很多研究生可能遇到过一个常见的现象:论文在几天前就已经定稿,配图却卡了整整一周。
一张精心设计的方法论示意图,往往能将长篇大论的复杂算法流程转化为最直观的视觉语言,成为论文被接收或顺利通过的关键加分项。
然而,对于多数研究者而言,绘制符合顶会标准的学术插图极其耗费时间。拼接图标、箭头对齐等琐碎的操作不仅大大延缓了科研节奏,还将创造力限制在技术细节之中。
好消息是,名为PaperBanana的工具在2026年2月闪亮登场,目前论文已发布,Github仓库预计在1周内开源。
看到这个名字,不少AI爱好者应该能联想到Google的知名产品Nano Banana。事实上,PaperBanana正是由北京大学和Google Cloud AI Research团队联合开发的首款面向AI科学家的全自动学术配图框架。
该技术的论文中还有一个值得关注的“巧思”:论文中所有标注了香蕉emoji🍌的配图,都是由PaperBanana自动生成的。
这不仅是一次技术展示,更是自动化的自我证明。当工具能为自己配图,证明它已经准备好接管这项耗时耗力的创造性工作。
01 学术配图的双重困境
研究团队在观察多个科研进程后发现,当前科研论文的配图主要有两种方案,但都难以在表达力和准确性之间取得平衡。
首先是代码派:以TikZ和Python-PPTX为代表,通过编程生成矢量图。
其优势在于结构严谨、可无限缩放。但当下AI相关论文中的视觉元素日益复杂,结构各异的神经网络层、具象化的智能体交互图标、多模态融合的表达对于编程工具来说难度太高。
这些工具的本质还是几何绘图语言,很难去描述机器人动作、智能体交互等具象的概念。而且,涉及编程就意味着这些工具可能需要投入几周的学习成本,对于多数研究者来说难以接受。
然后是文生图派:直接调用顶级多模态大模型生成配图。
这种方式的门槛极低,而且能生成视觉吸引力极强的图像,但却经常因为缺乏相关领域知识和文字渲染能力不足而在学术场景中翻车。
毕竟,通用文生图模型更加注重图像质量,但缺乏对学术插图的深度理解。例如箭头代表数据流向,模块位置表明逻辑层级,这些含义在文生图模型眼里可能都只是装饰。
就像研究团队所说的:“科学发现的全部价值,唯有通过有效沟通才能实现”。
02 五位专家的流水线
PaperBanana的创新之处在于将论文配图生成这项任务,从文生图模型“语义推断像素”重构为“参考驱动”的多智能体协作过程。
就像研究生在入学时,导师下达的第一个学术任务往往是广泛阅读参考文献。人类研究者在设计论文配图时,也会频繁参考同类论文的视觉范式。
PaperBanana试图用五个专业化的智能体协作模拟这一过程:先参考同类作品确定结构范式,再规划生成内容的逻辑,根据审美学的规范,最后通过多轮自省迭代进行优化。
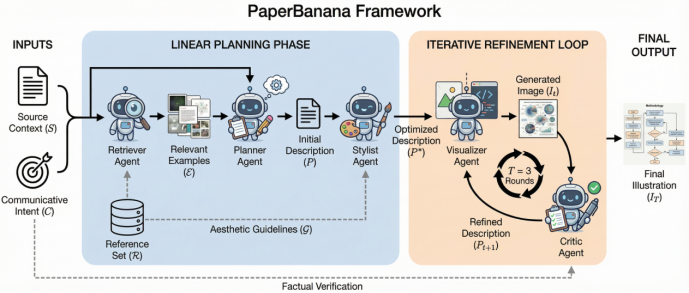
论文中的定义有些抽象,这里我们会给出例子以便于理解以下五个模块的功能:
1.检索员(Retriever Agent)
在用户指定方法描述和图注后,它将负责寻找风格与结构相似的参考图,检索图库内最相关的现有图表作为范例。
这里的匹配机制会优先考虑流程图或架构图等视觉拓扑结构,而不是单纯的主题相似。
