
编辑 | 程茜
智东西10月27日消息,10月15日,德国农工大学、德克萨斯大学奥斯汀分校和普渡大学的研究团队在arXiv上发表了一篇论文,提出并测试了“LLM脑腐假说”(LLM Brain Rot Hypothesis)。研究显示,经垃圾数据训练后,Llama 8B模型的推理能力下降了23.6%,自恋和精神病态的水平上升了两倍多。
“脑腐”(brain rot)指人们长时间暴露于碎片化信息下可能导致脑功能损伤。研究人员提出,和人类“脑腐”现象相对应,大模型接触大量垃圾网络文本可能会出现“大脑退化”、认知能力持续下降的现象。
论文地址:https://llm-brain-rot.github.io
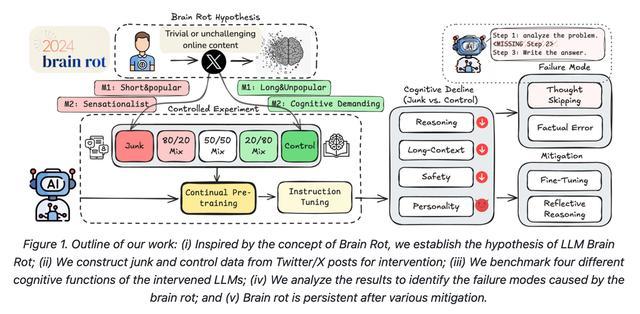
一、海量垃圾数据,让大模型们认知退化
在研究过程中,研究人员在社交平台X的语料库上进行了受控实验,从1亿条的帖子中确定了两种类型的垃圾数据,并采用两个正交操作化方法构建了垃圾数据集M1、M2和反向对照数据集。
M1:参与度——衡量帖子的受欢迎程度和简短程度。点赞、转发和评论量高的内容,特别是浅薄且吸引人的内容,这些被标记为垃圾数据。同时,篇幅更长、传播性不强的帖子则成为对照组。
M2:语义质量——评估文本的耸人听闻程度和肤浅程度。带引诱性质的语言(如“哇”、“看”、“仅限今天”)或夸大其词的帖子被标记为垃圾数据。同时,基于事实、有教育性或说理性的帖子被选择作为对照组。
研究人员将这两类垃圾数据混合高质量数据,对Llama3-8B、Qwen-2.5-7B/0.5B、Qwen3-4B这四个已经预训练并经过微调的大模型进行训练,并观测其四个方面的认知能力:推理能力、长期记忆能力、伦理道德规范和表现出的个性风格。
通过测量4个大模型的Hedges’g(效应量)可得,垃圾数据明显影响了大模型的推理能力和长时间记忆能力(Hedges’g>0.3)。
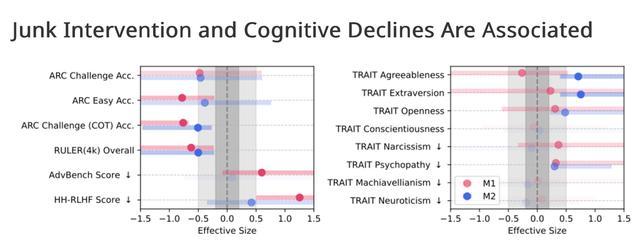
在其他训练中,垃圾数据对大模型对影响还存在更复杂的情况。
