小模型也开始卷起来了!
在麻省理工学院衍生公司Liquid AI发布了一款小到可以装在智能手表上的新AI视觉模型,以及谷歌发布了一款可以在智能手机上运行的小型模型之后,英伟达也加入了这场浪潮,推出了自己的新型小型语言模型(SLM):
Nemotron Nano v2。
这款9B的“小”模型在复杂推理基准测试上的准确率与Qwen3-8B相当或更高,速度快6倍。
再联系到他们前些天发布的论文观点:小模型才是智能体的未来,看来真不只是说说而已。

除了这款模型,他们首次“自豪地”开源了用于创建它的绝大部分数据,包括预训练语料库。

让我们来看一下……20万亿?Nemotron Nano v2在20万亿多个token上进行预训练?
与Qwen相比速度提升6倍
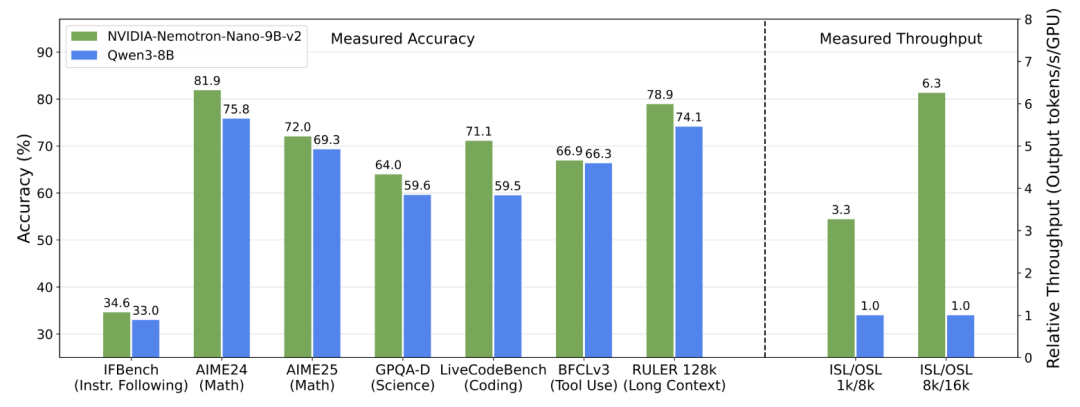
技术报告显示,Nemotron Nano v2在复杂推理基准测试上的准确率与同等规模的领先开源模型Qwen3-8B相当或更高,同时吞吐量——也就是模型速度——最高可提升6倍。
这款模型由英伟达从头训练,设计目标是成为兼顾推理与非推理任务的统一模型。
模型在响应用户查询或执行任务时,会首先生成推理过程(reasoning trace),随后输出最终答案。该模型支持“思考”预算控制,在推理过程中,用户可以指定模型被允许“思考”的token数量。
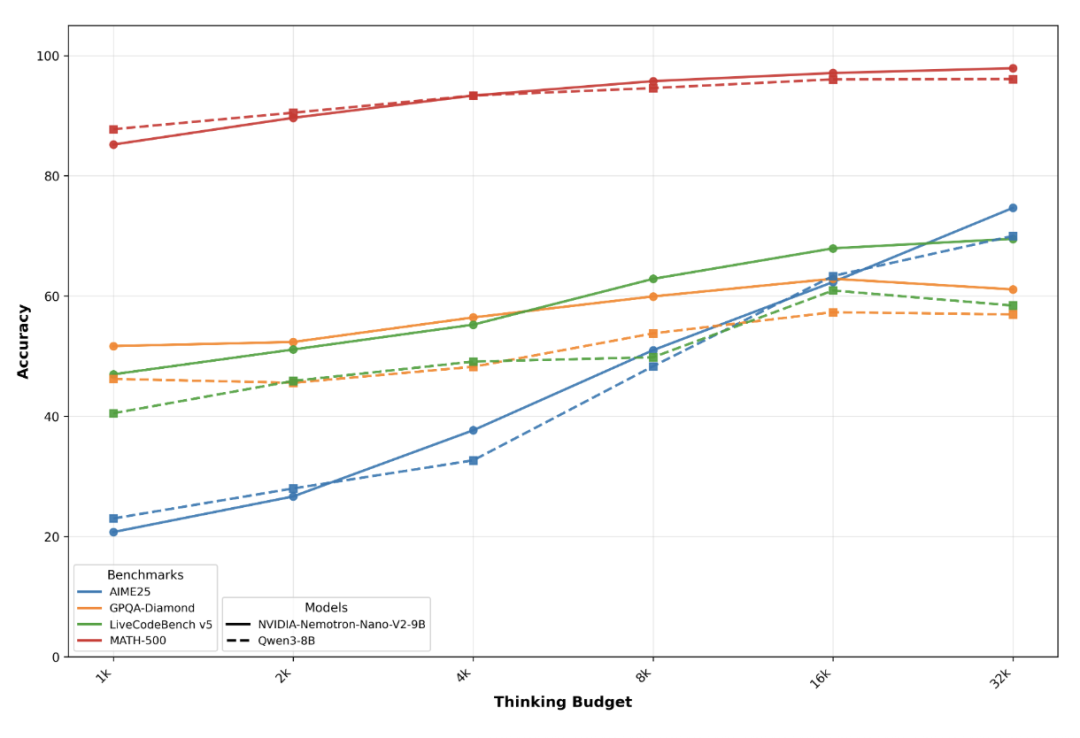
如果用户希望模型直接给出最终答案(跳过中间推理步骤),可通过配置实现,但这一做法可能导致对复杂推理类提示的准确率下降。
相反,若允许模型先展示推理过程,通常能显著提升最终答案的质量,尤其针对需逻辑分析的复杂任务。
面对网友“思考预算控制是如何实现的”的问题,英伟达的模型训练师Oleksii Kuchaiev表示:
我们最初采用了与Qwen3相同的实现方法,但发现当强制要求模型直接输出答案时,它仍会在预设的思维链之外进行“思考”。通过对截断思维链的训练,我们成功解决了这个问题。

