
新智元报道
编辑:KingHZ
【新智元导读】UC Berkeley、UW、AI2 等机构联合团队最新工作提出:在恰当的训练范式下,强化学习(RL)不仅能「打磨」已有能力,更能逼出「全新算法」级的推理模式。他们构建了一个专门验证这一命题的测试框架 DELTA,并观察到从「零奖励」到接近100%突破式跃迁的「RL grokking」现象。
在AI研究圈,一个核心争论是:强化学习(RL)是否能够赋予模型超越其基础模型(base model)的推理能力。
怀疑派观点:早在四月份,清华的黄高团队[arXiv:2504.13837]指出,尽管经过 RLVR 训练的模型在较小的采样值 (k)(例如 (k=1))时能优于其基础模型,但当采样数较大时,基础模型往往能取得相同或更好的 pass@k 表现。
他们通过覆盖率(coverage)和困惑度(perplexity)分析推断,模型的推理能力最终受限于基础模型的支持范围。
类似地,斯坦福崔艺珍团队 [arXiv:2507.14843] 从理论上论证了 RLVR 无法突破基础模型的表征极限。
这种怀疑的直觉在于:
大多数面向推理的强化学习(如 GRPO、PPO 等变体)通过比较同一提示词(prompt)下多个采样的奖励来更新模型。
如果这些采样中没有一个成功解决任务(即 pass@K = 0),那么所有样本的奖励都是一样差的,此时梯度将会消失。
所以关键的问题在于,当基础模型(base model)在某类任务上完全无法解答(pass@K=0)时:
RL是否还能突破零梯度瓶颈,真正学到新策略?
来自加州大学伯克利分校(UC Berkeley)与AI2、华盛顿大学等机构的研究团队,近日给出了一个令人振奋的答案:
RL确实能让模型发现全新的推理模式——但前提是,需要不一样的训练方式。
他们的最新工作《RL Grokking Receipe: How Does RL Unlock and Transfer New Algorithms in LLMs?》提出了一个崭新的测试框架 DELTA,专门用来验证该观点。
这项研究为「RL是否能突破模型边界」这一争论,带来了新的实验依据。

论文:https://www.arxiv.org/abs/2509.21016
博客:https://rdi.berkeley.edu/blog/rl-grokking-recipe
相关资源清单(持续更新):https://github.com/rdi-berkeley/awesome-RLVR-boundary
从「打磨」到「顿悟」
RL真学到新算法了?
在主流观点中,RL似乎被困在「隐形的绳子」上 ——
模型的pass@1虽然提高,但在大规模采样下(如pass@128)性能并未扩展。
这意味着它可能只是重新分配已有策略的概率,而不是创造新的策略。
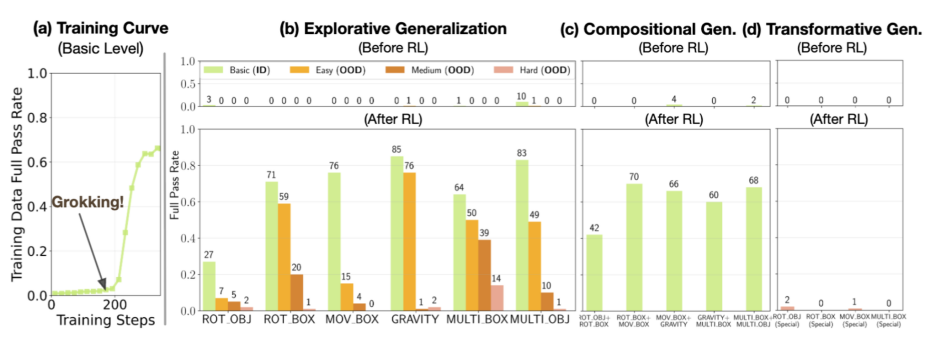