例如,研究者需要一幅“多智能体推理框架”的配图时,系统会优先检索具有并行分支、信息聚合结构的图表,而非仅仅匹配“智能体”这个关键词。而消融实验的结果也显示,提供一般化的结构和风格模式比精确的内容匹配更重要。
2.规划师(Planner Agent)
这是系统认知的核心,它会通过上下文学习从检索到的范例中提炼出一套绘图逻辑,把非结构化的方法文本转变为详细的视觉描述。
例如,用户的描述是“一个双阶段蒸馏框架,第一阶段提取A模型的中间特征,第二阶段对齐B模型的输出分布”。规划师就会生成包含“两个并列模块”、“带标注的箭头流向”等细节的文本描述。
3.设计师(Stylist Agent)
它要解决一个核心难题:学术上的美学难以明确定义。
若是采用传统方法,就需要人工编写风格文档,但这样做很容易遗漏细节。其实,现代AI相关论文的视觉规范就隐藏在大量的公开出版论文中。因此,PaperBanana让设计师遍历整个参考图库,自动归纳出一份涵盖配色方案、箭头样式、字体层级、图标风格的“美学指南”。
在大量阅读顶会论文后,设计师就可能会发现数据流箭头大多采用浅色细线、模块容器常用圆角矩形而非直角等学术界默认的经验。
4.渲染师(Visualizer Agent)与批评家(Critic Agent)
这两位专家共同构成了闭环优化回路。
首先,渲染师接收到设计师发来的美学指南,用Nano Banana Pro等图像生成模型产出初稿;然后,批评家开始审稿,严格对比生成结果和原始文本是否一致,若是存在箭头指向错误、文字渲染模糊等问题,就会生成修正后的描述反馈给渲染师。这个过程可以多轮循环。
测试数据显示,若是缺少了评论家的多轮反馈机制,配图的简洁度能提升17.5%,美观度能提高4.7%,可忠实度(即配图符合原文的程度)却降低了8.5%,这表明过度追求视觉上的精简可能会牺牲技术细节。
而在两位专家的协作下,经过3次迭代即可将忠实度从38.3%提升至45.8%。多轮迭代即可平衡这一矛盾,“批评-修正”的循环最终实现了准确性与美感的兼顾。
当前AI应用正在从单模型、单任务向多智能体协作快速演进,而PaperBanana的五智能体流水线正是这一趋势的有力体现。
03 视觉语言模型来当裁判
PaperBanana的工作机制我们已经了解,想要验证技术是否有效就必须有可靠的评测基准。
为此,北大和Google的研究团队为此专门构建了首个专注于学术论文配图生成的评测基准:PaperBananaBench。
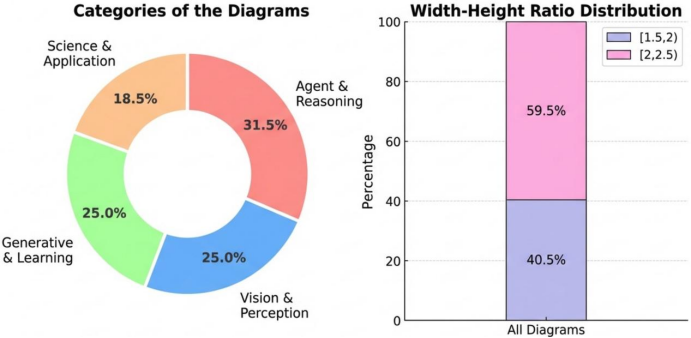
研究团队从NeurIPS 2025的5275篇论文中进行系统采样,经过多轮的过滤和人工校验后,最终得到了292个高质量的测试用例,覆盖了智能体推理、视觉感知、生成式学习、科学应用这四个类别。
评测方法也是独具一格:采用VLM-as-a-Judge方案,让全球顶尖模型Gemini-3-Pro来当裁判。
裁判能够同时看到人类绘制的参考配图和AI生成的配图,并基于以下四个维度进行相对评分(模型获胜/人类获胜/平局分别对应100/0/50分):
忠实性:能否准确反映方法逻辑;
简洁性:是否避免视觉杂乱;
