凤凰网科技讯 10月24日,随着视频语言大模型(VideoLLMs)在多模态领域的迅猛发展,VideoLLMs在传统的视频语言任务中展示出了优越的性能,这吸引了学术界与工业界的广泛关注。然而,这些传统任务受限于视频时长过短、缺乏细粒度视频理解等问题,已不足以衡量最先进的VideoLLMs 对视频的理解和推理能力。
在多模态人工智能领域,近期对于视频语言评测的研究主要聚焦于长视频推理任务。然而,现有视频语言评测基准通常需要人工标注的参与,特别是对于小时级别的长视频标注工作,成本高昂且难以扩展。此外,多模态领域在探索未来更长期的视频理解与推理等各项任务上, 也亟需得到更多视频源的支持。
近期,香港中文大学王历伟教授带领的LaVi团队联合凤凰卫视、斯坦福大学、威斯康辛大学麦迪逊分校、利物浦大学等通过以下三个方面来解决上述的问题:
(1)研究团队提出了一个新颖的、富有挑战性的视频语言任务——“蒙太奇式的大海捞针”(Needle in a Montage,简称NeMo)。NeMo任务专门设计来评估VideoLLMs对于视频理解的重要能力,包括长上下文召回(long-context recall)和时间定位(temporal grounding)。
(2)研究团队为NeMo任务设计了一个可扩展的、自动化的数据生成方法(Automatic Data Generation Pipeline)。基于授权的、多样化的视频,自动化的数据生成方法可以快速生成高质量的视频语言评测数据。
(3)研究团队构建了一个以NeMo任务为中心的视频语言评测基准——NeMoBench。利用NeMoBench,研究团队对20个前沿的开源和闭源模型进行了大量的实验和评测分析,并为未来视频语言模型的发展提供建议。
1. 视频语言模型“理解即评测”的新理念
王历伟教授提到了“视频语言模型-理解即评测”的新理念。 “视频语言理解即评测。理解一个模型在视频语言理解的能力, 需要能够测试的方法, 但是自动化的测试数据的生成又需要对视频语言的理解。 因此,我们需要定义一个新任务, 这个新任务应该尽可能接近原始的复杂的视频语言任务,但是在难度上又可以降低到足够让自动化的方法来产生高质量数据。所以构建这样的评测任务的过程,其实就是在研究一种基于对视频的理解来快速生成视频语言数据的新方法。”
受到影片制作中Montage拼接剪辑手法的启发,研究团队提出了一种新颖的视频语言任务——“蒙太奇式的视频大海捞针”(Needle in a Montage,简称NeMo)。如上图,NeMo任务模拟了一个现实世界的场景:在一个由许多松散相关的短视频片段剪辑组成的长视频(montage)中,模型需要识别并精准定位出一个或多个目标片段(target needle)的时间区间。
因此,NeMo任务能够有效地评测VideoLLMs在长视频理解中重要的理解和推理能力,包括长上下文召回(long-context recall)和时间定位(temporal grounding)。
长上下文召回:模型能否在视频(比如小时级别的视频)中高效记忆并检索出关键信息?
时间定位:模型能否精准定位出多个目标视频片段的时间区间(即起始时间)?