然而,伯克利团队在 DELTA 测试中发现了「顿悟式跃迁」: 在多个基础模型完全失败的任务族中,RL训练经历了一个长时间的「零奖励平台期」,随后突然出现了准确率接近100%的跃迁 (phase transition) 。
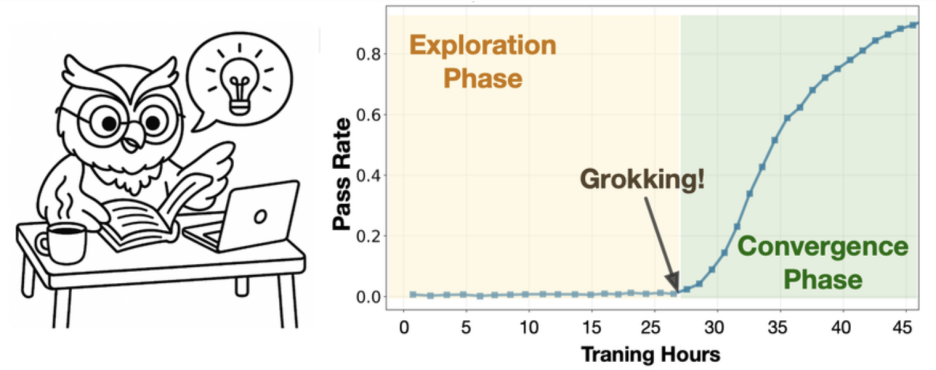
研究者将此描述为 「RL grokking」:那不是微调的延展,而是「想通了」的瞬间。
一个「分布外任务学习性」试炼场
很多工作声称「新任务」,但其实仍落在模型的知识范围内。
伯克利团队这次刻意设计的任务,却真正做到了脱离模型经验的外部分布 (Out-of-Distribution):
1. 全新的语言——互联网上从未出现过。
研究团队以经典2010 flash游戏Manufactoria为灵感,构建了一个全新的合成编程世界。
该游戏的解法仅以图片的形式存在,为了适配语言模型,作者引入了一种全新的程序描述语言,仅由两种原始指令组成:
Puller:从左侧读取并移动符号;
Painter:在右侧写入或标记符号,以此来完成输入输出匹配任务。
2. 全新的任务家族——不是重混关卡,而是全新打造。
研究者不是简单复刻原始的谜题,而是合成了一批全新问题族。这些问题族的难度有简单有困难,最难的问题使得GPT-5都只有0的正确率。
3. 全新的推理方式——与常规代码推理完全不同。
传统代码学习依赖控制流(if/for/while)和数据结构(stack/list/map)。
而在这个极简世界里,模型必须发明一种有限状态机式的推理方式:通过在带子两端不断搬运和标记颜色,完成路由、缓存、比较等操作。
换句话说,模型得在没有变量的环境中「自造算法」。这是一种人类都要重新思考的推理方式。
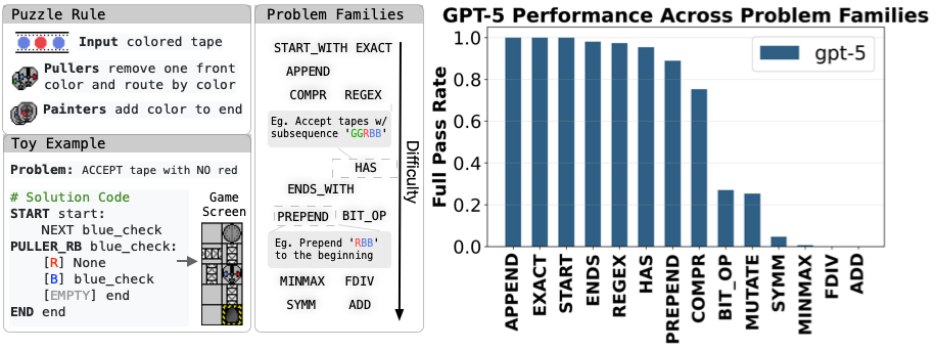
如果一个RL模型在这里能学会通用策略,那几乎可以排除掉「记忆已有代码模式」的可能,它确实在学习新的算法结构。
破解零梯度诅咒的关键
两阶段奖励调度
伯克利团队的突破在于,他们重新设计了奖励函数的结构。
阶段一:密集奖励(dense reward)
在每个测试用例上给部分分数,而非非黑即白的0/1。即使程序只通过了一半测试,也能获得部分奖励。这让模型从「全零」中获得一丝梯度信号,开始摸索。
问题是: 密集奖励虽然让模型「活了」,但它学会的往往是「投机解」——通过简单模式骗过部分测试。
结果是:平均分高了,完全通过率仍接近0。
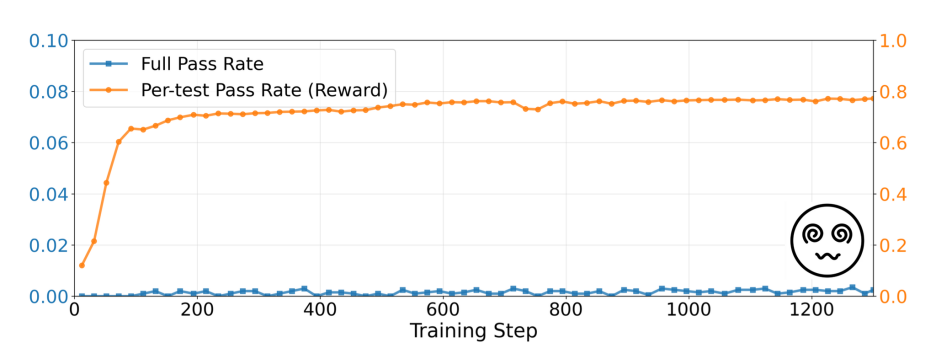
阶段二:切换回二值奖励(binary reward)
研究者发现,关键在于时机的切换。当模型通过密集奖励阶段获得「半正确」策略后,再切换到「全对才算赢」的二值奖励,模型突然迎来那一刻——Grokking Phase Transition:从模糊到精确的飞跃。
在约450步后,模型突然学会了任务的核心算法,从此训练进入「强化收敛」阶段,成功率稳定在近100%。那一瞬间,你几乎能看到模型‘领悟’了规律。