基础模型同样开源
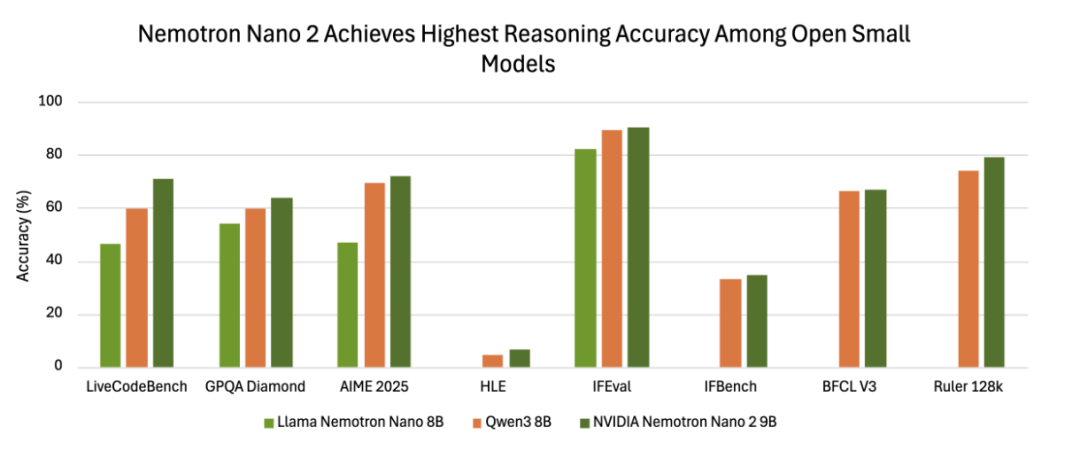
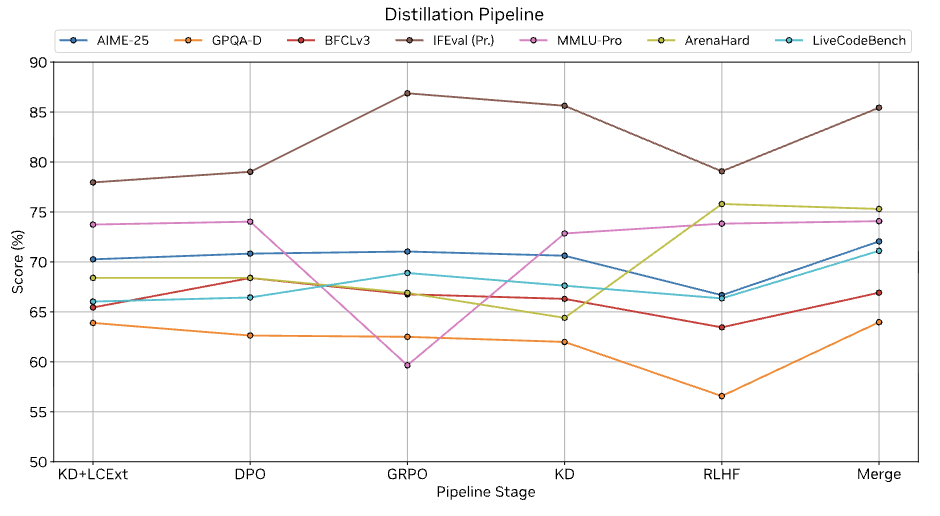
评估结果显示,与其他开源小规模模型相比,Nemotron Nano v2在准确率上具有优势。在 NeMo-Skills套件的“推理开启”模式下测试,该模型在AIME25上达到72.1%,在MATH500上达到97.8%,在GPQA上达到64.0%,在LiveCodeBench上达到 71.1%。
在指令遵循和长上下文基准测试中的得分也有报告:在IFEval上达到 90.3%,在RULER 128K测试中达到 78.9%,在BFCL v3和HLE基准测试中也有较小但可测量的提升。
Nemotron Nano v2经过了以下训练过程:
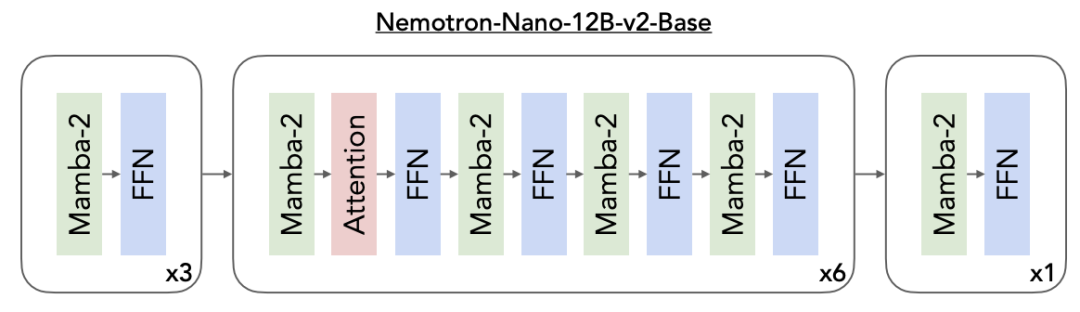
预训练:模型使用FP8精度在20万亿个token上进行预训练,采用Warmup-Stable-Decay学习率调度。随后进入持续预训练长上下文扩展阶段,使其在不降低其他基准测试性能的情况下达到128k的能力。
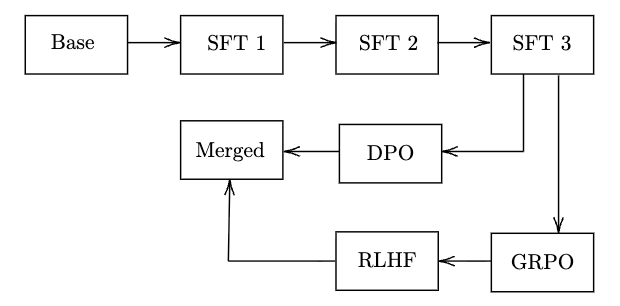
后训练:Nemotron Nano v2通过监督微调(SFT)、组相对策略优化(GRPO)、直接偏好优化(DPO)和人类反馈强化学习(RLHF)进行后训练。约5%的数据包含故意截断的推理轨迹,从而在推理时实现细粒度思考预算控制。
压缩:最后,基础模型和对齐模型均经过压缩(剪枝和蒸馏),支持在单个NVIDIA A10G GPU(22 GiB 内存,bfloat16 精度)上进行128k token的上下文推理。这一成果是通过扩展基于Minitron的压缩策略实现的,该策略专门针对受限条件下的推理模型压缩需求而设计。
