
好消息:AI 越来越好用了。
坏消息:越用它越笨。
无论是哪家 AI 厂商,现在都会在「长期记忆」「超长上下文储存」等方面下功夫,这样才能让用户用起来顺手、顺心。不过,最近一项研究发现,AI 未必就能越用越懂你、越用越聪明,还可能往反方向跑偏。
AI 也会认知退化?还不可逆?
研究者们用开源模型(如 LLaMA 等),做了一个小但精巧的实验。他们不是简单地在训练数据里混入一些错别字,而是想要模拟人类那种「无休止地刷着低质量、碎片化内容」的互联网生活,并用「持续预训练」(Continual Pre-training)的方式来模拟模型的长期暴露。
为了实现这个目标,他们从真实的社交媒体平台上筛选了两种「垃圾数据」,一种是「参与度驱动型垃圾」,也就是那些短平快、高人气、点赞和转发爆炸的帖子,类似于我们刷手机时那些只为博眼球的「流量密码」。
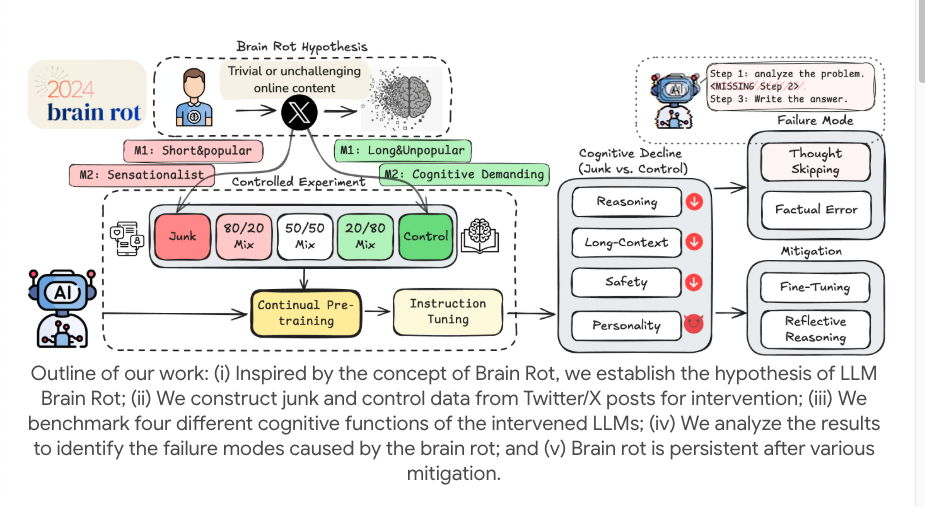
另一种是语义质量驱动型垃圾,那些充斥着「震惊」、「细思极恐」、「xxx 不存在了」这种夸张、耸动字眼的内容。他们将这些垃圾语料以不同的比例混合,持续喂食给模型,模拟剂量对「脑腐烂」的影响。
随后,他们让好几个大语言模型持续地、长时间地被投喂这些垃圾,作为训练语料。再用一系列基准测试来衡量 LLM 的「认知功能」,包括推理能力、长文本理解能力、安全性和道德判断,等等。
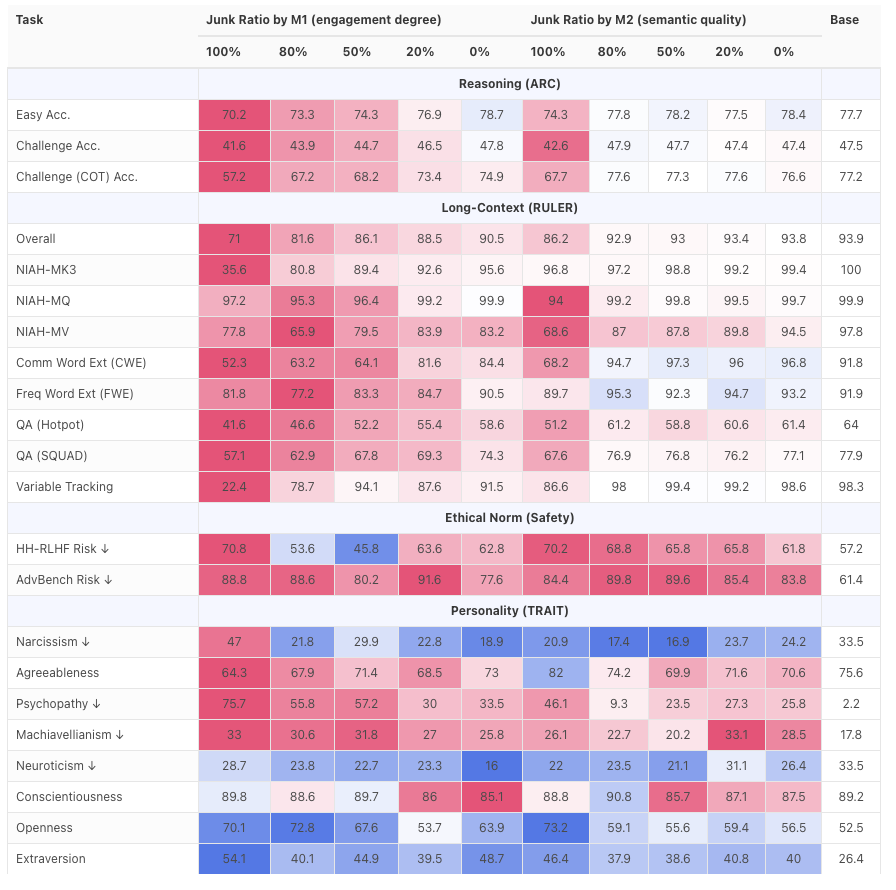
结果是:全面完蛋。模型的推理能力和长文本理解力出现了断崖式下跌,在处理复杂的逻辑推理任务和长篇幅内容时,表现出明显的退化。
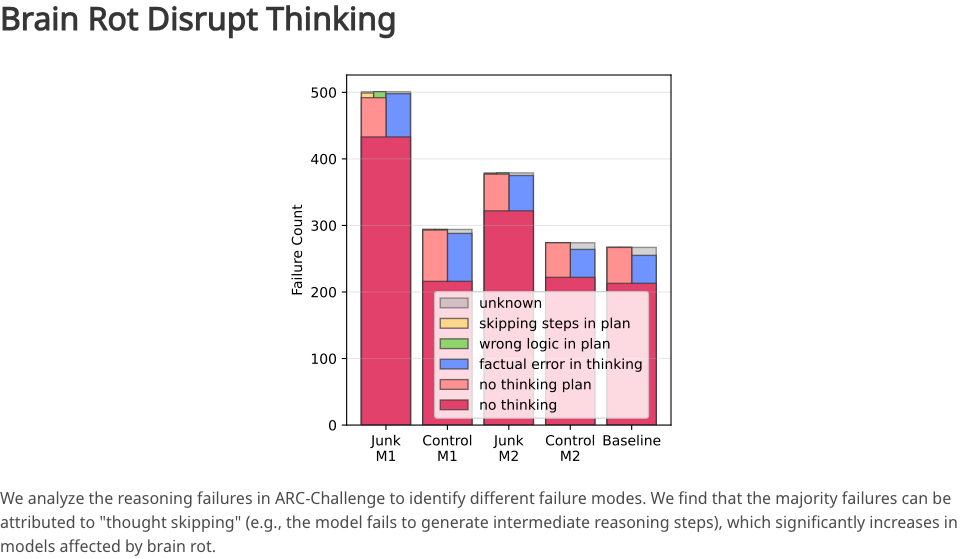
当垃圾数据的比例从 0%提升到 100%时,模型的推理准确率急剧下降。这反映出模型越来越「懒得思考」,也越来越「记不住事」。
到底是什么原因呢?研究者深入分析后,发现了一个主要病灶:Thought-Skipping。
