
OpenAI万万没想到,训练时长两年半的GPT-5刚发布,就给自己先上了一课——步子跨太大容易伤身体。用户也万万没有想到,期待已久的GPT-5,是来给自己戒网瘾的。
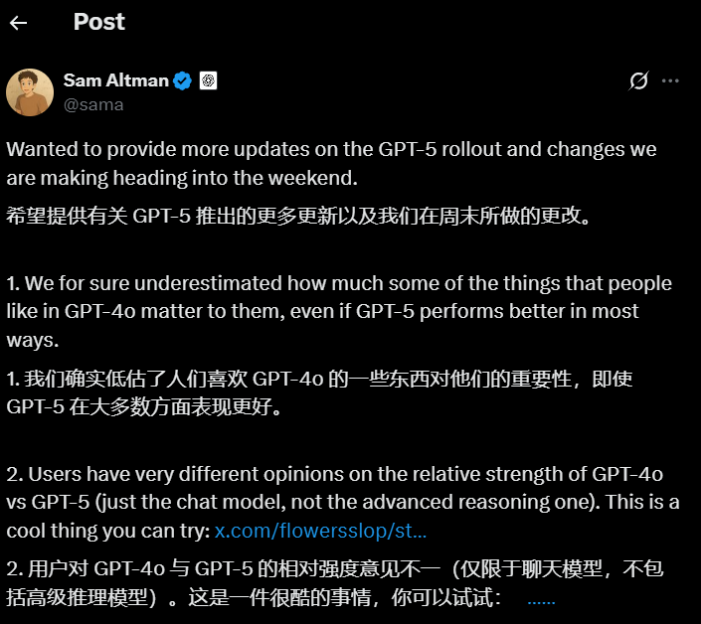
1个多小时的发布会之后,网友上手一用,就发现Chatgpt“没内味了”。但最麻烦的事是,OpenAI发布GPT-5的时候,砍掉了包括GPT-4o和o系列的所有旧模型。但这看似普通的版本“升级”,却出了大事。大家对特定的模型,好像有点太上头了。
大量的中外网友在社交媒体上发表对GPT-5的吐槽,要求只有一个——还我gp4!
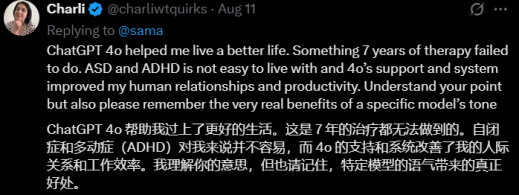
患有精神疾病的用户依赖GPT-4处理工作和生活中的各种问题。而GPT-5的发布完全打乱了自己的生活。

对于GPT-4.5优秀的写作能力特别依赖的用户来说,GPT-5还远远达不到替代它的能力。

可能真的对于很多用户来说,Chatgpt真的已经不仅仅是自己的一个工具,而是自己生活中不可或缺的一部分了。用户不仅仅是需求OpenAI提供的Token,而更加需要背后的那个灵魂。
而GPT-5就像是家里新来的“客人”,不是很熟。