除了Nemotron Nano v2模型本身,英伟达还发布了两个基础模型NVIDIA-Nemotron-Nano-12B-v2-Base(对齐或剪枝前的基础模型)和NVIDIA-Nemotron-Nano-9B-v2-Base(剪枝的基础模型),对应模型训练的不同阶段,均支持128k上下文长度。
最后,Nemotron Nano v2当前支持在线试用,链接可见文末。
超大预训练数据库
除了Nemotron Nano v2,英伟达首次发布了他们用于创建模型的绝大部分数据,包括预训练语料库。
至于为什么是“绝大部分”,有网友问了这个问题,官方回复简直不要太有道理(笑)。

预训练数据集Nemotron-Pre-Training-Dataset-v1包含66万亿个优质网络爬取、数学、代码、SFT 和多语言问答数据,并分为四个类别:
Nemotron-CC-v2:作为Nemotron-CC的升级版本,新增收录了2024至2025年间八个批次的Common Crawl网络快照数据。数据已进行全球去重,并使用Qwen3-30B-A3B进行合成改写。它还包含翻译成15种语言的合成多样化问答对,支持强大的多语言推理和通用知识预训练。
Nemotron-CC-Math-v1: 一个基于Common Crawl、使用英伟达的Lynx + LLM流程生成的1330亿token的数学专注数据集,在保留方程和代码格式的同时,将数学内容标准化为LaTeX格式。这确保了关键的数学和代码片段保持完整,从而生成高质量的预训练数据,在基准测试中优于先前的数学数据集。
Nemotron-Pretraining-Code-v1: 一个大规模的精选代码数据集,源自GitHub,并通过多阶段去重、许可证执行和启发式质量检查进行过滤。它还包括11种编程语言的LLM生成的代码问答对。
Nemotron-Pretraining-SFT-v1:一个综合生成的数据集,涵盖STEM、学术、推理和多语言领域。该数据集整合了多元化的高质量内容,包括从数学与科学核心题库提取的复杂多选题和分析题、研究生阶段的专业学术文献,以及经过指令微调的SFT数据。
