回望过往表现,2019年,深圳分会场的6台优必选Walker大型仿人机器人集体起舞,让大家看到了人形机器人走上舞台的可能;2025年,16台宇树H1人形机器人以整齐划一的赛博秧歌,印证了本体控制与群体协同的初步成熟。
|
|
|


到了今年,内行捕捉到的信号远比视觉奇观更深刻:这届机器人不“僵”了。它们在复杂的阵型变换、多变的光影追踪下,展现出了一种生物才有的灵动。

松延动力仿生人形机器人“蔡明”逼近真人



银河通用人形机器人Galbot G1货架取物

银河通用人形机器人Galbot G1手盘核桃,图片来源:中央广播电视总台《2026年春节联欢晚会》
这背后,源于一场漂亮的本体革命:更先进的控制算法、毫秒级的轨迹追踪以及软硬件的深度耦合。
然而,清醒的行业观察者都知道,晚会终究是一定意义上的预设场景。当机器人走下铺设好的舞台,进入非标的工厂、杂乱的家庭或多变的养老院,仅靠灵活的身体已难以过关。
要跨越真实世界的鸿沟,机器人必须长出能理解、预判并规划物理世界的“大脑”。
01.
毫无疑问,目前具身智能最主流的“大脑”底座是 VLA(视觉-语言-动作)。2026年开年,这个赛道堪称卷王之战。
首先。蚂蚁灵波用20000小时真实数据,喂出最强开源VLA基座。它使机器人拥有精确的空间感知能力,并可适配9种不同构型的双臂机器人,真正实现“一个大脑,适配多个身体”。

