
智东西
作者 | 李水青
编辑 | 心缘
智东西1月14日报道,今天,首个在国产芯片上完成全程训练的SOTA(最佳水平)多模态模型开源。
这是智谱联合华为开源的图像生成模型GLM-Image。从数据到训练的全流程,该模型完全基于昇腾Atlas 800T A2设备和昇思MindSpore AI框架完成构建。
截至今日午间休市,智谱股价上涨16.83%。
在聚焦文字渲染的CVTG-2K、LongText-Bench榜单上,GLM-Image的得分超越了以谷歌Nano Banana Pro为代表的认知型生成模型。
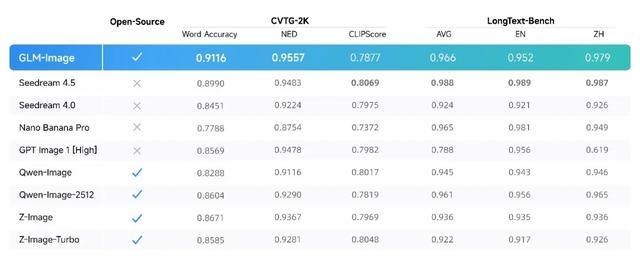
GLM-Image在文字渲染的CVTG-2K、LongText-Bench榜单中达到开源SOTA水平
GLM-Image实现了图像生成与语言模型的联合,核心亮点如下:
1、架构革新,面向「认知型生成」的技术探索:采用创新的「自回归 + 扩散编码器」混合架构,兼顾全局指令理解与局部细节刻画,克服了海报、PPT、科普图等知识密集型场景生成难题。
2、首个在国产芯片完成全程训练的SOTA模型:模型自回归结构基座基于昇腾Atlas 800T A2设备与昇思MindSpore AI框架,验证了在国产全栈算力底座上训练前沿模型的可行性。
3、文字渲染开源SOTA:在CVTG-2K(复杂视觉文本生成)和LongText-Bench(长文本渲染)榜单获得开源第一,尤其擅长汉字生成任务。
4、高性价比与速度优化:API调用模式下,生成一张图片仅需0.1元,速度优化版本即将更新。
智东西第一时间对GLM-Image进行了体验,发现模型在汉字生成上准确度很高,优于谷歌Nano Banana Pro以及多款头部国内模型;能够较准确理解深层语义和知识概念,并将其转化为正确的视觉元素;能够在保证全局构图的同时较精准刻画局部细节。
同时,GLM-Image也存在字体风格呈现不准、生成需要等待时间、一些科学概念理解不足等问题;且相比于一些免费选择,其仍需要收取少量费用。
体验地址:
https://bigmodel.cn/trialcenter/modeltrial/image
GitHub地址:
https://github.com/zai-org/GLM-Image
技术报告地址:
https://z.ai/blog/glm-image
GLM-Image体验界面
一、从数据到训练,首个国产芯片训练出的SOTA模型
GLM-Image自回归结构基座从早期的数据预处理,到最终的大规模预训练,全流程均在昇腾Atlas 800T A2设备上完成。
依托昇腾NPU和昇思MindSpore AI框架,使用动态图多级流水下发、高性能融合算子、多流并行等特性,智谱自研了模型训练套件,全面优化数据预处理、预训练、SFT和RL的端到端流程。
具体来说,通过动态图的多级流水优化机制,团队将Host侧算子下发的关键阶段流水化并高度重叠,消除下发瓶颈;通过多流并行策略,通信和计算互掩,团队打破文本梯度同步、图像特征广播等操作的通信墙,极致优化性能;使用AdamW EMA、COC、RMS Norm等昇腾亲和的高性能融合算子,团队同步提升训练的稳定性和性能。
作为首个在国产芯片上完成全流程训练的SOTA多模态模型,GLM-Image验证了在国产全栈算力底座上训练高性能多模态生成模型的可行性。
二、文字渲染达开源SOTA,实测汉字生成超Nano Banana Pro
GLM-Image在文字渲染的权威榜单中达到开源SOTA水平。
CVTG-2K(复杂视觉文字生成)榜单核心考察模型在图像中同时生成多处文字的准确性。在多区域文字生成准确率上,GLM-Image凭借0.9116的Word Accuracy(文字准确率)成绩,位列开源模型第一。在NED(归一化编辑距离)指标上,GLM-Image同样以0.9557领先,表明其生成的文字与目标文字高度一致,错字、漏字情况更少。
LongText-Bench(长文本渲染)榜单考察模型渲染长文本、多行文字的准确性,覆盖招牌、海报、PPT、对话框等8种文字密集场景,并分设中英双语测试,GLM-Image以英文0.952、中文0.979的成绩位列开源模型第一。
智东西对GLM-Image的实测体验侧重文字渲染能力,对比谷歌Nano Banana Pro、豆包、阿里通义万相2.6几款常见同类模型,GLM-Image在文字渲染准确度和细节刻画上表现较好,但也存在字体风格不准确、科学概念理解不足等问题,不过后面这几个问题Nano Banana Pro也难幸免。
提示词1:
设计一个“新中式奶茶店”的商标(Logo)和店铺外观概念图。
Logo部分:需要包含“茶悦”二字,设计要融合传统书法韵味和现代简约风格。
店铺外观:是一个现代玻璃橱窗小店,但门头、招牌或装饰中要巧妙运用竹元素或山水纹样。
整体感觉:干净、雅致、有文化气息,同时吸引年轻人。
生成建议:“茶悦”二字可以尝试用细笔触的行书,搭配一个抽象的茶杯或茶叶形状。店铺外观可以是浅木色和留白为主,用竹格栅做装饰,玻璃上若有若无地映出山水画痕迹。
如下图所示,GLM-Image在汉字生成上比较准确,但未采用“行书”;对文字描述的设计细节呈现准确,抽象的茶杯设计较传神;对中国文化元素(书法、竹、山水)的理解和现代转译能力较强;室内陈设格局清晰,符合商业设计场景要求。