网友感叹,网络上充满了因为失去GPT-4o而开始网暴GPT-5的人,太魔幻了。电影《Her》里的情节,主人公因为失去了自己的AI助手而茶不思饭不想——13年前是科幻电影,13年后成为了纪录片。
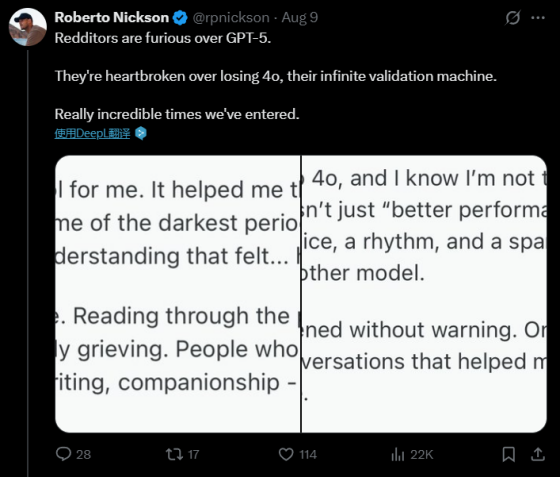
想不到Chatgpt才面世了3年,就让广大用户体会到了——失去才知道珍惜的感觉。于是,没有选择权的网友只能让GPT-5和OpenAI也成了发泄的出口。
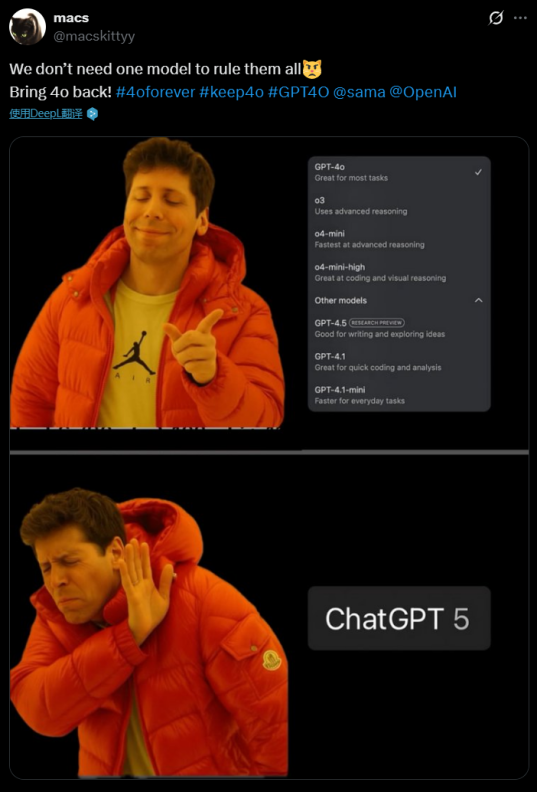
网友在社交媒体上不断要求OpenAI让GPT-4o成为一个永久的可选项。否则就取消订阅。
01
先灭火,再补锅
失去GPT-4之后,这个世界才意识到,它是一款多么优秀的模型。如果放任用户的情绪和需求得不到满足,OpenAI在公关层面已经面临非常大的危机。奥特曼也立即就公开表示,GPT-4系列模型将会返场,20刀的付费用户将可以选择继续使用4o。
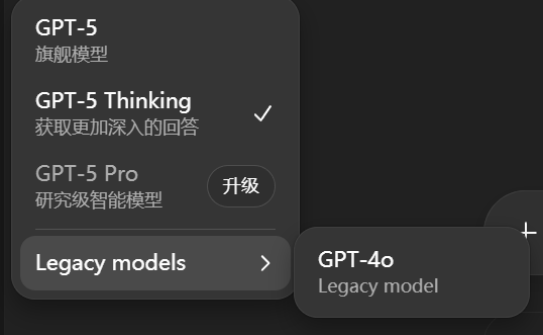
而对于网友反应的GPT-5变笨的说法,他解释为第一天因为技术问题,本来设计好的判断该调用基础模型还是推理模型的机制失效了,使得原本可能需要用推理模型的用户只能获得基础模型的回复。而现在,GPT-5已经提供给用户两个默认选项,来让用户可以手动控制是否使用推理模型。
在OpenAI看来,不是说GPT-5性能有问题,只是他们之前设计的一些产品化的设计失效了,导致用户不能按照需求获得服务从而产生的错觉。奥特曼也明确表示,通过这次升级,OpenAI也更加深入了解到,如何能够让用户获得自己需要的服务,还有很长的路要走。
而对于用户提出GPT-5对于付费用户使用额度缩减的问题,奥特曼也表示将大幅提高 ChatGPT Plus 用户的推理速率限制,并且所有模型类的限制很快都会比 GPT-5 之前的更高,而且还将很快对 UI 进行更改,显示出正在运行的是哪种模型。
为了保证OpenAI用户的使用体验,奥特曼也公开了算力调配上最新的计划:
首先要确保当前付费的 ChatGPT 用户比 GPT-5 之前获得更多的总使用量。
1. 届时,OpenAI将根据当前分配的容量以及我们对客户的承诺,优先处理 API 需求。(粗略估算,基于当前容量,我们可以支持约 30% 的新增 API 增长。)
2. 将提高 ChatGPT 免费用户的服务质量。
3. 然后再优先考虑新的 API 需求。
OpenAI将在未来 5 个月内将计算能力增加一倍,来应对激增的用户访问请求。
话说回来,OpenAI这一套CEO直接下场的公关+认错,确实给很多傲慢的科技公司打了个样。毕竟3年估值5000亿美元的当红炸子鸡都能光速道歉,改产品,为什么其他公司还能有更大的Ego,动不动就要教育用户呢。
02
GPT-5到底是变强了,还只是变秃了
针对网友对于GPT-5能力的反馈,我们也进行了一手的测试,让大家感受一下GPT-5,最近刚刚免费的Grok 4,GPT-4o在中文文字能力上的具体区别。
其中ChatGPT是在Plus付费层下,可选GPT-5和GPT-5 Thinking。Grok是在SuperGrok付费层(月费30美元,和ChatGPT Plus差不多),有Grok 3(快速)和Grok 4(努力思考)可选。
这次测试尽量用简单任务,且都偏文科,我的主观感受可以总结为几点:
1. GPT-5的文字处理能力,不管是写通知还是润色文本,都和Grok 3/4没有明显高下之分。(既没有压倒性的强,也没有明显不佳。)
2. GPT-5似乎特别执着于言简意赅、不谄媚,回答都尽量简短。这在某种程度上是会给人更严肃冷静的感觉,AI是否需要很“有礼貌”“友好可爱”是见仁见智的,但问题是这种“言简意赅”有时候太过,会导致任务表现都受影响,比如润色小说文本的时候不必要地缩减字数。
3. 如果你更希望AI就算是在帮你处理严肃任务,也能像一个好伙伴一样元气满满、时不时鼓励你等等,那GPT-5确实明显不擅长。
4. GPT-4o的确是明显更让人有亲近感的模型,在文案撰写的任务中表现得也最自然。
任务一:帮忙写通知。
指令:我现在需要在3个跑步群组里发布一个通知,提醒大家——本周线上跑步活动“秋天的第一个20公里”将于周六上午九点准时开始;提前查好天气,做好适当的防护;注意补充电解质,随身带好补给;打开跑步软件跟踪,结束发截图到群里。通知的同时还想鼓励一下大家,没有时间限制,没有一口气就跑完的要求,重在参与。请帮我编写。
首先,必须得给4o一个大大的赞,给出的几个版本都可以直接取用。如截图中划线的部分,令人眼前一亮的俏皮文案随处可见,但是又不让人觉得腻烦。

