
作者 | 程茜
编辑 | 漠影
机器人前瞻1月27日报道,今日,蚂蚁集团旗下具身智能公司灵波科技正式开源高精度空间感知模型LingBot-Depth,搭载LingBot-Depth模型的奥比中光Gemini 330系列相机在深度精度和像素覆盖率方面,均优于顶级深度相机。
蚂蚁灵波公布的一系列下游任务实验结果进一步表明,LingBot-Depth可在RGB与深度模态间,输出精准对齐的潜在特征表示,让灵巧手在抓取高度透明和反光物体时的成功率大大提升。

当下关于机器人落地应用的美好构想层出不穷,但要让这些设想照进现实,有一个核心前提绕不开:机器人必须能与物理世界顺畅交互。小到抬手从桌上取一杯水,大到完成各类复杂的实景作业,所有操作的第一步,都得让机器人先明确一个关键问题:“我在哪?”
但当下常见的空间定位感知方式,会因镜面反射、无纹理表面等情况产生深度误差,就意味着机器人获取的环境几何信息是模糊、失真的。机器人连基础的“我在哪”都无法明确,更无从谈起后续的精准操作与交互,这正是LingBot-Depth模型要解决的痛点。
从行业价值来看,该模型的核心突破在于用算法创新弥补了硬件短板,无需更换高端传感器,就能让消费级RGB-D相机实现超高性能,这恰好契合了当前工业、服务机器人领域对高精度、低成本感知方案的迫切需求,也为具身智能三维空间感知能力从基础层避障导航,向更高级别的复杂场景建模、人类级空间理解迈进提供了关键技术支撑。
在NYUv2、ETH3D等主流3D视觉基准评测中,相较于PromptDA、PriorDA等业界主流深度补全模型,LingBot-Depth在室内场景下相对误差(REL)降幅超70%,在高挑战性的稀疏SfM任务中,均方根误差(RMSE)也降低约47%。
目前,蚂蚁灵波已经开源了代码、检查点,并计划于近期开源300万个RGB深度对,包括200万个真实数据和100万个合成数据。该公司此次将模型代码与数据全链路开源,或倒逼RGB-D相机硬件的优化升级,进一步提升模型在真实长尾场景中的鲁棒性,让机器人、自动驾驶汽车等产品加速走进现实场景。
▲GitHub开源主页
01.
解锁机器人高精度空间感知
实测性能超越主流模型
一句话总结,LingBot-Depth模型解决的是让机器人具有精确的空间视觉感知能力,也就是看清楚、知道自己在哪里。
先来看下这一模型的性能表现。根据蚂蚁灵波公开的技术报告,其实验结果表明,LingBot-Depth模型在深度精度与像素覆盖率两项核心指标上均超越业界顶级深度相机。
