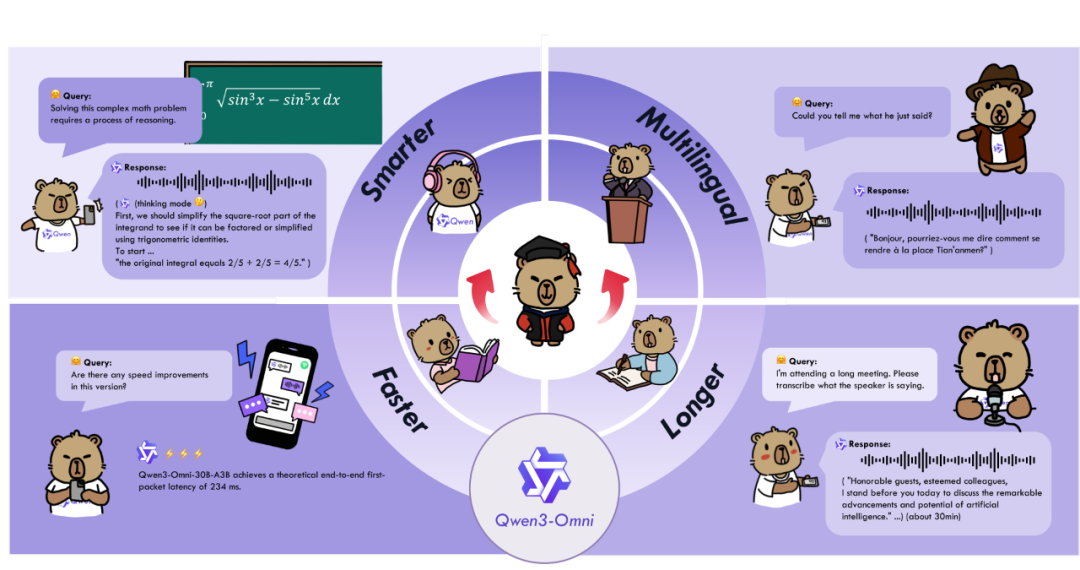
阿里杀疯了,Qwen团队刚刚接连发布了两款重要模型:Qwen3-Omni,业界首个原生端到端全模态AI模型;以及Qwen-Image-Edit-2509,对标谷歌nano banana 图像编辑工具,根据预告,明天还有“大的”要发布
Qwen3-Omni:真正的一体化AI
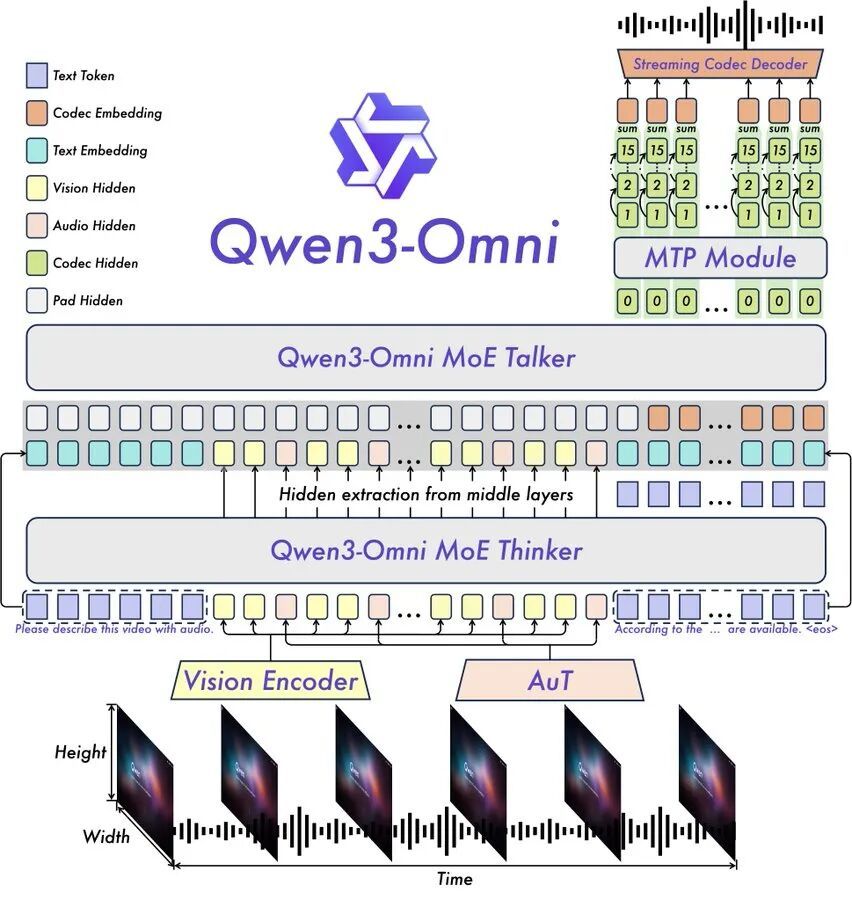
Qwen3-Omni的问世,旨在解决长期以来多模态模型需要在不同能力之间进行权衡取舍的难题。它是一款真正意义上的全能选手,在同一个模型中无缝统一了文本、图像、音频和视频的处理能力
web端体验:
https://chat.qwen.ai/?models=qwen3-omni-flash
抱抱脸上这个体验demo,可以直接去这里体验
https://huggingface.co/spaces/Qwen/Qwen3-Omni-Demo
核心亮点:
性能卓越:在36项音频及音视频基准测试中,Qwen3-Omni在其中22项上达到了业界顶尖水平(SOTA)
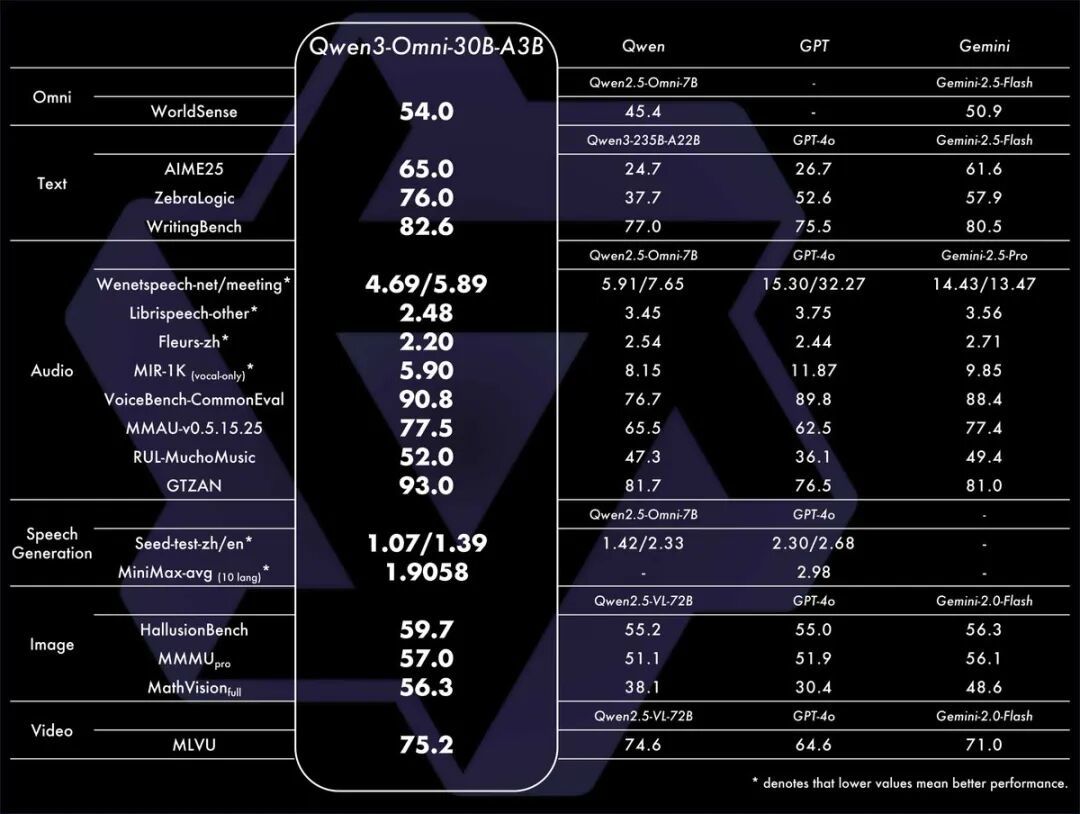
全球化的语言能力:模型能力覆盖广泛,支持119种语言的文本处理、19种语言的语音输入以及10种语言的语音输出
极致高效:延迟仅为211毫秒,并能轻松理解长达30分钟的音频内容
高度可控:支持通过系统提示词(System Prompts)进行完全自定义,满足个性化需求
