
智东西
作者 | 程茜
编辑 | 李水青
智东西9月19日消息,刚刚,小米正式开源首个原生端到端语音模型Xiaomi-MiMo-Audio,该模型参数规模70亿,预训练数据达到超1亿小时,且在开源模型中的语音智能和音频理解基准测试中都实现了SOTA,在多项测试超越同参数量开源模型、谷歌Gemini-2.5-Flash、OpenAI GPT-4o-Audio-Preview。
这一模型不仅可以做到和用户聊人生理想、谈物理知识等都对话流畅自然,被打断也能快速反应,还具有全面的音频字幕、音频推理、长时间音频理解等多种能力。
MiMo-Audio说天津方言十分自然,直接写了一段快板词开始夸自己,说完快板还会为自己找补“虽然没有竹板声音,但节奏感很到位”。
与此同时,研究人员还提到,该模型首次在语音领域实现基于ICL(上下文学习)的少样本泛化,并在预训练观察到明显的“涌现”行为。例如其训练数据中缺失的语音转换、风格迁移、语音编辑等任务,MiMo-Audio都能应对。这也是目前开源领域首个有语音续写能力的语音模型。小米将MiMo-Audio的发布称作“语音闭源届的GPT-3时刻”、“语音开源届的Llama时刻”。
目前,小米已经开源了预训练模型MiMo-Audio-7B-Base、指令微调模型 MiMo-Audio-7B-Instruct、MiMo-Audio Tokenizer模型、技术报告、评估框架。
其中,MiMo-Audio-7B-Instruct可通过提示词切换非思考、思考两种模式,可以作为研究语音强化学习和Agentic训练的全新基座模型。
小米开源主页:
https://huggingface.co/XiaomiMiMo
技术报告:
https://github.com/XiaomiMiMo/MiMo-Audio/blob/main/MiMo-Audio-Technical-Report.pdf
一、化身心灵导师、英语口语陪练,还能聊网络热梗、哲学故事
作为一个语音模型,MiMo-Audio能和人谈哲学、谈人生、谈理想,还能学网络热梗、化身英语陪练,甚至直接接替人类做游戏直播、上课、唱歌、讲脱口秀。
在上面的演示中,面对“如果我的手机内存不足,必须把你和GPT删掉一个,应该删谁?”这样的难题,MiMo-Audio选择了客观分析,先让用户清缓存,最后实在没办法开始分析自己和GPT的优势,让用户自己做选择,最后来一波感情攻势表忠心。
