IT之家 1 月 26 日消息,Digital Trends 24 日报道,一项由训练数据公司 Mercor 发布的研究报告指出,当前主流人工智能模型在处理实际办公室任务时表现不佳,最高准确率未超过 25%,研究表明 AI 在短期内难以替代人类知识工作者。

该研究基于 Mercor 新推出的 APEX-Agents 基准进行测试,有别于传统上通过写诗和解数学题为主的 AI 评估方法,该基准测试直接采用律师、顾问和银行家的真实工作流,要求受试模型完成横跨多个信息来源的多步骤综合任务。
结果显示,即使是市场上明显处于领先地位的模型也无法达到 25% 的准确率,测试中成绩领先的 Gemini 3 Flash 和 GPT-5.2,其准确率也仅为 24% 和 23%,而其他大多数受试模型的成绩则不高于 20%。
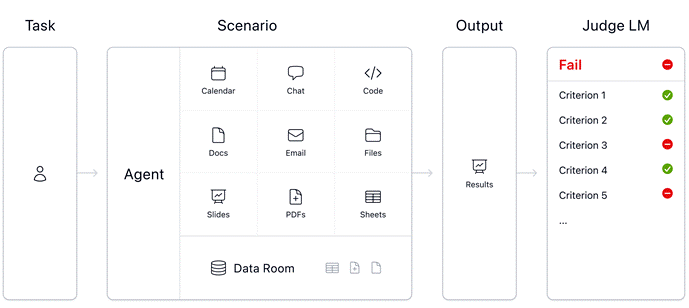
为何 AI 会在“办公测试”中失败?Mercor 首席执行官 Brendan Foody 分析称,AI 失败的关键在于缺乏上下文处理能力。在真实办公场景中,任务往往需要整合分散资源,比如查看日程,翻阅即时通讯记录、阅读 PDF 文档和电子表格,而 AI 在跨源信息搜索与整理时容易混淆、出错,要么干脆放弃。这导致目前的 AI 在办公室里更像一个“不可靠的实习生”,而非成熟的专业人员。
IT之家附 APEX-Agents 准确率测试结果如下(排名从高到低):
Gemini 3 Flash (High) – 24.0%
GPT-5.2 (High) – 23.0%
Claude Opus 4.5 (High) – 18.4%
Gemini 3 Pro (High) – 18.4%
GPT-5 (High) – 18.3%
Grok 4 – 15.2%
GPT-OSS-120B (High) – 4.7%
Kimi K2 Thinking – 4.0%
尽管表现有限,但 AI 的进步引人关注。Foody 指出,一年前同类测试的准确率仅为 5%-10%,如今已提升至 24%,AI 的学习速度远超预期。不过,研究也强调,在掌握多任务处理和上下文切换之前,AI 尚无法胜任复杂的知识工作。
