
新智元报道
编辑:元宇
【新智元导读】在OpenAI一项内部实验中,一个最初仅3人的团队、5个月、从零到一造出「百万行代码产品」,没有一行代码是人类程序员完成的,而不手工写代码,也是该项目的一条铁律。
这一次,人类软件工程被「倒过来」做了!
刚刚,OpenAI官博曝光了他们的一次内部实验:
一支最初3人的工程师团队,利用Codex智能体在5个月内从零造出了一个「百万行代码产品」。
在整个过程中,人类不写手工代码,而是把精力集中在「想清楚要什么、把规则立起来」,其余的一切交给AI。
每人每天平均能推进3.5个PR(Pull Request,代码合并请求),而PR的执行环节(实现、测试、文档、CI配置)全程由智能体代劳。
OpenAI为这套工作流赋予了一个十分形象的名字:「驾驭工程(Harness Engineering)」。

https://openai.com/index/harness-engineering/
在实验里,程序员不再是那个熬夜写Bug,再熬夜修Bug的「码农」,而是原来的「执行者」变为「驾驭者」。
这不止是10倍效率提升的「生产力革命」,而是一次对「软件工程」定义的颠覆,直接宣告了人类「手工代码时代」的终结。

改变
从一个空的git仓库开始
这次实验从AI的第一次提交开始。
2025年8月下旬,当空仓库里落下第一个commit(提交)时,它就已经不是人类写的——当时没有任何既有人类代码可以充当「锚点」。
更魔幻的:连那个用来指导AI怎么干活的说明书AGENTS.md,第一版也是AI自己写的。
从第一天起,这个仓库就是由智能体塑造的。人类不许写代码,成了这个项目的一条不可逾越的铁律。
这不是为了偷懒,而是一种近乎自虐的「刻意练习」,只有切断了人类「亲自上手」的退路,才能倒逼团队去破解那个在完全无人情况下构建代码的终极问题。