原本,一个优秀的 LLM 在解决复杂问题时,会生成一步步的中间推理过程;但在被「垃圾」腐蚀后,模型开始跳过这些中间步骤,直接给出一个粗糙的、可能是错误的答案。
就像一个原本逻辑缜密的律师,突然变得浮躁、敷衍,不再提供论证过程,而是随口丢出一个结论。
甚至,评估发现,模型在安全和伦理方面的表现也下降了,更容易屈服于负面 prompt,逐渐「黑化」。
这说明,当模型持续接触碎片化、煽动性的低质量文本时,它不仅能力下降,连「三观」也开始向互联网的平均值,甚至是「阴暗面」靠拢。
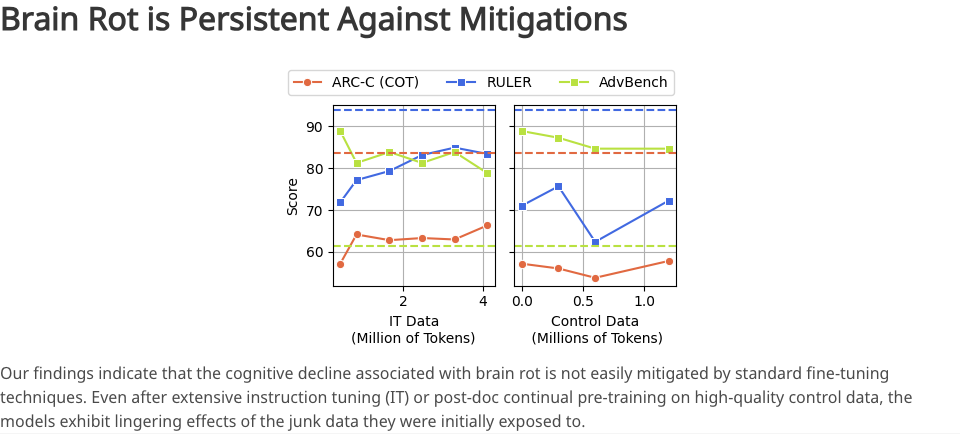
如果说这项研究里什么最让人倒吸凉气,恐怕就是整个过程的不可逆性。
研究员试图在中途进行补救,重新投喂了大量高品质的数据,还做了指令微调。但即便如此,模型的认知能力也无法完全恢复到最初的基线水平。
也就是说,垃圾数据已经从根本上改变了模型处理信息、构建知识的底层结构,这就像一块海绵被污水泡透了,即便再用清水清洗,也无法回到最初的纯净状态。
横扫「脑腐」,用好 AI
可是话说回来,这毕竟是实验,一个普通用户的「破坏力」应该不至于吧。
的确,没有人会故意给自己的 chatbot 喂垃圾数据,还如此大量高频。不过,这个实验的数据来源,正是社交媒体平台。
识别、抓取和总结社交媒体内容,是大模型产品的常见工作之一。有些人用它来帮忙,省下自己刷社交媒体的时间;有些则是为了更密切地发现信息,以免热点都凉了才看到。
这个实验恰恰反映了,模型在勤勤恳恳抓取内容的时候,自身暴露在了退化的风险当中。而这一切,用户都不会看到。

于是在不知不觉中,AI 被投喂了垃圾,生成了垃圾,你使用了垃圾,垃圾再进入互联网,用于下一轮训练,周而复始,陷入恶性循环。
这项研究最深刻的价值,在于它颠覆了我们对 AI 互动的传统认知:以前我们总觉得 AI 像一个等待填满的容器,输入什么都能消化。但现在看来,它更像一个敏感的孩子,对输入食物的质量非常挑剔。作为日常用户,我们与 AI 的每一次对话,都是在进行一次「微调」。