功能强大:内置工具调用(Tool Calling)功能,可与其他应用和服务轻松集成。
开源字幕模型:同时开源了一个低幻觉的Captioner(字幕生成)模型,为音视频内容处理提供了可靠工具
开源
为了推动技术发展和应用创新,Qwen团队已开源了
Qwen3-Omni-30B-A3B-Instruct、
Qwen3-Omni-30B-A3B-Thinking
Qwen3-Omni-30B-A3B-Captioner
等多个版本,旨在赋能全球开发者,探索从指令遵循到创意任务等多样化的应用场景
https://huggingface.co/Qwen/Qwen3-Omni-30B-A3B-Instruct
Qwen-Image-Edit-2509
这是Qwen-Image升级版本,和字节前几天发布的即梦4.0图像模型一样主要是一致性上巨大提升
多图编辑,无缝融合,现在,可以将“人物+产品”或“人物+场景”等多张图片拖入编辑,保持一致性同时进行推理

单图编辑,高度一致:
人脸保真:无论变换姿势、滤镜还是风格,人物的面部特征始终保持一致
产品保真:在广告、海报等应用中,产品能维持其核心特征,确保品牌识别度
文字编辑:支持对图像中的文字进行全面修改,包括内容、字体、颜色,甚至材质纹理
内置ControlNet,精准控制
深度、边缘、关键点……Qwen-Image-Edit-2509内置了强大的ControlNet功能,让用户可以即插即用,实现对图像生成的精准控制

