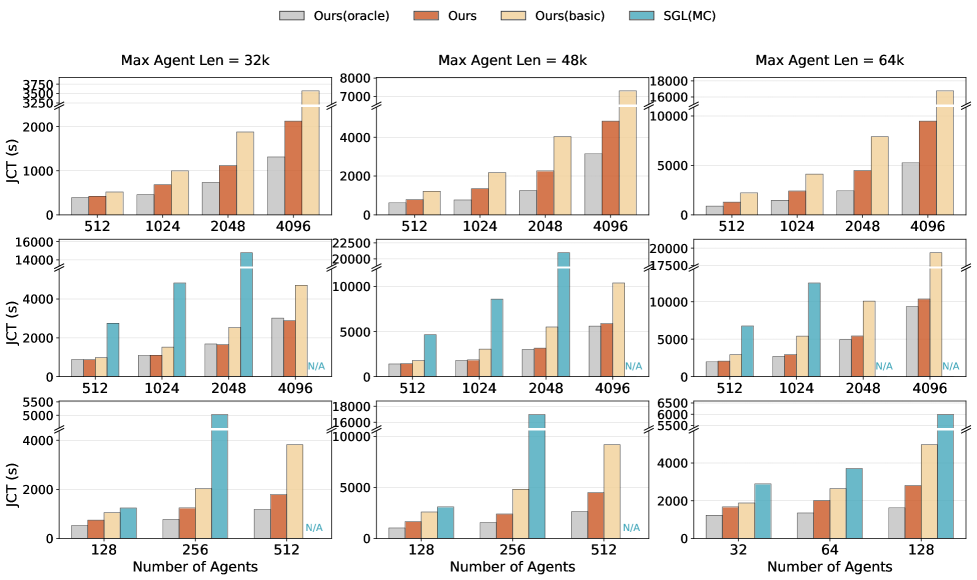
研究团队在基于InfiniBand高速互联的英伟达Hopper GPU集群上,使用了DeepSeek-V3.2的660B参数版本、27B参数简化版本和Qwen2.5-32B三种模型进行测试,并根据真实的智能体强化学习训练轨迹进行评估。
在离线批处理推理任务中,对于DeepSeek-V3.2 660B模型,DualPath的任务完成时间大幅缩短,系统的吞吐量最高可提升1.87倍,性能逼近无I/O延迟的理想状态。
在在线服务推理任务中,模拟的真实用户会不断涌入,系统需要在保证输出第一个字符的延迟不超过4秒的情况下尽可能处理更多请求。
结果显示,DualPath系统能够承载的并发请求数量平均达到基线系统的1.96倍,在特定的负载情况下甚至能达到2.25倍。
而在扩大GPU集群至1152张的超大规模实验中,DualPath展现出了接近线性的加速比,性能衰减极低,这个现象无疑为其投入实际使用提供了强大的说服力。
回顾从“大模型”到“智能体”的发展历史,我们可以看到一条清晰的路径:
最早期的挑战是算力,如何更快计算神经网络矩阵是头号问题;
随后内存登场,模型权重和KV-Cache占据了网络传输带宽;
现在智能体爆发,上下文成倍增长,挑战又来到了输入输出和网络层面。
DeepSeek、清华和北大三大巨头联手提出DualPath顺利跨越了这个门槛,打破了数据的常规流向,让闲置的资源得以充分利用。
毫不夸张地说,又是一次软硬件协同设计的教科书级别示范。
大模型作为智能体的底层基础设施,其内在计算逻辑正在悄无声息地发生巨变。