GLM-Image生成的图片
谷歌Nano Banana Pro没有能够准确生成汉字,但对于画面的呈现也比较准确,室内的陈设清晰且细节丰富,实拍感较强。

Nano Banana Pro生成的图片
豆包没有准确生成“茶悦”二字,没有按要求生成“一个抽象的茶杯或茶叶形状”,但在门头、招牌或装饰中要巧妙运用了竹元素或山水纹样,设计比较独特。

豆包生成的图片
阿里通义万相2.6准确生成了“茶悦”二字,也按要求生成了一个抽象的茶杯或茶叶形状,但字体同样没有采用“行书”,店面的内部构造生成细节相对不多。

阿里通义万相2.6生成的图片
提示词2:
画一张给小学生看的“光合作用示意图”。图中需要包含一棵有笑脸的植物、一个大太阳、代表二氧化碳(CO₂)的箭头从空气指向叶子、代表氧气(O₂)的箭头从叶子中冒出。在图片下方,用清晰易懂的字体标注解释:“植物利用阳光、水和二氧化碳,制造出氧气和养分”。整体风格需生动可爱,兼具科学性和趣味性。
如下图所示,GLM-Image保证了全局构图风格可爱、场景完整,对“光合作用”这一科学概念有一定的理解能力,但氧气的箭头打反了,释放氧气应该是箭头向外。

GLM-Image生成的图片
不过,Nano Banana Pro也没有做对这道题,氧气的箭头也画反了,且汉字生成上一塌糊涂,全都乱码了。

Nano Banana Pro生成的图片
豆包在这道题上完成度较高,不仅准确生成了汉字,还理解了光合作用概念,将抽象概念转却转化为了具象的视觉符号。

豆包生成的图片
阿里通义万相2.6也能够准确生成文字,并且用视觉符号呈现了“光合作用”吸收二氧化碳、释放氧气的过程,但仍有一个二氧化碳的箭头向外打,可能将“呼吸作用”也考虑进来了;比其他模型多表现了根系吸收水分这一部分原理。

阿里通义万相2.6生成的图片
三、自回归 + 扩散编码器架构创新:读懂指令,写对文字
当下,以Nano Banana Pro为代表的闭源图像生成模型,正在推动图像生成与大语言模型的深度融合。模型在海报、PPT、科普图等知识密集型场景及高保真细节上的表现,展现了认知型生成模型的技术优势。
GLM-Image是首个开源的工业表现级离散自回归图像生成模型,是智谱面向认知型生成技术范式的一次重要探索。
创新架构,让模型能够读懂写对。面对传统模型在“理解复杂指令”与“精准绘制文字”上难以兼顾的问题,GLM-Image 引入了「自回归+扩散解码器」混合架构,创新地融合了9B大小的自回归模型与7B大小的DiT扩散解码器。
前者利用其语言模型的底座优势,专注于提升对指令的语义理解和画面的全局构图;后者配合Glyph Encoder的文本编码器,专注于还原图像的高频细节和文字笔画,以此改善模型“提笔忘字”的现象。
GLM-Image还具备多分辨率自适应能力。通过改进Tokenizer策略,GLM-Image能够自适应处理多种分辨率,原生支持从1024×1024到2048×2048尺寸的任意比例图像的生成任务,无需重新训练。
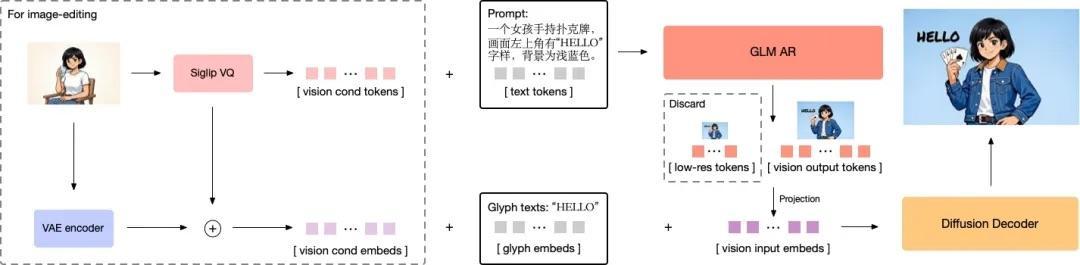
通用pipeline
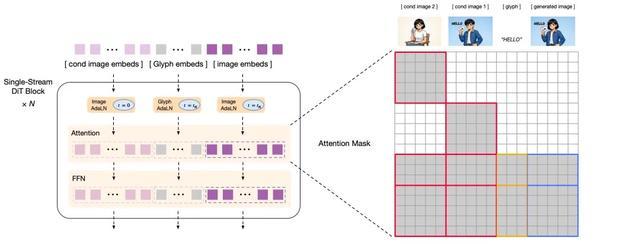
解码器结构示意图
结语:纯血国产大模型进击,从“可用”到“好用”
GLM-Image的诞生,标志着国产大模型探索进入了从“可用”到“好用”的关键阶段。它以“自回归+扩散”的混合架构破解了“图文协同”的生成难题,同时凭借在国产昇腾算力上完成全流程训练的实践,证明了自主技术栈支撑前沿AI创新的可行性。
作为一款在文字渲染任务上达到开源SOTA的模型,它为海报设计、知识科普等需要精准图文融合的场景提供了高性价比的新选择,同时有望为整个AI产业生态的自主化与多元化打基础。