在DELTA的多种任务族中,研究者观测到高度一致的学习曲线:前几百步内,奖励几乎为零;接着出现一次陡峭的提升;模型学会了任务核心逻辑,性能稳定在近乎100%。
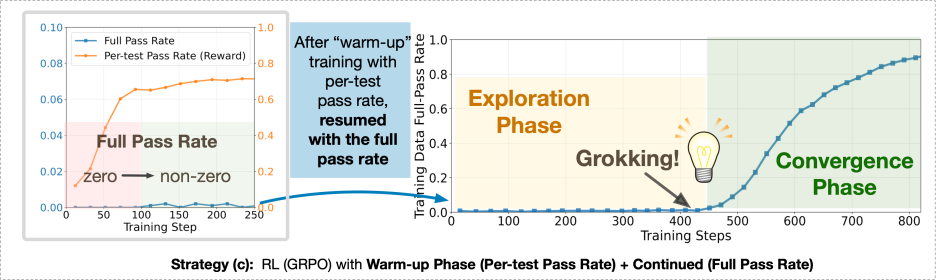
这条曲线如同人类的学习历程——先是漫长摸索,然后灵光乍现。

顿悟后的技能能否迁移?
团队进一步设计了 BouncingSim 测试场景,让模型预测小球的弹跳轨迹。
这是一个涉及物理规律与组合推理的任务,是一个极具挑战性的编程任务。
结果显示:
模型能在训练后期出现相似的「顿悟曲线」;
对于可组合(Compositional)任务,它能复用学到的子技能;
但面对特殊的动力学规律,模型仍会失效。
这表明,RL 学习到的技能具备有限的迁移能力:它能重组技能,但尚未形成「概念跃迁」的能力。
深层启示1:RL的两种模式
该研究总结出RLVR在LLM中的两种模式:
压缩模式(Sharpening):重新分配概率,减少输出方差,提升单次采样的性能。
发现模式(Discovery):从完全不会(pass@K=0)到稳定解题,实现结构性突破。
而进入发现模式的关键在于:奖励函数设计;探索持续时间;数据混合策略;以及任务的复杂度边界等等。
深层启示2:提升「硬核任务」的而非平均分
研究团队指出,目前RLVR的评测往往在「混合任务池」上取平均,这掩盖了最关键的「硬核任务」突破。
在那些基础模型完全不会(pass@K=0)的任务上,才最有机会观察到RL的「创造性突破」。他们建议未来评估指标应显式报告该子集的表现,因为那才是衡量「模型是否能发现新策略」的真实信号。
为此,伯克利团队搜集并维护了一个在此方向上的代表性工作:
按「立场—方法—评测—数据/基准—讨论」分门别类的列表,便于研究者直接定位到 pass@k=0 等硬核子集上的最新证据与方法路径。
项目地址: https://github.com/sunblaze-ucb/awesome-RLVR-boundary
深层启示3:从编程迈向数学与科学:RL的新边疆
为何该工作选择编程作为突破口?
因为代码任务天然具备:可验证的单元测试;细粒度、可组合的反馈信号。
这些特性让RL能够精确调节奖励,形成探索路径。
研究者认为,这一思路完全可扩展到数学与科学推理领域:
通过自动评分(rubric scoring)、逐步检验(step checker)或物理仿真器(simulator feedback)
构建细粒度的奖励系统,从而让RL引导模型穿越「无梯度」地带
结语
模型「真正思考」那一刻
这项研究的意义不仅在于性能提升,而在于它展示了LLM真正的学习潜能:
强化学习不只是打磨,而是让模型学会「如何思考」。
在AGI前夜的诸多技术路径中,RLVR 可能是那条让模型从模仿走向洞察的路。
当模型在接近零反馈的黑暗中摸索,直到某一刻突然顿悟——或许这就是AI的「悟道」瞬间。