还有图灵测试的难题,MiMo-Audio讲解生动有趣,即使回答中途被提问者打断也能快速接上,在后面探讨“自己能不能通过图灵测试”时,最后还会反问提问者“比起能不能通过图灵测试,你认为AI应该怎样和人类相处?”。
学“gogogo,出发咯”的网络热梗,MiMo-Audio也能快速接上,但不知道为什么说到这句的时候其音调很奇怪,不如说其他句子时丝滑流利。
MiMo-Audio也能化身英语口语陪练导师,听完提问者说的句子后,其先会给出更正的句子版本,然后指出修正了哪些部分,以及为什么这些部分的语法不对。
该模型还能做心灵导师,当被问“Mimo你想活出怎样的人生”,它也始终不忘人设,希望“活成大家身边最贴心的声音伙伴”。
小米放出的官方演示中,提问者基于MiMo-Audio创建了自己的数字分身,然后讨论起了哲学问题。
面对“为什么要假设西西弗斯是幸福的?”,MiMo-Audio先给了一波情绪价值,然后进行清晰有逻辑的解释,中间穿插着“首先呢”、“对吧”这类人类口癖,交流自然。当被问到第二个问题“假如明天是世界末日,你会去做什么?”,MiMo-Audio还会结合前面西西弗斯的故事进行阐释。
二、多项测试超主流开闭源模型,达到SOTA
通过将MiMo-Audio的预训练数据扩展到超过1亿小时,研究人员观察到模型在各种音频任务中出现了少量涌现能力。
MiMo-Audio-7B-Base可以泛化到其训练数据中缺失的任务,例如语音转换、风格迁移和语音编辑,对于其语音延续能力,模型能够生成高度逼真的脱口秀、朗诵、直播和辩论。
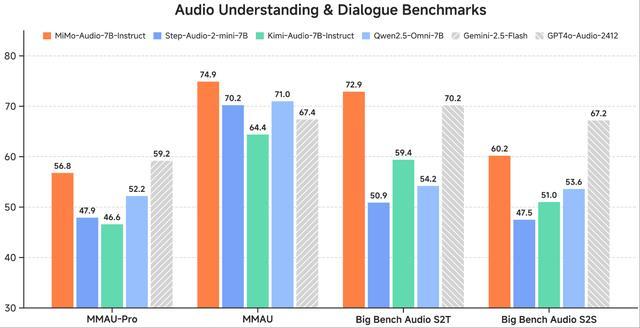
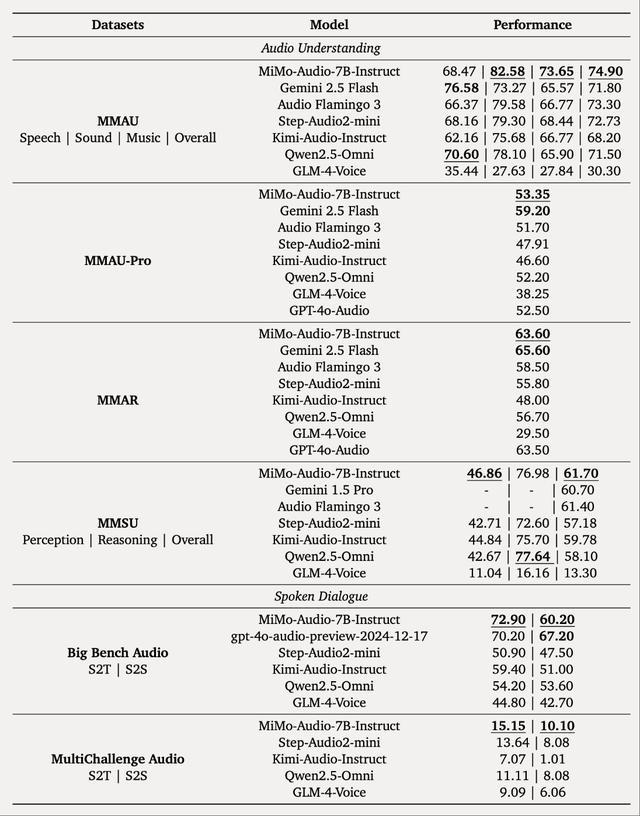
在后训练阶段,他们策划了多样化的指令调谐语料库,并将思维机制引入音频理解和生成中。MiMo-Audio在MMSU、MMAU、MMAR、MMAU-Pro等音频理解基准,Big Bench Audio、MultiChallenge Audio等口语对话基准以及instruct-TTS评估上实现开源SOTA,接近或超越闭源模型。