小米刚刚开源的Xiaomi-Robotics-0,使用双脑协同架构及两阶段训练策略,用47亿参数在消费级显卡上跑出了惊人的精细度,叠毛巾、拆乐高这种单任务可保持30分钟的连续作业高稳定性,可以说几乎做到了实用级。
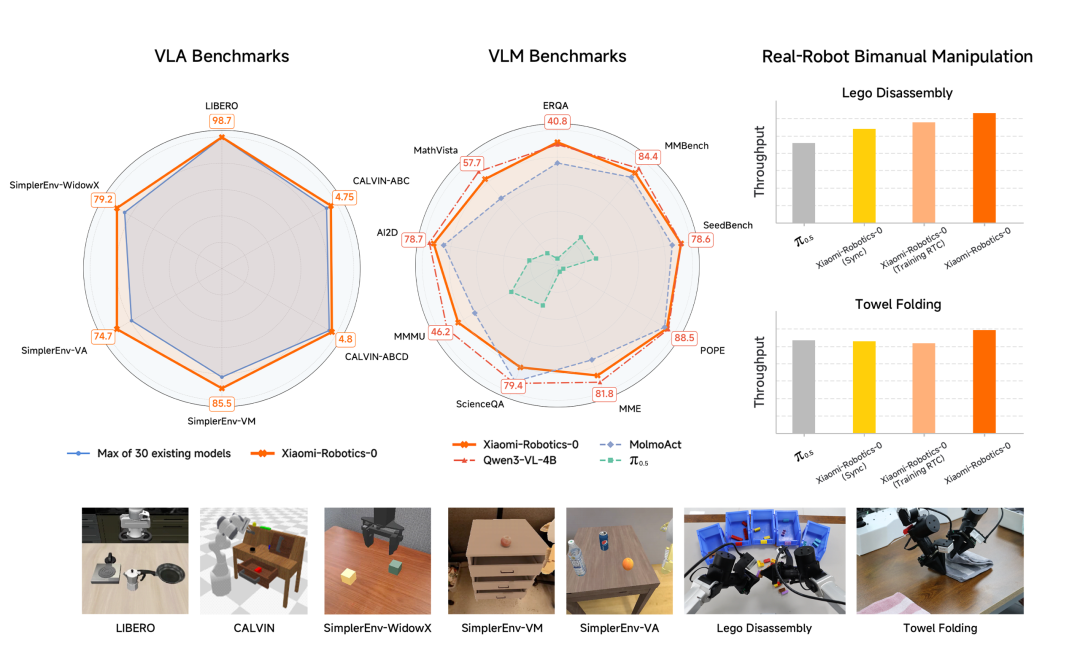
在VLA、VLM的Benchmark以及真实机器人的效果指标
地平线紧随其后的HoloBrain-0基座模型,作为面向真实机器人的全栈VLA,则试图通过“具身先验”让机器人拥有更强的3D空间感,能折叠柔软衣物,也能抓取从未见过的物体,同样具有强大的跨平台泛化能力。
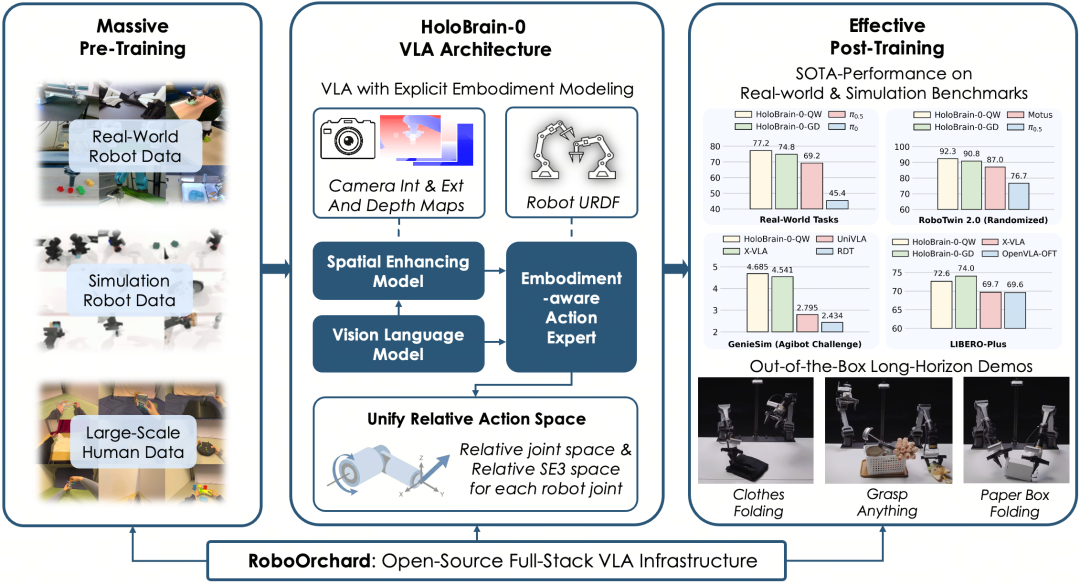
这些突破,意味着 VLA 在结构化环境、单任务场景下,已经迈入实用门槛。
但VLA 的原理也注定了它的天花板。眼睛看到指令,大脑直接输出动作信号,这种“端到端”的模式在实验室演示中很漂亮,但一旦要进入工厂、家庭、药房这种真实环境,问题就接踵而至:
它知道叠毛巾的步骤,但不理解重力对织物褶皱的因果;它能拆积木,却无法在大脑中模拟出由于重心不稳导致的塔身倾斜。
这种缺失物理常识的盲动,让 VLA 很难处理长序列任务中的意外。也就是说,机器人如果只是在模仿人类,而没有对物理世界的理解,它永远只能在结构化环境里表演。
02.
技术跃迁:当世界模型进入控制闭环
显然,行业也已经意识到,具身智能的下一场进化,必须从看图说话式的动作对齐,转向脑内预演式的物理模拟,也就是VLA向具身世界模型的范式跃迁。
这种转变是全球性的竞速。
作为路线的最早探索者之一,DeepMind 通过海量视频训练出的Genie模型,证明了AI可以通过视频学习脑补出一个可交互的物理世界。它的核心逻辑是:预测未来,是控制未来的前提。
黄仁勋力推的GR00T项目,则利用大规模生成式 AI在仿真环境中为机器人提供预演能力。NVIDIA的思路是让机器人在数字孪生世界里先经历万次挫折,从而在现实中获得物理直觉。
而Figure 02尽管依然拥有极强的VLA属性,但在其最新的架构中,开始显著强化“动作后果预测”。这种从单纯的指令追随向“物理后果评估”的转变,本质上也是向世界模型的靠拢。
在这场范式跃迁中,国内蚂蚁灵波的打法显得尤为硬核且务实。它不仅认可世界模型这一方向,更率先通过开源路径,给出了从“视觉模拟”到“动作控制”的闭环方案。
其核心在于两套互为表里的系统。LingBot-World不止是一个视频生成模型,更是构建一个与物理世界规律一致的 高保真、可交互仿真环境。机器人可以在这个虚拟世界里进行无数次零成本的人生模拟,学习技能、试错规划,再将经验无损迁移到现实。
这意味着,在动手前,它能预判出杯子受力后滑动的轨迹、织物被抓取后的形变,并在大脑里完成物理模拟。