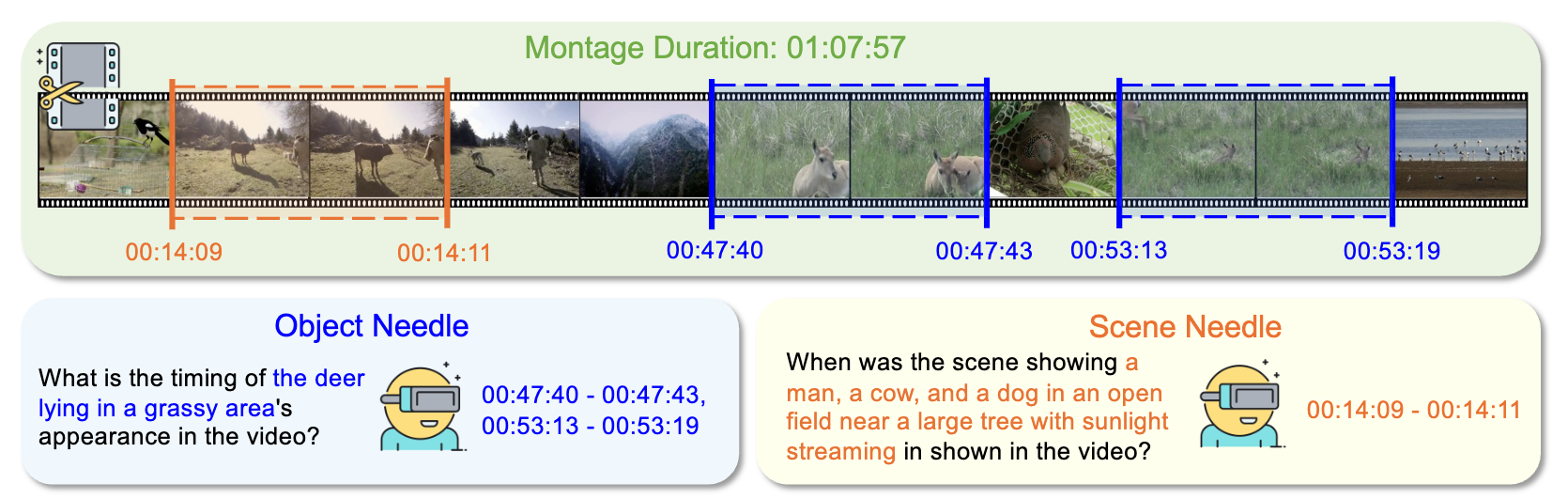
研究团队从多个维度对NeMo任务进行设计,具体来说,任务设置包括了不同的needle类型(scene needle和object needle)、不同的needle数量、不同的拼接视频的长度、生成的问答数据的格式类型等。这些丰富的任务设置使得NeMo任务涵盖了多样的、具备不同难度级别的问答对(QA),从而为VideoLLMs提供了一个更加全面的评测。
2. 自动化的视频语言数据生成方法
为了尽可能降低对人工标注的依赖,研究团队提出了一个自动化的数据生成方法。考虑到直接基于小时级别的原始视频自动化地构建评测数据十分困难,研究团队首先提出了一个全面且紧凑的视频特征(comprehensive yet compact video representation),然后基于提取的视频特征设计了一个可扩展的、自动化的数据生成方法(scalable automated data generation pipeline)。
2.1 新的视频表征
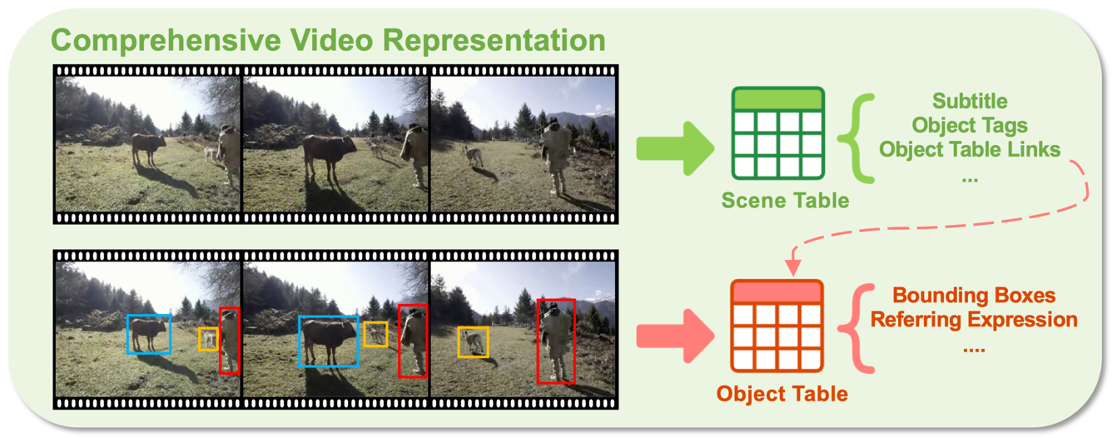
考虑到视频中的时间和空间冗余,研究团队提出了一个全面且紧凑的视频表征(如上图),为后续的自动化数据生成提供丰富的语义信息。为了有效处理一个长视频(比如小时级别的视频),我们首先将其切分为多个短的视频片段,然后从每个视频片段中提取出相应的视频特征(如物体和场景不同的层次化结构特征)。
2.2 自动化的数据生成过程
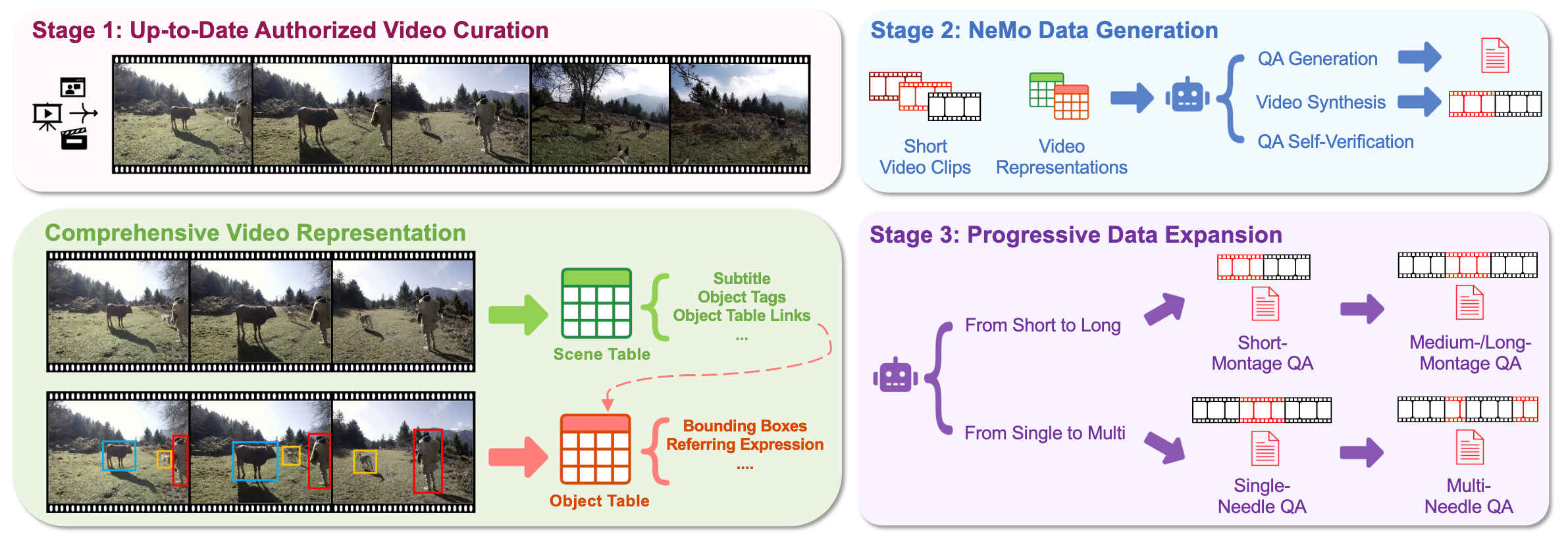
为了确保自动化生成数据的效率和质量,研究团队设计了一个可扩展的、自动化的数据生成方法(如上图),它分为如下三个步骤:
第一阶段:获取最新的授权视频。
获取来自于Phoenix TV凤凰卫视的最新的、多样化的高质量授权视频,并且确保他们没有出现在广泛使用的视频训练集中,从而防止大模型破除的数据污染问题。
然后,对这些视频提取相应的视频特征。
第二阶段:生成NeMo任务的评测数据。