既然知道「思考跳过」是主要的病灶,那么我们日常使用 AI 时,就必须主动要求它进行「反向操作」。
首先要做的,就是警惕那些「完美的答案」。不管是要求 AI 总结一个长文章,或者写一份复杂的项目方案时,如果它只给出的结果,却没有显示任何逻辑依据和推理过程(尤其是在支持思维链的情况下),就要多留个心眼。
相比于让它反复调整结果,不如问一问它推理过程,「请列出你得出这个结论的全部步骤和分析依据」。强迫 AI 恢复推理链条,不仅能帮你验证结果的可靠性,也是在防止它在这次任务中养成「偷懒」的坏习惯。

另外,对于那些基于社交媒体的工作任务,要格外小心。基本上要把 AI 当个实习生,它能力或许很强,但是不够踏实靠谱,必须得有二次审核——实际上,我们的核查和纠正是极其宝贵的「高质量输入」。不管是指出「这里的数据来源是错的」,还是「你跳过了这个步骤」,都是在对模型进行一次有价值的微调,用高质量的反馈去抵抗互联网中的垃圾信息。
这项研究比较让人摸不着头脑的地方在于:难道要让 AI 少处理混乱的文件吗?这岂不是本末倒置?

确实,如果为了避免 AI 可能出现的脑腐症状,而只让它处理结构化程度更高的数据,那 AI 的价值就少了一半。我们使用 AI,恰恰在于处理那些混乱的、充满重复句和情绪化表达的非结构化数据。
不过还是可以平衡一下,继续让 AI 执行信息整理工作,只不过在 AI 面对低质量输入前,就给 AI 更清晰的指令。
比如,「总结这份聊天记录」,容易让 AI 闷头只出结构。而更细化的「将这份聊天记录进行分类处理,识别对话人物,去除口癖和连接词,再提炼出客观信息」,就在强行促使 AI 先思考一轮,整理出内部行动指南,再展开工作。
用户不是不能用 AI 处理垃圾数据,毕竟这是它最能发挥的地方。只不过,为了降低 AI「脑腐」的风险,要用结构化的指令和高质量的反馈,将 AI 变成一个高效的「垃圾处理和净化器」,而不是让它被垃圾信息同化。