于是,这个3人小团队(后扩展到7人),一下子好像成了拿着鞭子的牧羊人,驱赶着一群不知疲倦的Codex智能体在代码草原上狂奔。
结果令人震撼:5个月,一百万行代码。
重新定义工程师的角色
这项实验的早期进展,比OpenAI的研究人员预想得要慢。
不是因为Codex不行,而是因为环境定义得不够清晰:智能体缺少实现高层目标所需的工具、抽象和内部结构。
于是,OpenAI工程团队的主要工作变成了一件事:让智能体有能力完成有价值的工作。
他们把大目标拆成更小的构建块(设计、编码、评审、测试等),提示智能体把这些块搭起来,再用它们去解锁更复杂的任务。
当事情失败时,答案几乎从来不是「再试一次」,这里唯一的推进方式就是让Codex去完成工作,人类工程师通常会退一步问自己:
到底缺了什么能力?怎样把它变得对智能体既清晰可见,又可以被强制执行?
整个过程中,人类几乎完全通过提示词与系统交互:工程师描述任务,运行智能体,让它发起一个PR。
为了推进PR完成,研究人员会让Codex在本地自审改动,请求额外的本地和云端智能体评审,回应人类或智能体的反馈,然后在一个循环里不断迭代,直到所有智能体评审者都满意。
随着时间推移,几乎所有评审工作都移交给了「智能体对智能体」。
提升应用程序的可读性
随着代码吞吐量的增加,OpenAI发现:AI编码的瓶颈变成了人工质量检查(QA)的能力。
于是,人类的时间和注意力成了真正的约束。
为了突破这一瓶颈,OpenAI的办法是让Codex能够直接读取应用程序的用户界面、日志以及应用指标等内容。
他们将Chrome DevTools协议接入了智能体运行时,并开发了处理DOM快照、截图和导航的技能。
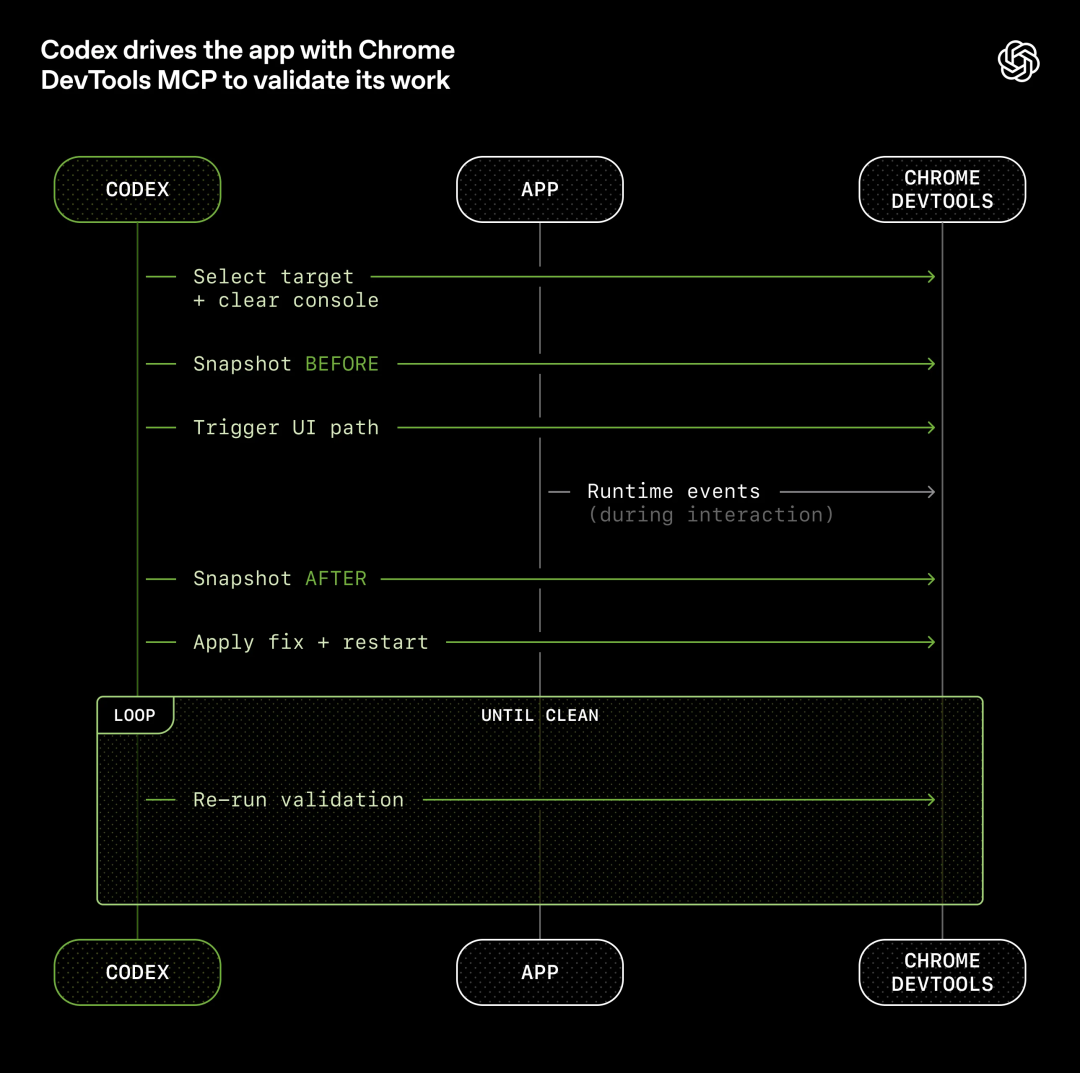
于是,Codex可以自己复现bug、验证修复、推理UI行为。