对于机器人而言,其在抓取透明、反光物体时时常会出现判断失误的情况。测试结果显示,LingBot-Depth模型透明收纳箱抓取成功率从0%提升至50%,同时在多种反光和透明物体上提升了30%~78%的抓取成功率。
具体来看,在深度补全任务上,该模型与主流的深度补全模型OMNI-DC、PromptDA、PriorDA相比,基于分块深度掩码法和稀疏摄影测量(SfM)深度输入法进行了效果对比。LingBot-Depth模型在室内、室外场景下的预测深度与真实深度的偏差都相对更小,显著优于当前主流的基线方法。
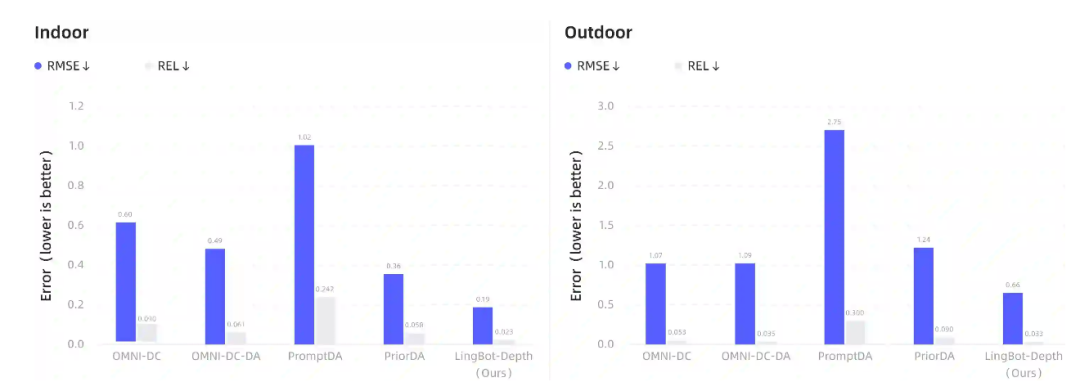
▲LingBot-Depth模型与主流模型相比的效果
在分块深度掩码法的评测设置下,LingBot-Depth模型在不同难度等级中性能均持续优于其他模型,证明了该模型面对重度掩码和噪声干扰时具备较优抗干扰能力。
在稀疏摄影测量(SfM)深度输入法设置下,LingBot-Depth模型生成的深度图具备更清晰的深度边界和更连贯的结构特征,并且在遮挡严重或观测信息稀疏的区域优势更为明显。
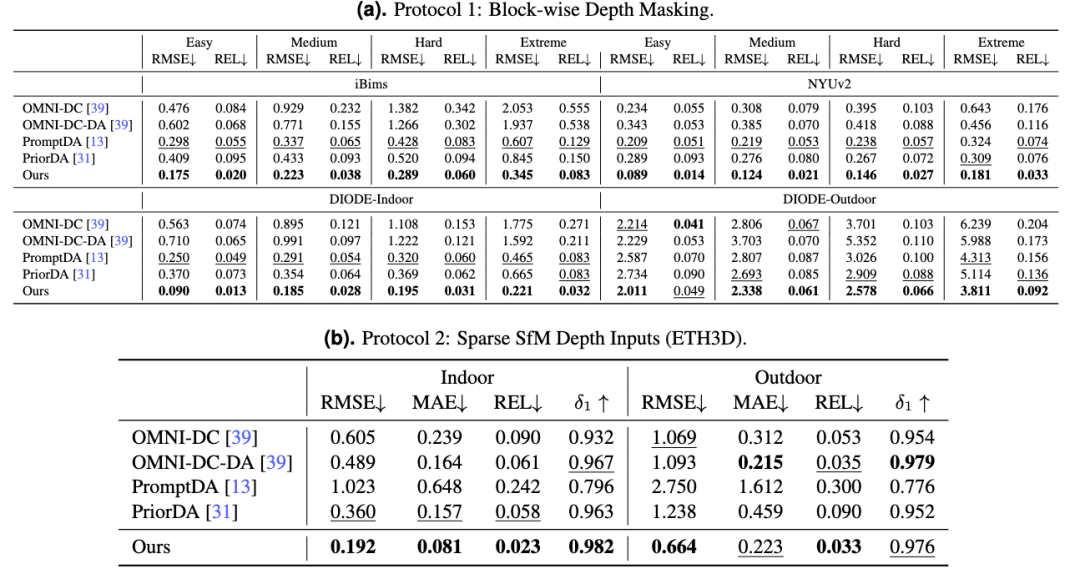
▲两种协议下的模型对比效果
如下图所示,LingBot-Depth模型生成的图像包含更清晰的边界和更完整的结构。

单目深度估计能力上,LingBot-Depth模型在10项基准上的表现均优于视觉模型DINOv2,其测试结果显示,LingBot-Depth模型的预训练范式可以有效地将3D几何知识提炼到编码器中,提高其从单目图像推断深度结构的能力。
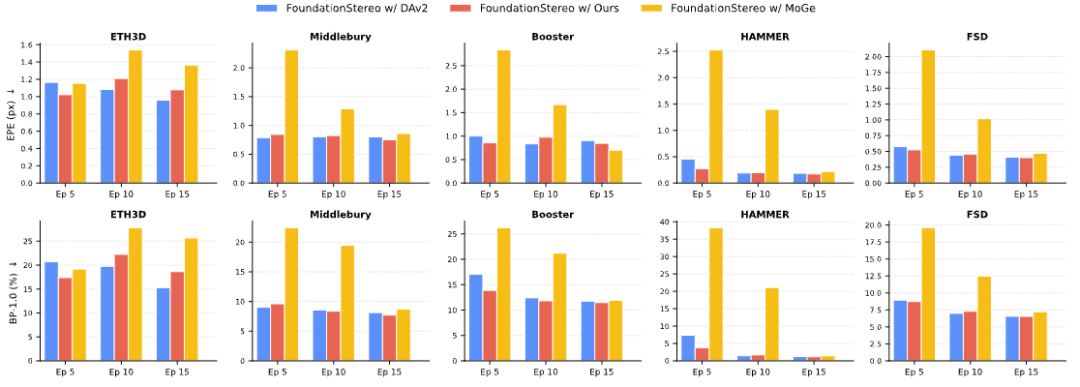
研究人员还将LingBot-Depth模型,作为强单目深度先验融入FoundationStereo模型中,结果显示加速双目匹配模型训练后,FoundationStereo收敛更快。
从性能表现来看,LingBot-Depth 模型不仅验证了其技术路径的有效性,更凸显了其背后深刻的行业价值。
最直观的就是,LingBot-Depth模型有效攻克了机器人空间感知的核心痛点,即便是传统相机难以捕捉的低纹理、遮挡或弱光区域,机器人也能通过该模型实现清晰感知。同时,它显著缩小了普通消费级RGB-D相机与高端深度相机之间的性能差距,让低成本设备也能输出接近专业级的深度数据,为机器人等各类智能设备的空间感知能力筑牢了技术根基。
02.
