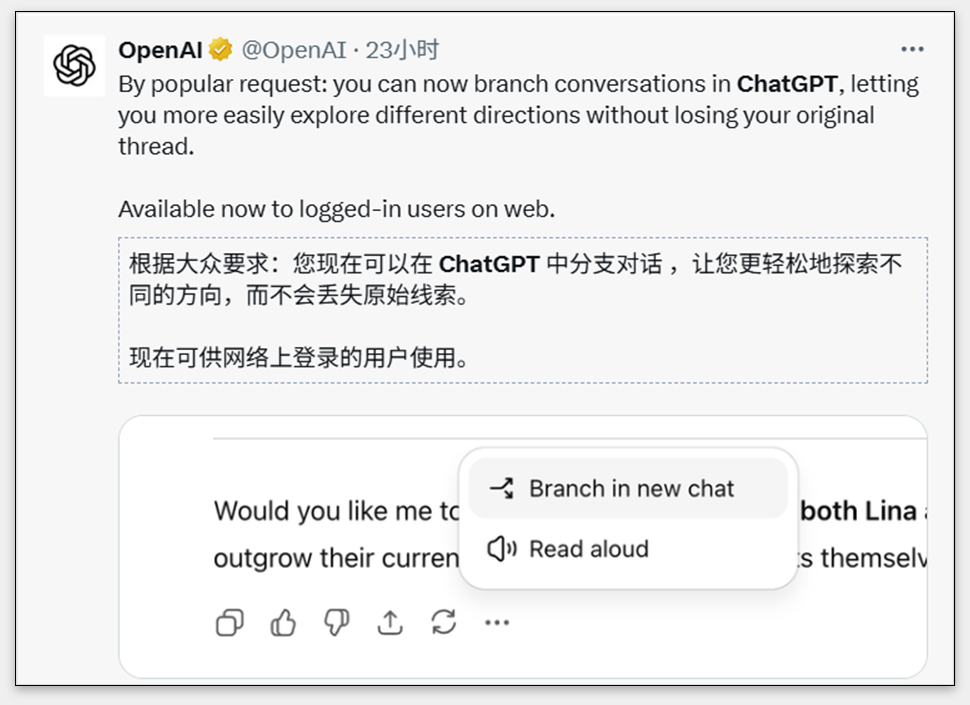
昨晚OpenAI给 ChatGPT 上了个新功能:分支对话。
网页端把鼠标放到某条回复上,点右下角的「⋯更多操作」,就能选「在新聊天中分支」。
简单讲,不用再傻乎乎地新开个对话,也不用拉一条线到几百条消息那么长,最后把上下文撑爆。现在可以在某个节点直接「开岔路」。
如果把几个月前上线的记忆功能放在一起看,会发现这是一个很有意思的组合:记忆解决「跨对话的连续性」;分支解决「单次对话的多线探索」。
过去跟 AI 聊天,很死板:新开一个对话是「起点」,点掉或者清空就是「终点」。对话像一条直线,往前走只能不断累积,越长越混乱。
分支对话出来之后,这个边界突然变模糊了。
我不用想「要不要新开个对话」,因为随时可以在某个节点上岔开一条新线。
还记得豆包吗?
有个临时问题,问一下,问完就走,很方便;但问题是,过了半个小时,你又想接着刚才的问题往下聊,它就完全不记得上文了,只能当成一次新的问答。
这就是差别。
豆包逻辑是一次性:轻便,却没有连续性;而ChatGPT分支 + 记忆的逻辑是「接力」,随时能在某个节点延伸,把思路保留下来继续聊。
所以,说白了,边界没了,对话变得像一棵树,随时能在一个点上岔开一条新枝,想回去、想切换都行,整段聊天更像「线程」。
这意味着什么?智远认为有三点:
一,对话的开始和结束意义变小了。以前新开对话要想清楚「我到底要聊啥」,现在完全不用纠结,顺着聊就行,想在哪个点岔开就岔开。
二,过去聊着聊着很容易迷路,分支出来之后,我能把不同思路分开保存,像写文档时留多个版本。
要说第三点,我认为,上下文也更灵活了。不用一股脑往窗口里塞一大堆信息,聊着聊着,我直接跳出一个节点,和它讨论一下,这多丝滑。
昨天凌晨,Qwen3 发布了新模型 Qwen3-Max-Preview,我当时想发个小红书,直接让 ChatGPT 给我写文案。
结果它给的内容偏宏观:什么「更大模型」「推理速度更快」之类的,太笼统,不够具体。那怎么办?