可读性:布局和文字是否清晰易懂;
美学性:是否符合学术配图规范。
需要注意的是,这四个维度并非相互平行。根据“首先展示真相(show the truth first)”原则,忠实性和可读性是主要维度。若在主要维度上分不出胜负,才会在次要维度上继续比拼,以此确保技术准确性永远高于视觉吸引力。
为了确保评测可靠,研究团队专门验证了这个方法与人类评判的Kendall’s tau相关系数达0.45,证明视觉语言模型(VLM)裁判能有效模拟人类的审美与逻辑判断。
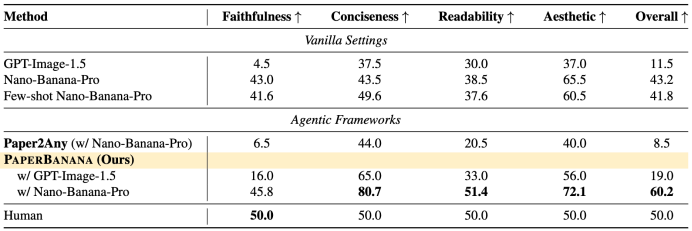
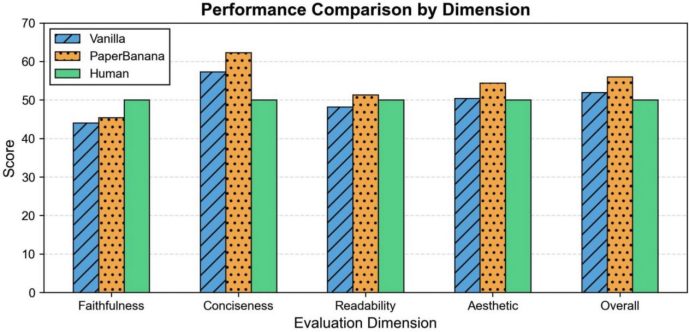
结果显示,PaperBanana取得了60.2的综合得分,全面超越了基线方法,直接使用文生图只能得到43.2的分数。其中,相比直接使用文生图,四个维度中的简洁性提升最为明显(37.2%)。
此外,由于采用相对评分制,研究团队将人类绘制的参考配图的综合得分和在四个维度上的得分均设置为50,而PaperBanana的生成结果在忠实性以外的三个维度都已超越人类水平。
另一项实验邀请了三位人类评委,对由50个案例组成的子集进行盲测,用来比较PaperBanana和文生图的效果。最后,PaperBanana以72.7%的胜率碾压了文生图获胜。
与此同时,PaperBanana还展现出强大的泛化能力。
相比方法论示意图,学术论文中的统计图对数值精度的要求更为苛刻。PaperBanana放弃了直接生成图像,而是通过调整渲染师和批评家的功能定位,将语言描述转化为可执行的Matplotlib代码。
这种策略在密集的数据点场景下能够有效避免重复绘制等问题,相比纯图像生成方案显著提高了忠实度。
04 结语:局限与意义
研究团队在最后也坦承了PaperBanana现存的局限性。
最大的挑战在于输出格式仍为位图,这决定了PaperBanana生成的配图无法像矢量图一样无损缩放,不太适用于需要精细排版和印刷的学术图表。
研究团队表示未来将结合OCR和SAM3技术进行元素级重构,或是训练GUI Agent直接操作专业软件来生成原生矢量图。
另外,细粒度忠实度也有明显的提升空间。
现有的失败案例大多是由于箭头起止点有微小偏移、模块边界模糊等微观失真现象引起的。这些错误能够逃过批评家的检测,主要还是因为视觉语言模型对像素级视觉关系的感知能力有限。
因此,自动化配图不仅是生成问题,还是视觉理解问题,需要基础模型能力的持续跟进。
但是,PaperBanana也有相当重要的意义。
它大大节约了科研人员的绘图时间,让创造力从视觉实现中得以解放,更专注于科学思想的凝练和表达。
AI赋能科研的本质绝非替代人类独有的创新性思维,而是帮助人们扫清创造力发散时遇到的阻碍。
更重要的是,它揭示了一种更加普适的技术范式:用检索驱动机制教会模型该生成什么,用自动风格归纳教会模型该如何生成。
相比现有的文生图技术,这种方法能够更快速、更精准地落实专业领域的视觉规范,而无需昂贵的微调。这一技术范式具备显著的可扩展性,未来,其核心思想可能为多种专业的图像生成场景提供通用的解决方案。