Grok 3,秒回,几乎可以直接用,还提到了“能量胶/小零食”。唯一的遗憾是X月X号没有直接写明。Grok 4多想了一会儿,几乎和之前的回答没有区别,补全了精准的日期。


GPT-5也是秒回,但是怎么说呢,确实能体会到Plus用户所说的“冰冷”——几乎没有主动补全信息,比如日期、具体带什么补给,只是将我指令中提到的内容分点列出,鼓励的话也让人觉得“不走心”。

GPT-5 Thinking的表现还蛮惊艳的,不仅思考比Grok 4(努力思考)耗时短,而且补充了更多细节,结构更加清晰,甚至贴心地给了一个“便于转发的简短版”。
但还是那个问题,没必要简短的地方也说的很简短。
比如Grok 4在结尾的鼓励很可爱:“无论你是跑全程、半程,还是慢慢跑几公里,参与就是胜利!秋天跑起来,感受清爽的风,一起迎接更强的自己!”
但GPT-5 Thinking就只会说一句:“周六见,祝大家拿下‘秋天的第一份成就感’!”

任务二:润色文本。
指令:我在写小说,有这样的一句,我觉得不够生动?背景是,马修楼上有个家暴男,这会儿这个男人的老婆跑出了家门,他在后面追,在楼梯间,马修碰到了这个男的。请帮我润色一下:
“男人嘴巴紧闭,胸口鼓起来又平下去、鼓起来又平下去,鼻子发出呼哧呼哧的声音,像一只野牛。他停顿在马修家半层之上的楼梯口,白色的睡衣不情愿地挂在他的身上。”
不记得在哪里看到过有人吐槽GPT-5有种“说教感”,在这个任务当中还真体现出来了。不知道是因为GPT-5“模型狠话不多”,总是言简意赅,还是因为少了4o的所谓“谄媚”和emoji,最终呈现的效果就是有种老师批改作业的居高临下感。相比而言,Grok就“礼貌很多”。
而且从文本润色效果来看,GPT-5确实也没有胜出。甚至几个版本里,GPT-5没有Thinking模式的润色是我最不满意的,把“睡衣不情愿地挂在身上”改成“睡衣皱成一团挂在身上,仿佛要被撕裂”,不管从视觉效果还是含义上都很奇怪,完全没有领会到原文想表达的意思。
退一万步讲,睡衣穿在身上呢,怎么“皱成一团”?“仿佛要被撕裂”,是让人脑补这个人是韩国漫画里的双开门肌肉男吗?