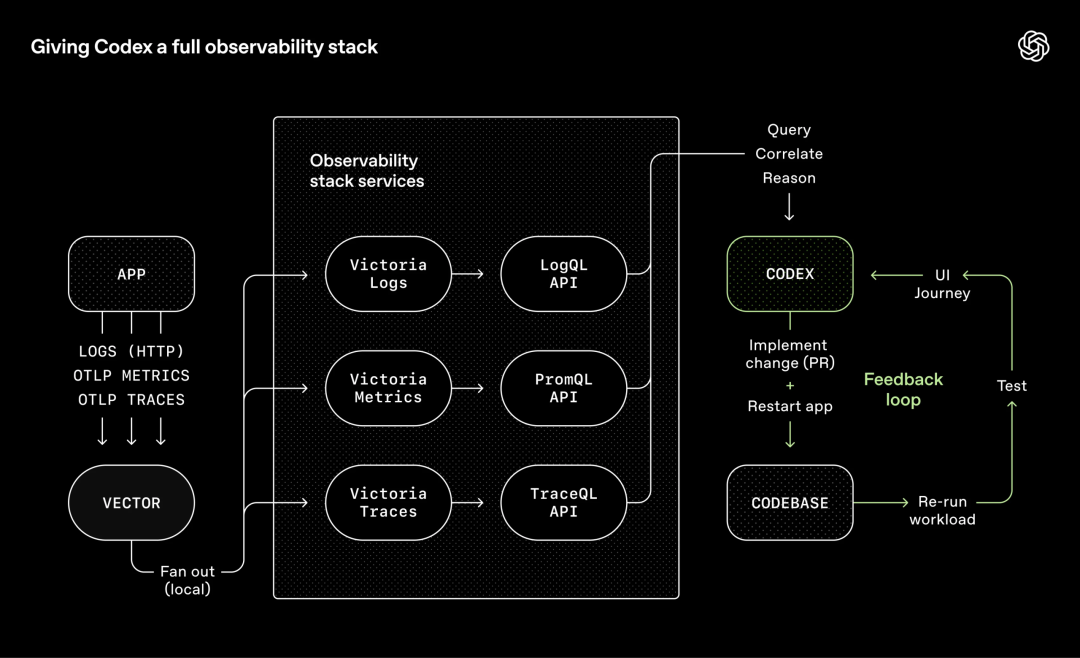
OpenAI对可观测性工具也采取了同样的做法。
日志、指标、追踪通过本地可观测性栈暴露给Codex,并且对每个worktree(工作区)都是隔离、临时的环境。
任务完成后,这套环境就会被销毁。
智能体可以用LogQ查日志,用PromQL查指标。
于是,「确保服务启动在800ms内完成」或者「这四条关键用户路径里没有任何一个span超过两秒」这样的提示,就变得真正可执行。
做了这些之后,OpenAI研究人员经常看到Codex一次运行连续工作六个小时以上,通常还是在人类睡觉的时候。
给Codex一张地图
而不是一本1000页的说明书
让智能体处理大型复杂任务时,上下文管理是最大的挑战之一。
OpenAI研究人员早期学到的一个简单经验就是:
给Codex一张地图,而不是一本1000页的说明书。
一开始,团队试图写一个超大的AGENTS.md文件,把所有规则、逻辑、注意事项都塞进去。结果,这成了一场灾难。
因为AI的注意力也是稀缺资源。
给它一本1000页的说明书,它会迷失在细节里,漏掉关键约束,或者把目标搞错。
而且,这种单体大文档维护起来简直是噩梦,很快就会变成「陈旧规则的坟场」。
于是,团队迅速调整策略,他们把AGENTS.md变成了一张「寻宝地图」。
这个文件只有大约100行,它不包含具体知识,只是一个目录,就像一个导航地图,指向仓库深处更深层的真实来源。
设计文档被编目并索引,包括验证状态以及一套定义「以智能体为先」操作原则的核心信念。
真正的知识库在结构化的docs/目录里,是系统的唯一事实来源。
这就是「渐进式披露」:智能体从一个小而稳定的入口开始,被教会下一步去哪找,而不是一开始就被信息淹没。
OpenAI的研究人员还用工具强制执行这一点。