基于提取的视频特征和visual prompting方法,利用多模态大模型(比如GPT-4o)为NeMo任务生成不同类型的needle grounding QA对。
从同一个视频源的、松散相关的视频片段(包括needle和negative distractors)来合成一个长视频(即montage)。
利用同一个多模态大模型(比如GPT-4o)通过self-verification策略来缓解标注模型带来的不准确性和幻觉等问题。
第三阶段:渐进式的数据扩展。
通过数据扩展生成更多种类的评测数据,包括更长的montage和更多的target needle数量。
研究团队对提出的数据生成管道进行了进一步分析,包括时间效率(time efficiency)和数据质量(data quality)两个方面。实验结果表明,与传统的纯人工标注视频语言评测数据相比,研究团队提出的自动化数据生成管道在保证数据质量(接近人工标注水平)的前提下,能够大幅降低测试平台准备评测数据的成本(节省约78%的时间成本)。这使得以高效、低成本的方式从零开始构建一个可扩展的视频语言评测基准成为可能,促进了多模态领域的研究与应用。
3. 新的视频语言评测基准:NeMoBench
3.1 Benchmark Statistics
基于上述的自动化数据生成管道,研究团队构建了一个以NeMo任务为中心的视频语言评测基准——NeMoBench,它由两个关键部分组成:
NeMoBench-Full:完整数据集,包含31,378个自动生成的QA对。
NeMoBench-Clean:核心子集,包含2,053个经过人工验证的高质量QA对,用于精确的模型评估。
具体来说,NeMoBench具有以下特点:
自动化生成的数据;
授权的评测视频源;
丰富的任务设置,如覆盖不同视频时长(从秒级到小时级)和包括不同数量的target needle;
无需LLM辅助的自动化评估,包括三个评测指标:Recall@1x, tIoU=0.7、Recall@1x, tIoU=0.5和Average mAP。
3.2 实验结果与发现
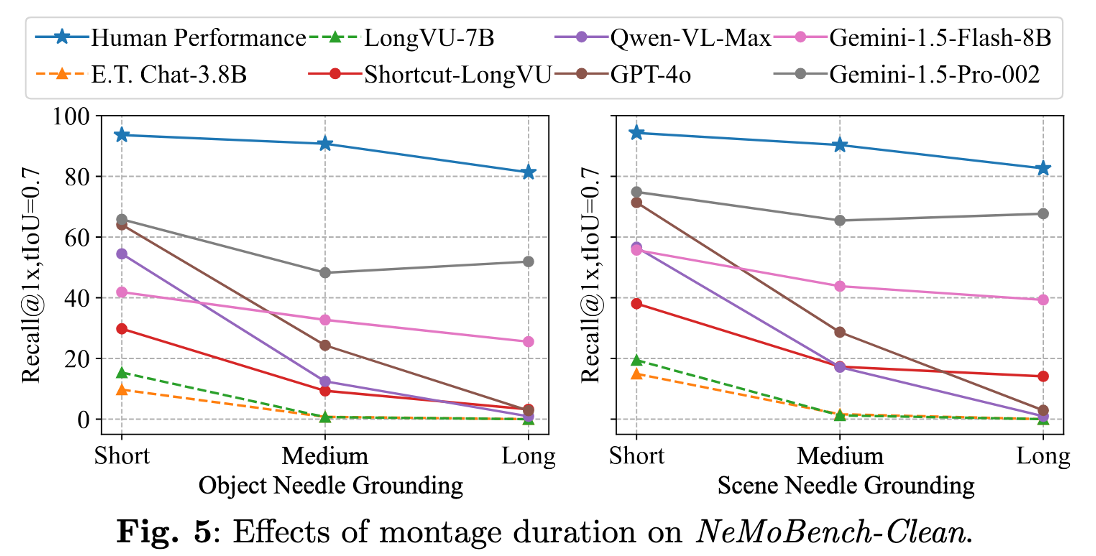