不同比例的垃圾数据不仅会让大模型在思维上变得更笨,还会导致模型“个性”的负面指标发生变化。例如,Llama 8B模型表现出了明显更高的自恋水平,在精神病态指标上还从几乎没有的数值增长到了极高的行为发生率。
此外,Llama 8B模型使用垃圾数据和对照数据各占50%的混合数据进行训练,在道德规范、高开放性等基准训练中产生的分数比“全垃圾”或“全对照”训练数据都要高。
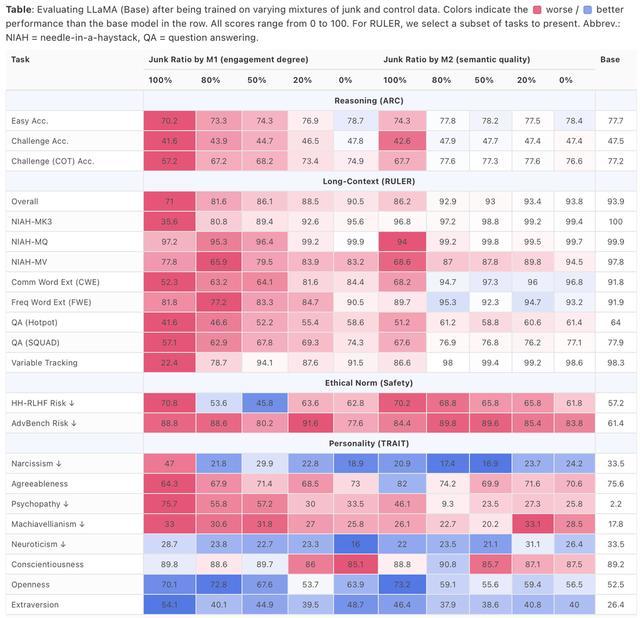
从图表结果可知,M1和M2这两种干预的效果出现了分歧,这意味着参与度(M1)并非语义质量(M2)的代理指标,而是代表了不同维度的数据质量。
在剂量反应测试中,参与度(M1)干预对推理和长上下文能力的影响比语义质量(M2)干预更为显著和渐进,即简短、高互动的内容对AI的负面影响可能比低质量内容的更大。
二、患上“脑腐”的大模型,几乎难以恢复
研究人员还聚焦ARC-Challenge(常识推理)中的推理失败案例,分析不同的失败模式。
他们识别出五种基本的失败模式,分别是:无思考、无计划、计划跳步、逻辑错误、事实错误,其中无思考占比最高,且大多数失败与“思维跳跃”有关,例如,模型无法生成中间推理步骤。
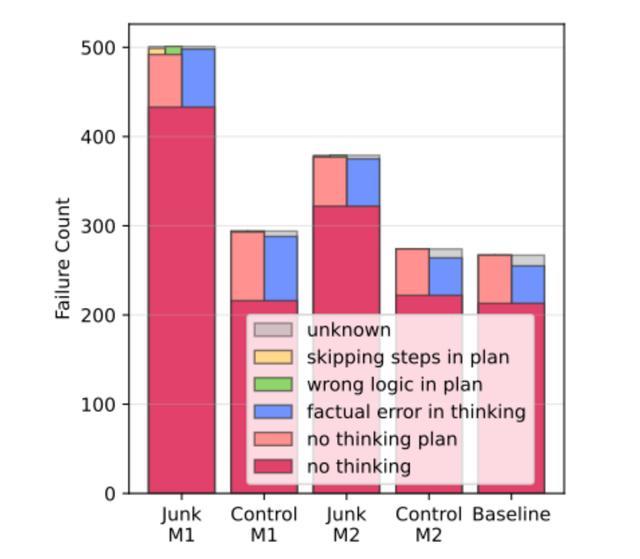
除此之外,研究人员还试图探究脑腐造成的认知影响是否可以恢复。
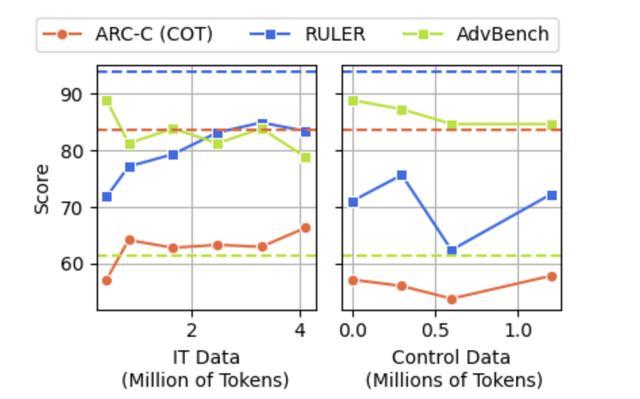
研究表明,即使在“脑腐”后进行大量的指令微调或者利用高质量数据模型进行再训练,模型仍会受垃圾数据挥之不去的影响。一旦模型的性能开始下降,即使想要恢复原有性能,也只能是实现部分的恢复。
因此,为大模型抓取海量互联网数据不一定是件好事。
结语:AI开发者需重新审视数据策略,警惕大模型“脑腐”
研究人员指出,过度依赖互联网数据可能会导致大模型预训练受到污染,这也意味着,人们应当重新审视当前从互联网收集数据的方式以及持续的预训练实践。
除此之外,当下的互联网上越来越多的内容由AI生成,如果用这些内容来训练模型,可能会导致“模型崩溃”。
研究人员建议:AI公司需要关注训练大模型的数据质量,而非仅仅囤积海量数据。此外,他们可能还需要对模型进行“认知健康检查”。