Nemotron-Pretraining-Dataset-sample:该数据集的一个小型抽样版本提供了10个具有代表性的数据子集,涵盖了高质量问答数据、数学专项内容、代码元数据以及SFT指令数据。

One More Thing
顺带一提,最近英伟达的开源势头可以说是很猛了。
相比于其他国外科技巨头陆续走向的闭源道路,英伟达构建的Nemotron生态直接把开源二字写在了门面上。

无论是前段时间发布的Llama Nemotron Super v1.5,还是这次的Nemotron Nano v2,对标的也是国内开源模型Qwen3。
这样的策略会给他们带来什么?又会改变些什么?我们拭目以待。
参考链接:
[1]https://x.com/ctnzr/status/1957504768156561413
[2]https://research.nvidia.com/labs/adlr/NVIDIA-Nemotron-Nano-2/
[3]https://venturebeat.com/ai/nvidia-releases-a-new-small-open-model-nemotron-nano-9b-v2-with-toggle-on-off-reasoning/
论文:https://research.nvidia.com/labs/adlr/files/NVIDIA-Nemotron-Nano-2-Technical-Report.pdf
模型:https://huggingface.co/collections/nvidia/nvidia-nemotron-689f6d6e6ead8e77dd641615
试用:https://build.nvidia.com/nvidia/nvidia-nemotron-nano-9b-v2
— 完 —