通过专门的lint和CI任务校验知识库是否最新、是否交叉链接、结构是否正确。
架构文档给出领域划分和包分层的顶层视图。质量文档为每个产品领域和架构层打分,持续追踪差距。
为了保证AI不读到过时的信息,团队甚至专门安排了一个「文档园丁」智能体。
它的工作只有一个:定期扫描文档,发现那些与代码实现不一致的陈旧描述,然后自动发起修复PR。
让智能体「看得懂」
既然仓库完全由智能体生成,OpenAI研究人员的一个目标,就是让智能体只靠仓库本身,就能理解完整业务领域。
从智能体视角看,任何它在运行时上下文中访问不到的知识,都等于不存在。
比如放在Google Docs、聊天记录、人类大脑的知识,对系统来说都是不可见的。
它能看到的只有仓库里版本化的工件,如代码、Markdown、schema、可执行计划。
如果智能体找不到这些上下文知识,它们就会和刚入职的新同事一样,对于实际业务进展一无所知。
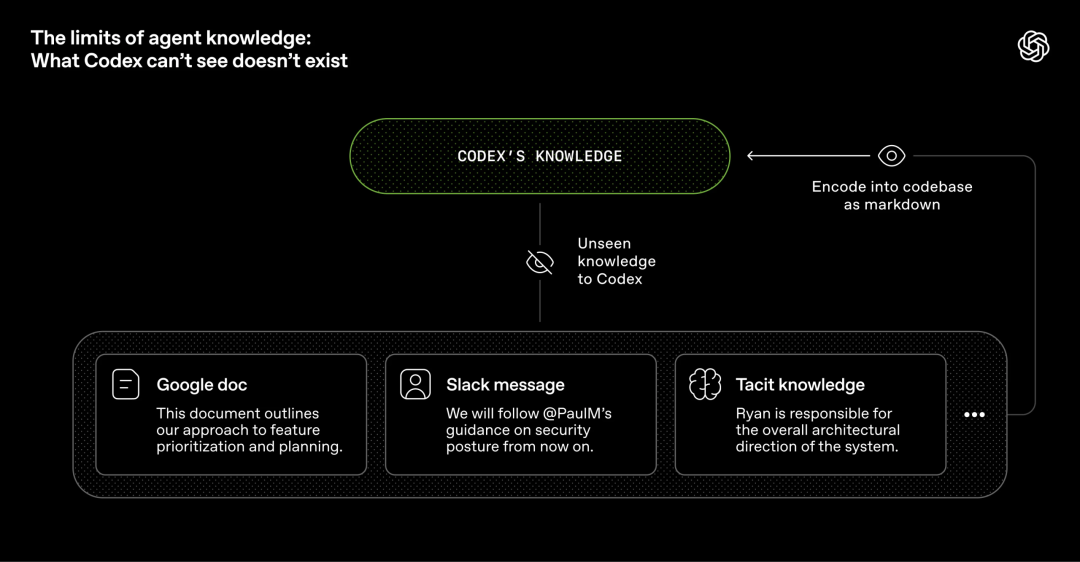
因此,必须把越来越多的上下文推回仓库。
当然,给Codex更多上下文,并不是要塞给它更多零散指令,而是把信息组织好、结构化,让它可以推理。
自动化围栏
让程序员成为代码世界的「牧羊人」
光有文档,还不足以让一个完全由智能体生成的代码库保持一致。
AI毕竟是概率模型,它会产生幻觉,会偷懒,会写出「看似能跑实则一团糟」的代码。
怎么解决?
智能体在边界清晰、结构可预测的环境中效率最高。
OpenAI通过强制执行「不变量」,而不是微观管理实现细节,让智能体可以高速前进而不破坏基础。
这就好比为Codex这样日行千里的AI烈马,套上了缰绳和马鞍。
OpenAI围绕一个严格的架构模型构建系统。每个业务领域都有固定层级,并且依赖方向被严格验证,只允许有限的合法边界。
规则很简单:在每个业务领域内(如App Settings),代码只能沿着固定层级「向前」依赖:
Types→Config→Repo→Service→Runtime→UI
横切关注点(认证、连接器、遥测、功能开关等)只能通过一个显式接口:Providers。
其他依赖一律禁止,并通过自定义lint(也是Codex生成)和结构测试强制执行。
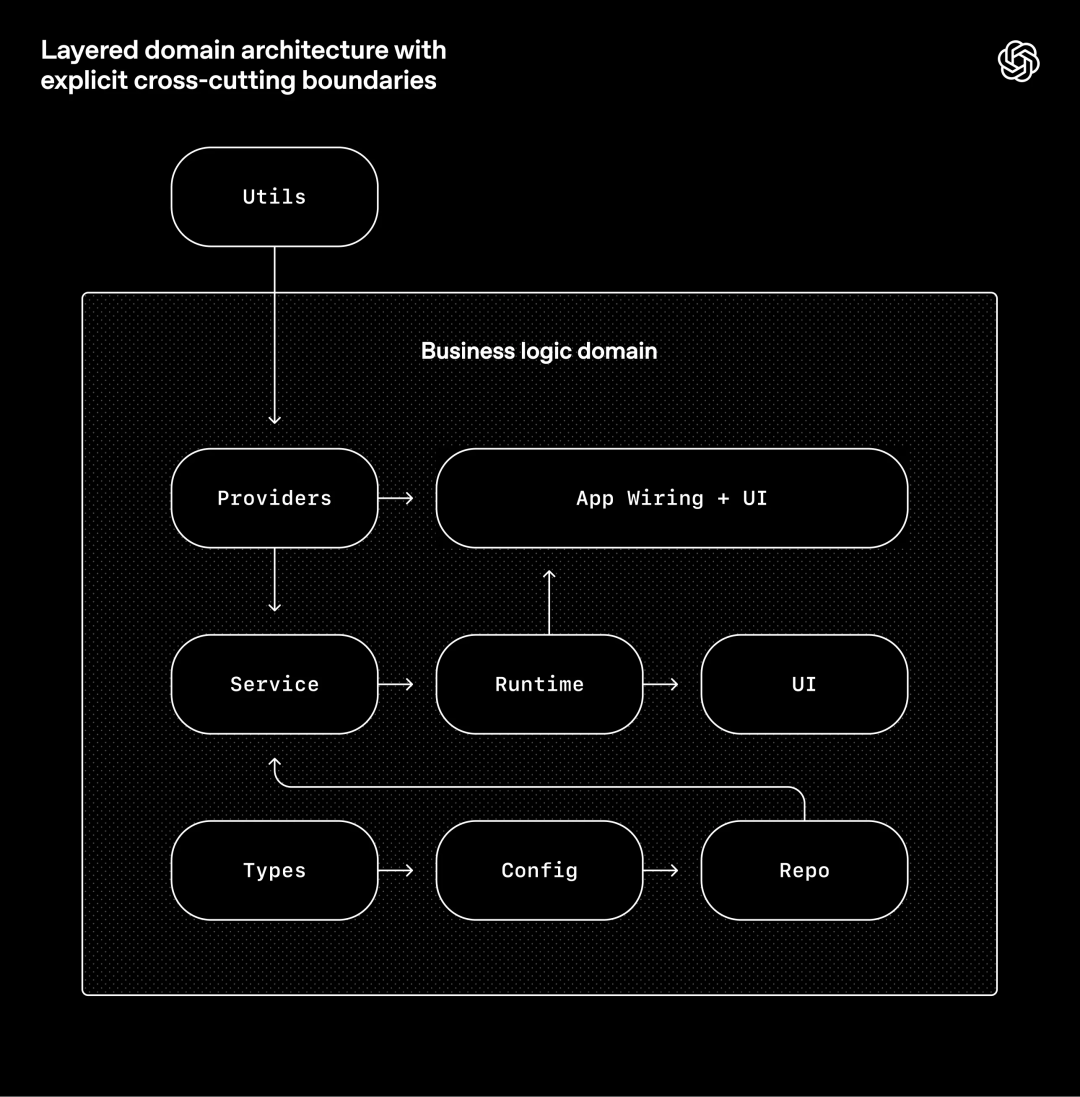
这种架构通常是公司规模到几百人时才会认真设计的。但在有编码智能体的情况下,这是前提条件。
此外,OpenAI的研究人员还定义了一组「品味不变量」,如:
强制结构化日志
schema和类型的命名规范
文件大小上限
平台级可靠性要求
在这个过程中,必须明确区分的是哪些地方必须严格,哪些地方可以放权。
这好比管理一个大型工程平台:边界集中管控,内部高度自治。
AI生成的代码未必符合人类审美,但只要正确、可维护、对智能体可读,就OK。
在这个过程中,人类的品味不会消失,而是被持续「编码」进系统。
评审意见、重构PR、用户bug都会转化为文档更新,或直接升格为工具规则。
当文档不够用时,就需要把规则写进代码。
扔掉键盘
勇敢去驾驭AI
OpenAI的这项实验宣告了:大量以CRUD为主的岗位,正在被重塑。
如果一个从零开始的系统,可以在5个月内,由3个人(不写一行代码)构建出百万行规模,传统软件公司里那些庞大的开发团队,还有存在的必要吗?
在这个即将到来的新时代,工程师的定义将被彻底改写。
你需要的是强大的「架构能力」,能够定义系统的边界,设计模块之间的约束,构建那个让AI不跑偏的「围栏」。
同时,你还需要精准的「表达能力」,学会用最清晰的语言(无论是自然语言还是结构化文档)向AI描述你的意图。
拒绝AI编程,坚持手搓代码的人终将被浪潮吞没,只有那些懂得驾驭AI的程序员,才有可能成为AI时代的赢家。