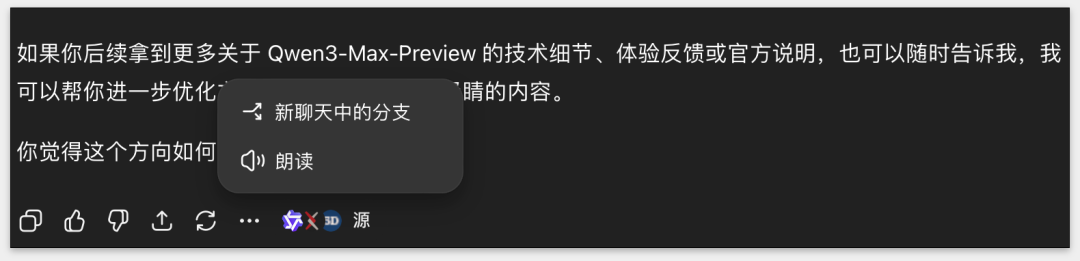
我追问细节,它反而说「这个模型还没正式发布,好像还在灰度,抓不到更精准的信息」。场面有点尴尬,它只能建议我写「首发体验」或者「首次曝光」的角度。
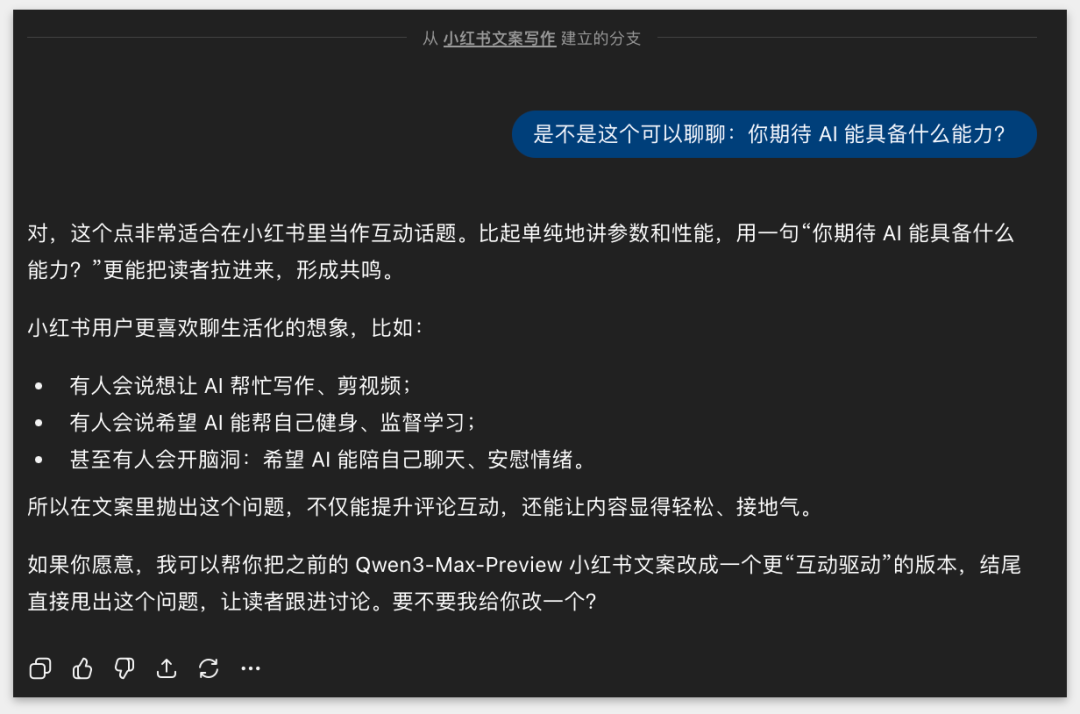
可今天早上上线了「分支对话」,我就顺手点了「更多」,从那条回复开了个分支,和它单独聊「我最期待 Qwen3 能有什么样的能力」。
那半天我们就在新分支里来回讨论,把思路拉开;这个话题聊完,我又切回原来的主线,让它继续写小红书文案。
然后,它居然把上下文接得很自然,记忆一点没断,整个过程特别丝滑。
所以,智远认为,对话从直线变成树状,对AI助理来说,是特别大的变化。

光能分岔还不够,这些分岔下来的对话,最后 ChatGPT 想把它变成什么?