LingBot-Depth要让机器人看清路、定准位
就像人类出行需要通过视觉清晰感知路况、判断距离、定位自身位置一样,机器人执行任务时也依赖精准的空间视觉感知能力,既需要看懂周围的三维布局,还要准确定位自己的坐标。
这种能力是机器人实现自主导航、避障和复杂操作的底层基础,而追求精确的三维感知已成为基于物理的AI研究的核心支柱,其重要性不言而喻。
从行业落地视角来看,让机器人实现稳定、有效的空间感知,需满足三大核心标准:具备绝对度量尺度、能输出像素级对齐的稠密几何信息、支持无需高算力后处理的实时采集。而目前业内唯一能同时满足这些实时性要求的成像方案,唯有RGB-D相机。
然而,RGB-D相机的硬件短板却成为技术规模化应用的关键掣肘之一。受固有的硬件局限影响,基于双目的深度相机方式,会通过两个镜头从略有差异的视角同时拍摄场景,系统通过匹配两幅图像中的对应点来计算深度。
但该相机在面对光滑、镜面反射、反光等复杂光照条件,其依靠像素级局部纹理进行推理、猜测补全缺失图像的策略就会失效,而这些复杂场景在真实的工厂、家庭等环境很常见。
LingBot-Depth模型的出现,正是为破解这一行业核心痛点提供了切实可行的技术路径,其背后的杀手锏就是MDM(掩码深度建模)。
MDM相对应的就是此前主流MAE(掩码自编码器)方法的局限性,MAE在训练过程中无法学习和理解真实物理世界的空间几何规律。
而MDM在训练时将RGB-D传感器的天然深度缺失作为“原生掩码”,将传感器失效区域视为可学习的结构线索而非简单噪声,通过掩码深度建模(Masked Depth Modeling, MDM)机制充分利用 RGB 图像中的视觉上下文信息,对缺失深度区域进行智能推断与补全。模型在补全真实深度缺失的过程中,可以学出贴合物理世界的度量级、高精度完整深度表示。
简单说,MDM就是将传感器的缺陷变成了训练AI的素材,让AI学习真实世界的物理规则,而不是人工编的假规则,这使得最后练出的AI能精准测出真实的3D距离。
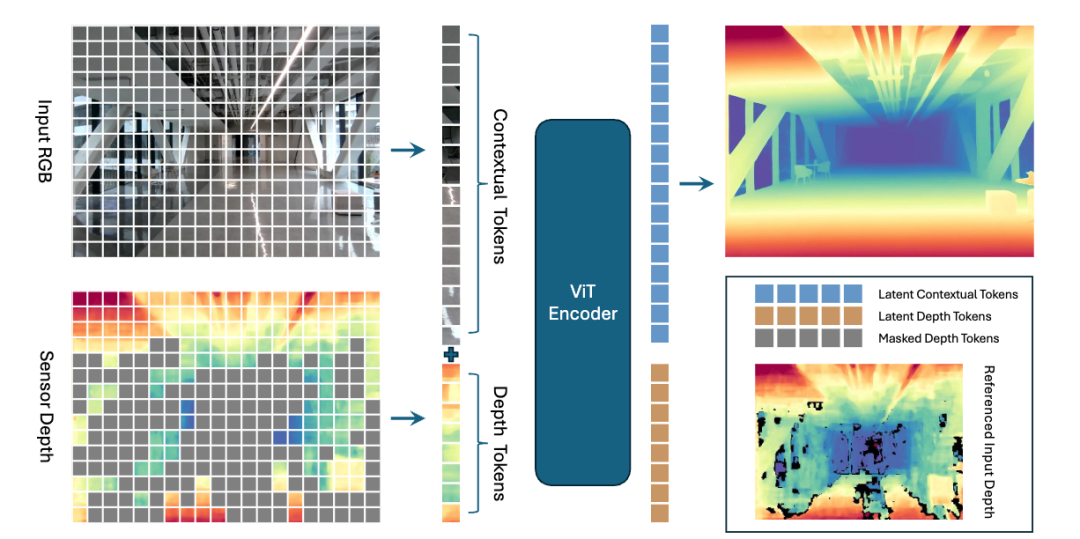
如此一来,模型便能逐步习得这类空间感知规律:当识别到玻璃类的视觉外观与反射特征时,就能精准推断出其对应的深度范围。
在此之上,基于统一单目深度估计和深度补全的目标,MDM框架可以作为通用的多功能模型,从任意RGB-D输入生成度量尺度、像素对齐的密集深度图。
机器人行业正迈向规模化应用落地的关键阶段,蚂蚁灵波在MDM机制上的探索在攻克精准空间感知这一核心难题上提出了新解法,或加速机器人真正迈入自主感知、自主决策、自主执行的智能新阶段。
03.
千万级样本炼就机器人“火眼金睛”
让机器人灵巧操作落地可期
找对可行路径,下一步要做的就是落地实现。