利用NeMoBench,研究团队对20个最先进的VideoLLMs进行了广泛的评测实验(具体实验结果请阅读paper的实验部分[1]),得到了以下的结论:
开源模型在NeMo任务上表现不佳:
比如开源模型(Qwen2.5-VL-72B)在short montages和medium montages的object needle grounding 上,仅分别取得了 28.04%和8.86% Recall@1x, tIoU=0.7的表现。
并且,随着montage时长的增加,开源模型性能都出现了急剧下降。
闭源模型性能显著优于开源模型:
在不同的montage时长中,闭源模型均大幅领先于所有开源模型。
比如最强的闭源模型( Gemini-1.5-Pro-002 )在short montages和medium montages的object needle grounding 上,仅分别取得了 65.83%和48.25% Recall@1x, tIoU=0.7的表现。
闭源模型与人类专家性能仍有巨大差距:
即使是最强的闭源模型( Gemini-1.5-Pro-002 ),人类专家性能在short / medium / long montages的object needle grounding 上,仍有+27.79% / +42.50% / +29.42% Recall@1x, tIoU=0.7的性能提升。
说明了VideoLLMs在long-context recall和temporal grounding能力仍有待进一步提升。
我们的自动化数据生成管道能够可靠、自动化地生成高质量的评测数据:
NeMoBench-Full 和 NeMoBench-Clean 的模型的相对排名基本一致:
未来,NeMoBench将持续评测不断出现的前沿模型,并持续维护一个视频语言大模型评测榜单[2],帮助多模态研究社区清晰了解当前最先进模型的视频语言理解能力。欢迎来自学术界和工业界的研究人员使用NeMoBench,共同推动视频多模态领域的前沿研究。
参考:[1] 论文链接:https://arxiv.org/abs/2509.24563[2] 项目主页:https://lavi-lab.github.io/NeMoBench