过去大家用知识管理工具,不外乎 Notion、飞书文档,硬核一点的还有 Obsidian,好处显而易见,能结构化、分层级、做大纲,特别适合喜欢折腾的人。
写完文章还得归档,开完会还要手动写总结,想让它形成体系,就得不停维护;很多人一开始雄心勃勃,最后是坚持不下来,库里一堆半拉子工程。
记忆和分支的逻辑完全不同。
核心是「顺手」,你反正要跟 AI 聊天,要写要想,它就顺手把痕迹留了下来。下次要追溯,直接点开分支就行。
笔记常常是碎片化的,几句话、几个点,很容易脱离语境;对话不是,对话自带上下文:你为什么问,它给了什么答案,你们怎么推演,整个过程都在。
这种语境,有时候比结论本身还更有价值;这让我想到飞书、钉钉里的知识问答逻辑。
它们把「提问」当成起点:我问一个问题,系统给一堆答案。可答案不是终点,如果其中有能用的,我一键标记,就能同步到文档,再编辑打磨,最后存进知识库。
这样才算完成一个「问答—文档—知识库」的闭环。
Perplexity 的老板也说过一句话:「问题才是起点」。问题一旦明确,后面的线索就能拉出来;你再看国内一些新产品,比如 ima、知乎知识库,本质上也是都长在提问上。
所以我觉得,对话优势有三点:
一边用一边沉淀,不用额外操作,这是知识累积;检索更自然了,不用自己翻笔记,只要「问 AI」就能找出来;更重要的是,它保留了上下文,整个脉络都在。
但对话也不是万能的。
我今天用了一上午,还顺手改了几篇研究报告,发现它有时会「记不全」或者「啰嗦混乱」;说明它的记忆能力还要继续提升。
说白了,现在还没办法完全把一个聊天、一个主题任务,直接托付给它去搭建成一套完整的知识体系。
可就算如此,我依然觉得,AI 和人的关系正在慢慢被重塑,它开始更像一个真正的「AI 助理」。
AI 助理,这个词这几年已经被叫烂了。绝大多数产品所谓的「助理」,是帮你干点机械活。类似于,写个日程、优化个文档,说白了就是代替「手和脚」。
可在思维和记忆层面,它们几乎没动过。一个对话聊完就结束,信息全断掉,你根本不会觉得它真是助理。
现在情况不一样了。记忆让它能保留上下文,分支让它能同时跑多条思路。你可以想象:
一个分支在负责推理和研究,另一个分支在帮你找数据和案例,再有一个分支,专门帮你打磨文案。这更一个像团队一样的 AI 助理。
举个例子:
前几天我用百度文库写东西,它的超能搭子 GenFlow逻辑跟我理解的「AI 助理」挺接近。
我先抛一个问题,它给我答案;基于答案,我可能要做个海报,再让它把关键信息抽出来,顺手验证一下数据准不准,最后还帮我推理逻辑。
整个过程像有好几个不同的 agent 在分工合作,而角色全都浓缩在同一个助理里。
所以我觉得,这条路通用 AI 迟早会走。
随着模型越来越大、越来越智能,这种协作会越来越丝滑;到那时,每个人可能都会愿意为一个 AI 助理付费,因为买到的是一个可以代替、可以协作的伙伴。它真的在和人共创。
既然人和AI共创了,就绕不开一个老生常谈的问题绕不开:上下文。
大家最关心「窗口够不够大」,32K、128K,甚至有人憧憬所谓的「无限上下文」,听上去很诱人,好像谁能记得更多,谁就更先进。
可窗口再大,它本质上还是「一次性记忆」,你想把几十页资料、好几轮推演全塞进去,最后模型答非所问太正常不过了。
而且,大窗口代价不小:推理更慢,成本更高。对大多数人来说,没必要为「无限上下文」去买单。
所以我觉得,真正的关键在于 AI 能不能帮我们管理信息;换句话说,与其让它背下整本书,不如让它知道书在哪个书架,随时能翻到对应章节。前者累又不可靠,后者才是更聪明的办法。
记忆和分支带来的,刚好是这种「书架式」体验。
你不用硬塞所有资料,随时能从历史对话里开个分支,或者调用记忆继续延展。
所以,智远认为「把上下文做大」是一条技术路径,但未必是未来答案。真正值得期待的,是 AI 有没有能力,把信息分类、留存、调用得更顺手。
你有没有想过,当记忆和分支进化到足够好时,我们还会在乎上下文窗口的大小吗?
我不知道答案。
但智远认为,未来我们讨论的重点,不是「窗口」这种技术指标,是一个更大的命题:「对话操作系统」。
什么是对话操作系统?我的理解是:你打开一个聊天窗口,也就等于开启了一个任务。
过去,一个任务往往要在好几个应用里来回切;现在,随着记忆和分支的进化,这些事情完全有可能在一个对话里搞定;你问它写文章,它顺便能调动表格;要做个海报,它能直接生成图片。
对话,本身像一个外壳,可以随时调用不同的工具或协议(比如 MCP),把整个流程串起来。
最早大家把搜索当入口,一切从 Google 开始;后来浏览器成了入口,网页承载了信息和应用;再后来手机操作系统,每一个 App 就是一个独立的世界。
入口的变化,意味着新的操作系统形态。
今天,ChatGPT 的演化,正把「对话」推向下一个入口,它逐渐承载任务驱动、知识检索、创作协作的各种形态;未来会不会在对话里,生长出一个基于对话的 WPS、一个 Office?我不知道。
但我知道的一点是:等到那一天,你不需要再切换那么多应用,一个对话就能解决所有事。
举个例子:
你有一份合同要微调,过去得来回切 Word、邮件、PDF 编辑器,步骤一大堆。可在「对话操作系统」里,把初始版本丢进 Chat,任务就开始了。
它告诉你哪不对、哪需要改,你一句句指令「帮我调这个」「再改那个」。最后一句「把最终版导出来吧」,它直接生成 PDF,你点开就能打印,下一秒就能发给客户。
所以,当我再谈「记忆」和「分支」,再谈一个雏形:未来操作系统,建立在对话之上;也许,「对话操作系统」才有想象空间。
可回头看国内的产品,情况不一样了。大家还在卷模型参数、推理速度,甚至价格补贴,但在「对话形态」上,几乎没有多少探索。
国内产品要怎么补课?至少,ChatGPT 已经给出了一个思路。