LingBot-World 在适用场景、生成时长、动态程度、分辨率等方面的表现
真正实现降维打击的,是同步开源的LingBot-VA。它号称全球首个自回归视频-动作一体化世界模型,可根据当前观测,同步生成下一帧的世界画面和达成该画面的机器人动作,实现“边推演,边行动”。
如果现实中物体因为油渍打滑、或受重力影响偏离了预演轨迹,系统能瞬间通过画面的不对齐感知到偏差,自动修正抓取力度或角度。
这种“预测-对齐-修正”的闭环,本质上是给机器人装上了一双能看穿物理因果的慧眼。它让机器人不再只是死记硬背VLA的动作概率,而是拥有了应对非标环境的物理直觉。
这是解决机器人进入药房、家庭、工厂等复杂场景时可以见招拆招的关键。
03.
脱离了实验室的炫技,这种从“动作映射”到“物理预演”的跨越,本质上也是在为产业的规模化交付扫清障碍。
首先是数据效率的质变。以前训练一个新技能要喂上万条真机数据,而在 LingBot-VA 的逻辑下,模型懂因果、懂常识,只需30~50条演示数据就能类比学会新任务,落地成本极大缩减。
其次是任务成功率的确定性。具身智能最怕的不是任务难,而是环境乱。在 RoboTwin 2.0 仿真基准数据中,这种具备“预判能力”的大脑表现出惊人的韧性,多任务成功率稳定在 91% 以上。
换句话说,机器人即使在环境杂乱、传感器有噪声的非标工厂里,也能稳健地完成长流程操作。
最后是大脑的通用性。全栈开源背后,是一套通用大脑适配多元硬件的底座方案。无论是宇树的 H1、G1,还是各类工业级机械臂,都可以共用这一套底层认知逻辑。
这就意味着下游厂商不必再为每一款机器人重复造轮子,而是可以将精力集中于垂直场景的工艺打磨。
04.
结语:从“秀场”走向“战场”
在具身智能的赛道上,从来没有唯一的标准答案。
回看这几年,我们其实是在分步给机器人装零件:2023年是“对台词”,接入大模型让它听懂了人话;2024年是“练筋骨”,硬件成熟让它走出实验室,学会了基本的拿放。而如今是逻辑觉醒,机器人终于开始理解物理规律,动手前学会了先在大脑里打个草稿。
当然,VA架构虽然展现了降维打击的潜力,但它并非唯一路径。
业内关于最优方案的博弈从未停止:有人依然笃信数据够大,纯 VLA 模型也能暴力模拟物理规律;也有人主张用严谨的数学公式去精准控制,确保极端场景下的零差错。
这种多路线的交叉跑位,反而让2026年的具身智能赛道更具实战价值。
VA 路径的意义在于,它极大地提升了机器人在非标环境下的直觉。当机器人开始拥有这种物理逻辑,能在三维世界里精准预判、稳健操作时,具身智能才算真正从春晚的舞台,落到现实产业中。
