
作者 | 王涵
编辑 | 漠影
智东西2月7日报道,昨天,小米MiMo大模型团队宣布推出HySparse,一种面向Agent时代的混合稀疏注意力架构,使用“极少的全注意力(Full Attention)+ 稀疏注意力(Sparse Attention)”核心设计。

随着Agent模型与应用的爆发式发展,精准高效处理超长文本正在成为模型必不可少的基础能力。Agent不仅需要在超长上下文中完成稳定检索、推理与多轮规划,还必须在推理阶段保持足够快的响应速度,目前最大的挑战已经不只是“能不能算”,而是“算不算得起”。
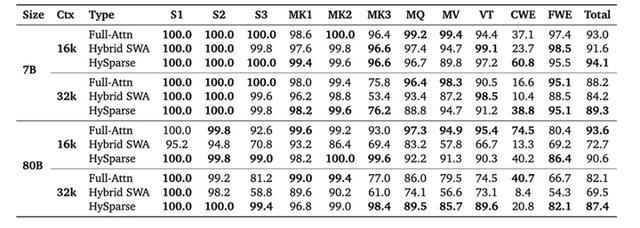
为此,小米MiMo提出了HySparse架构。在多项通用、数学、代码和中文评测中,HySparse在7B Dense和80B MoE两种规模均带来提升。
其中,在总共49层的80B-A3B MoE模型实验中,HySparse仅保留5层Full Attention仍能保持或提升模型能力,KV Cache存储降低至原来的1/11,实现效果与效率的兼顾。
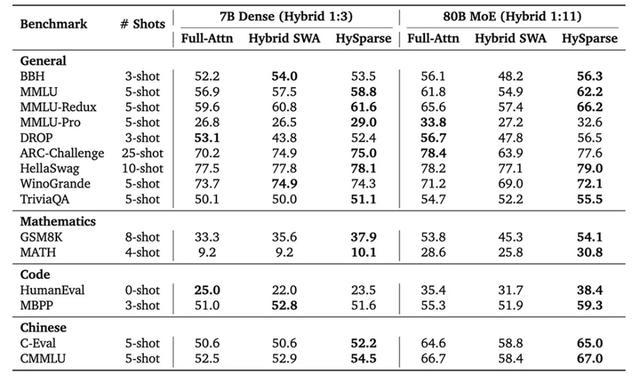
RULER长文测试表明,HySparse即便将Full Attention层压到极少,也能稳定保持长距离关键信息访问,展现了其混合稀疏结构的优势。
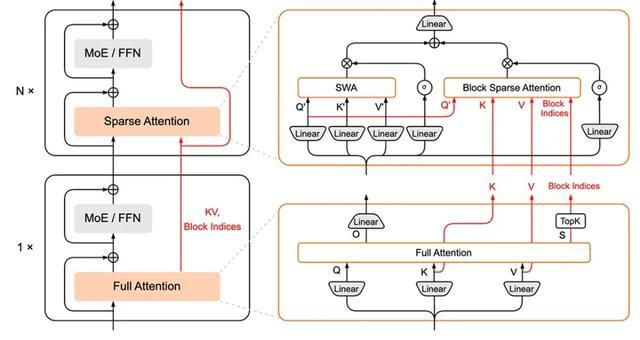
HySparse采用hybrid block结构:每个hybrid block由1层Full Attention+N层Sparse Attention组成。Hybrid block内部的Sparse Attention层并不再独立做token选择和维护全量KV,而是直接复用前置Full Attention层产生的重要token索引和KV Cache。
这背后的动机是Full Attention在完成自身计算的同时,已经生成了KV Cache,并且计算出了最准确的 token重要性信息,自然可以供后续N个Sparse Attention层直接复用。
HySparse可以视为是在MiMo-V2-Flash的Hybrid SWA结构的基础上,为SWA增加了全局的、更重要的token信息补充。这一改进不仅提升了性能,还没有增加KV Cache存储,也没有显著增加计算开销。
HySparse结构为Agent时代的超长文本处理提供了高效精准的技术解决方案,也为大模型高效注意力结构的研究与落地提供了全新参考。
小米MiMo透露,团队计划在更大规模模型上进一步验证HySparse的极限和潜力,并持续探索降低Full Attention层数量的可能性,让超长上下文更高效。