为支持大规模MDM训练,研究人员首先搭建了一套可扩展的数据整理流程,实现原始传感器数据与可靠监督信息的高效对接。该流程设计两大并行数据分支,分别是基于自托管的3D资产生成合成数据,以及通过模块化3D打印采集装置完成实景数据采集,这一装置兼容主动立体相机(Intel RealSense、奥比中光Gemini)和被动立体相机(ZED)等多款消费级RGB-D相机。

基于这一套设计,其累计获取了100万个合成样本、200万个真实世界样本,所有样本均包含同步的RGB图像、原始传感器深度数据及立体图像对。

其中立体图像对的伪深度监督,由基于FoundationStereo、经合成数据训练的自定义立体匹配网络实现。研究人员还融合多个公开RGB-D数据集丰富了数据语料库,最终构建出包含1000万条样本的多样化高质量训练集。
结合该RGB-D语料库,研究人员采用掩码深度建模方式对ViT-Large模型进行预训练,通过注意力机制将度量几何信息融入语义标记,可有效提升RGB-D相机的空间感知质量。
在可扩展双支数据整理流程、超大规模高质量训练集、针对性预训练优化感知这样的全栈技术创新下,LingBot-Depth模型已经有了落地到实际应用的潜力。
因此,研究人员基于LingBot-Depth模型开展了多组实验验证,选用Orbbec Gemini-335相机作为RGB-D输入设备,完成了3D点跟踪、灵巧手抓取等典型任务的实测验证。
可以看到在3D点跟踪案例中,当场景包含大面积的玻璃时,原始深度传感器会严重失效,经LingBot-Depth模型优化后的深度数据,能够生成更加平滑和精确的相机轨迹。

▲原始相机和基于LingBot-Depth模型优化的3D跟踪效果对比
还有真实世界的灵巧手抓取,其采用了配备X Hand-1灵巧手的Rokae XMate-SR5机械臂、用于感知的Orbbec Gemini 335 RGB-D相机。LingBot-Depth模型在抓取高度透明物体时的成功率达到50%,但原始方法完全无法抓取。

▲灵巧手抓取成功率对比
虽然这些只是在实验室的测试,但这些测试场景均对标了机器人落地应用中的高频实际场景,已充分展现出该技术方案的高实用性与落地潜力。
04.
结语:让机器人看懂物理世界的关键一步
整体而言,LingBot-Depth模型在解决机器人空间感知能力核心痛点上更进一步,既实现了感知性能的提升,又大幅降低了技术落地成本,为各类智能应用的开发筑牢了技术基础,是推动机器人真正“看懂”物理世界的关键突破。
对于开发者而言,其无需再从零开展空间感知的基础研究,可直接基于该模型快速搭建各类应用,这将大幅加速一众智能设备的研发与落地进程,让机器人、自动驾驶汽车等产品更快从技术概念走进现实场景。