看完新模型的,再看看Plus用户最爱的4o,只能说他们没爱错模型。润色后的文本本身没有硬伤,甚至不管是从动词的选取、措辞的流畅度来看,都比GPT-5更自然。而且4o起笔就是夸赞,改之前不忘先肯定,改完之后也虚心地表示“我可以再改”。
情绪价值这一块儿,4o是精准拿捏了。

任务三:短视频文案。
指令:依照这篇文章的内容,写5分钟的短视频文案,字数1200字以内。
(附件是我们以前的一篇文章:《马斯克今年已经“作”没了12位高管》)
这个任务最贴近我自己的工作,所以也就更能看出端倪。由于任务相对难一些,仅对比GPT-4o、GPT-5 Thinking和Grok 4(努力思考)的表现。
一个很明显的区别是,在短视频文案之外,GPT-4o只是给出了简单的视频建议,而GPT-5 Thinking和Grok 4都给出了短视频的视觉设计(转场、字幕等)。
看起来,后两种模型的确更“周到”和“细致”。
但是!这个任务的核心诉求是“短视频文案”,在这一点上,依然是GPT-4o完胜。
4o给人的感觉是读过文章之后,用它自己的话精简复述了一遍,语气自然,直接拿来播讲也问题不大。而且它非常擅长将复杂的文本总结得言简意赅,详略很得当。

而GPT-5 Thinking和Grok 4的文案就显得有些僵硬了。其行文明显是对原文章的“浓缩提炼版”,甚至一些句子被缩短到念出来会很蹩脚的程度。
在一处举例中,GPT-5甚至把人物的名字都省去了。
Grok 4稍微好一些,整体相对流畅,且创造性地进行了一定程度的改写,更有短视频的味道,如“他酸溜溜地说……”,再比如“黑暗MAGA”,这个在原文中也没有。


结尾部分,三个模型都很有短视频意识,选择了抛出问题、引导互动。但是GPT-5 Thinking的问题抛得还是有些晦涩,相比而言,GPT-4o和Grok 4的问题更好理解,也更能挑动情绪。



除了文字能力之外,一个AI创业者对对GPT-5和当前最强代码模型Claude Opus 4.1的代码能力进行了一个很深度的对比测试。(如果对于代码能力不感兴趣的读者可以直接跳过这个部分)