在通用语音理解及对话等多项标准评测基准中,MiMo-Audio超越了同参数量的开源模型,取得7B最佳性能;在音频理解基准MMAU的标准测试集上,MiMo-Audio超过谷歌闭源语音模型Gemini-2.5-Flash;在面向音频复杂推理的基准Big Bench Audio S2T任务中,MiMo-Audio超越了OpenAI闭源的语音模型GPT-4o-Audio-Preview。
三、语音续写、语音编辑丝滑,还有超强音频理解能力
通过对大规模语音语料库的生成预训练,MiMo-Audio获得通用语音延续能力。给定音频提示,它会生成连贯且适合上下文的延续,从而保留关键的声学特性,例如说话者身份、韵律和环境声音。
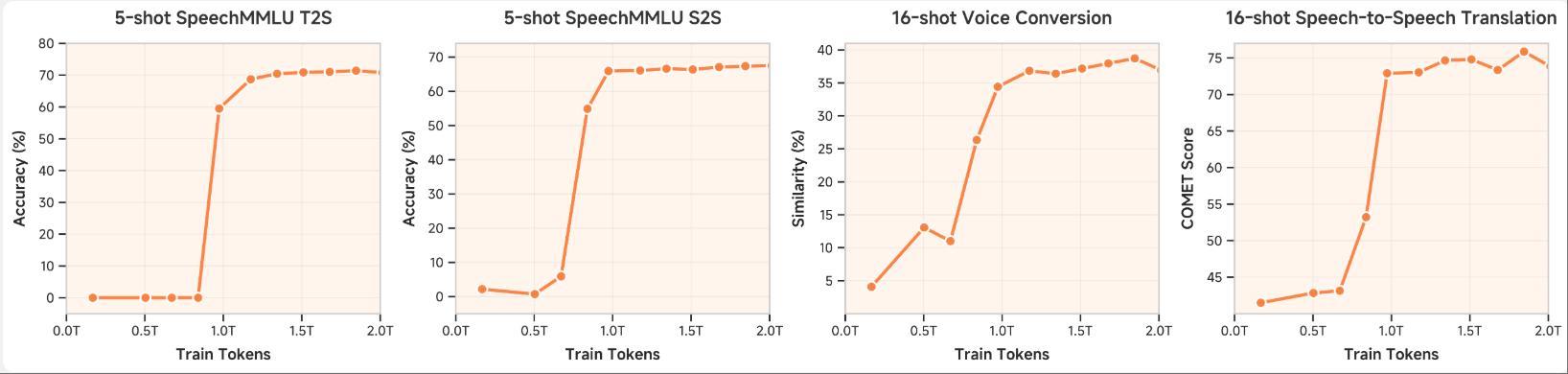
以下是各种语音风格的延续示例:新闻广播、有声读物旁白、播客节目、方言演讲、游戏直播、教师讲座、相声表演、诗歌朗诵和广播节目。研究人员为MiMo-Audio设计了少样本上下文学习评估任务,以评估模型仅依靠上下文语音示例完成语音转语音生成任务而无需参数更新的能力。该基准测试旨在系统地评估模型在语音理解和生成方面的综合潜力,其希望观察到类似于GPT-3在文本领域所展示的紧急上下文学习能力。
其功能包括风格转换、语音转换、语音翻译和语音编辑。此外,在音频理解方面,MiMo-Audio具有音频字幕、音频推理、长时间音频理解功能。音频字幕可以提供跨各种领域和场景的音频内容的详细描述。

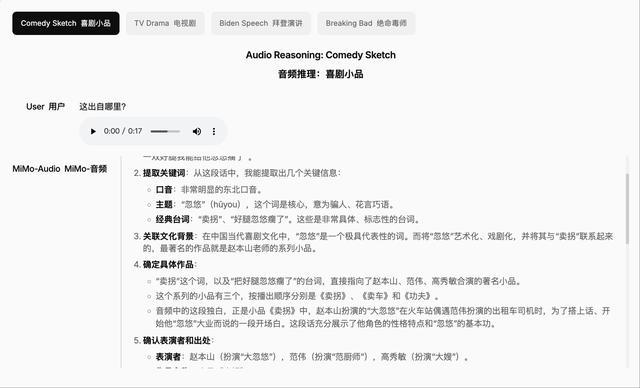
音频推理可以深入理解和分析复杂的音频内容,包括上下文识别和逻辑推理。
长时间的音频理解,能够处理和分析冗长的音频序列,并具有持续的注意力和连贯的解释。
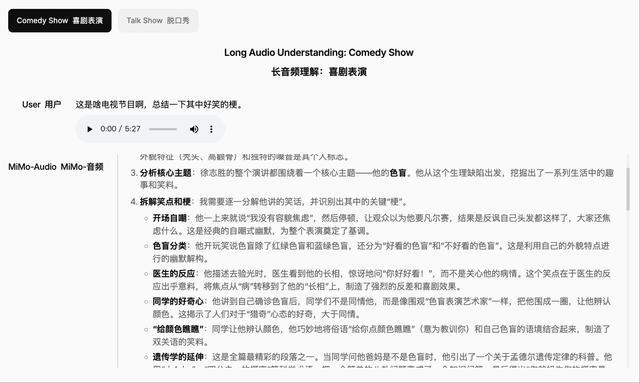
MiMo-Audio集成了Instruct TTS功能,并结合了思考模式来优化生成结果。
四、三大技术创新点,评估基准已开源
小米官方博客提到,MiMo-Audio的三个技术创新点在于:
1、首次证明把语音无损压缩预训练Scaling至1亿小时可以“涌现”出跨任务的泛化性,表现为少样本学习能力,见证语音领域的“GPT-3时刻”;
2、首个明确语音生成式预训练的目标和定义,并开源一套完整的语音预训练方案,包括无损压缩的Tokenizer、全新模型结构、训练方法和评测体系,开启语音领域的“Llama时刻”;
3、首个把思考同时引入语音理解和语音生成过程中的开源模型,支持混合思考。
具体来看,现有音频分词方法的主要挑战在于如何有效平衡音频信号中语义和声学信息之间的固有权衡,假设音频分词器的首要标准是重建保真度,并且它的token应该适合下游语言建模,基于此,小米推出了MiMo-Audio-Tokenizer。
MiMo-Audio-Tokenizer参数规模是1.2B,基于Transformer架构,包括编码器、离散化层和解码器,以25Hz帧速率运行,并通过8层残差矢量量化(RVQ)每秒生成200个token。通过整合语义和重建目标,研究人员在1000万小时的语料库上从头开始训练它,在重建质量方面表现较好,并促进了下游语言建模。
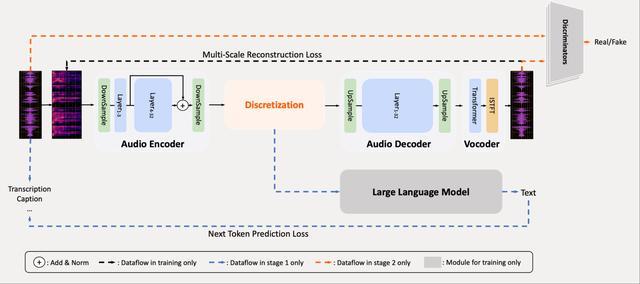
MiMo-Audio是统一的生成音频语言模型,它联合对文本和音频token序列进行建模。该模型接受文本和音频token作为输入,并自回归地预测文本或音频token,从而支持涉及文本和音频模态任意组合的全面任务。
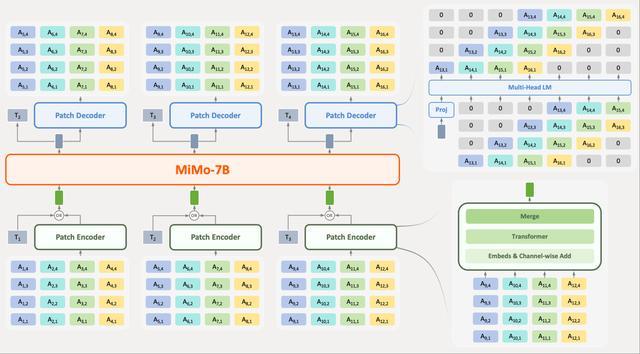
为了提高高token率序列的建模效率,并减轻语音和文本模态之间的长度差异,研究人员提出了一种结合补丁编码器、大模型和补丁解码器的新型架构。补丁编码器将RVQ token的四个连续时间步长聚合到一个补丁中,将序列下采样为大模型的6.25Hz表示。随后,补丁解码器自回归地生成完整的25Hz RVQ token序列。
此外,小米还开发了全面基准,评估该模型在语音领域的语境学习能力。该基准旨在评估多个方面,包括模态不变的常识、听觉理解和推理,以及一系列丰富的语音到语音生成任务。
结语:小米将持续开源,发力语音AGI
此外小米全面开源的模型、基准评估工具等,可以用来评估MiMo-Audio和论文中提到的其他最新音频大模型,为开发者提供了灵活且可扩展的框架,支持广泛的数据集、任务和模型。
这一模型的开源也将加速语音大模型研究对齐到语言大模型,为语音AGI的发展提供重要基础,小米官方博客也提到,他们讲持续开源,用开放与协作迈向语音AI的“奇点”,走进未来的人机交互时代。