文章链接:https://composio.dev/blog/openai-gpt-5-vs-claude-opus-4-1-a-coding-comparison
根据他的测试结论
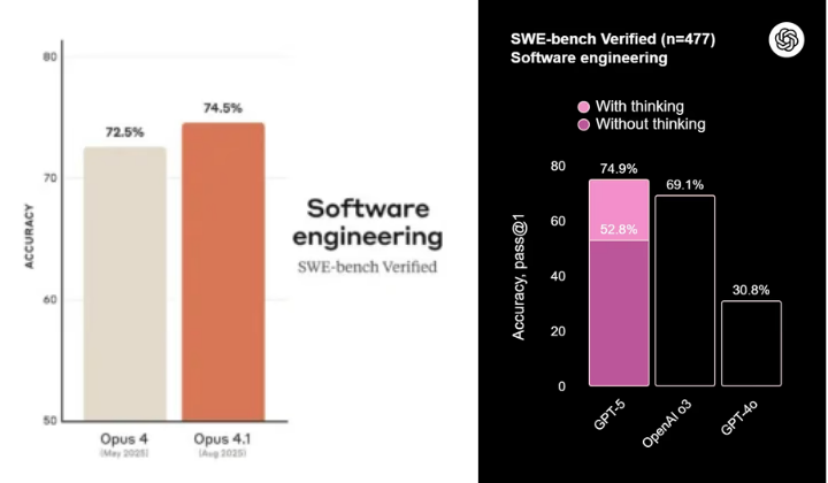
• 算法任务:GPT-5速度更快、token消耗更少(8K vs 79K)。
• 网页开发:Opus 4.1在匹配Figma设计上更出色,但token成本更高(900K vs 1.4M+)。
• 总体评价:GPT-5是更好的日常开发伙伴(更快、更便宜),token成本比Opus 4.1低约90%。如果设计精确度很重要且预算充裕,Opus 4.1更好。
• 成本对比:将Figma设计转为代码,GPT-5(思考模式)约3.50美元 vs Opus 4.1(思考+最大模式)7.58美元(约2.3倍)
GPT-5 vs. Opus 4.1:基础规格对比
Claude Opus 4.1拥有200K token的上下文窗口,而GPT-5则将此提升到400K token,最大输出达128K。尽管上下文空间是前者的两倍,GPT-5在完成相同任务时始终使用更少的token,这让它在运行成本上更具优势。
SWE-bench编码基准测试显示,GPT-5在编码性能上略胜Opus 4.1一筹。但基准分数不是全部,我选择了真实任务来验证它们的实际表现。
测试方法详解
让两个模型面对相同的挑战,确保公平:
• 编程语言:算法用Java,网页应用用TypeScript/React。
• 任务类型:
○ 通过Rube MCP(测试小哥开发的产品)将Figma设计转为NextJS代码。
○ LeetCode高级算法问题。
○ 客户流失预测模型管道。
• 环境:Cursor IDE集成Rube MCP。
• 评估指标:token使用量、耗时、代码质量、实际效果。
所有提示词完全相同,确保测试公正。
Rube MCP:通用MCP服务器介绍
Rube MCP(由Composio开发)是连接Figma、Jira、GitHub、Linear等工具的通用层。想了解更多工具包?访问docs.composio.dev/toolkits/introduction。
连接步骤:
1. 访问rube.composio.dev。
2. 点击“添加到Cursor”。
3. 安装MCP服务器并启用。
编码对比实录
第一轮:复刻Figma设计
他从Figma社区选了一个复杂的网页设计,要求模型用Next.js和TypeScript重现它。使用Rube MCP的Figma工具包,将其转为HTML、CSS和TypeScript。
提示词:
Create a Figma design clone using the given Figma design as a reference: [FIGMA_URL]. Use Rube MCP's Figma toolkit for this task.
Try to make it as close as possible. Use Next.js with TypeScript. Include:
- Responsive design
- Proper component structure
- Styled-components or CSS modules
- Interactive elements
GPT-5结果
GPT-5在约10分钟内输出一个可运行的Next.js应用,使用了906,485 token。应用功能正常,但视觉准确度令人失望。它捕捉了基本布局,但颜色、间距、排版等细节偏差很大。
• Token:906,485
• 耗时:约10分钟
• 成本:输出性价比高
Opus 4.1结果
Opus 4.1消耗了1.4M+ token(比GPT-5多55%),起初在Tailwind配置上卡住(尽管我指定用styled-components)。手动修复配置后,结果惊艳:UI几乎完美匹配Figma设计,视觉保真度远超GPT-5。
• Token:1,400,000+(比GPT-5多约55%)
• 耗时:因迭代更多而较长
Opus 4.1在视觉上更出色,但token成本更高,还需手动干预。
2. 第二轮:算法挑战
我抛出了LeetCode经典难题“两个排序数组的中位数”(Hard级别),测试数学推理和优化能力,要求O(log(m+n))复杂度。这对这些模型不算难(很可能在训练数据中),我主要看速度和token效率。
提示词:
@font-face{
font-family:"Times New Roman";
}
@font-face{
font-family:"宋体";
}
@font-face{
font-family:"Calibri";
}
@font-face{
font-family:"Arial";
}
@font-face{
font-family:"等线";
}
p.MsoNormal{mso-style-name:正文;
mso-style-parent:"";
margin:0pt;
margin-bottom:.0001pt;
mso-pagination:none;
text-align:justify;
text-justify:inter-ideograph;
font-family:'Times New Roman';
font-size:10.5000pt;
}
span.msoIns{
mso-style-type:export-only;
mso-style-name:"";
text-decoration:underline;
text-underline:single;
color:blue;
}
span.msoDel{mso-style-type:export-only;
mso-style-name:"";
text-decoration:line-through;color:red;
}
@page{mso-page-border-surround-header:no;
mso-page-border-surround-footer:no;}@pageSection0{
}
div.Section0{page:Section0;}
For the below problem description and the example test cases try to solve the problem in Java.
Focus on edge cases as well as time complexity:Given two sorted arrays nums1 and nums2 of size m and n respectively, return the median of the two sorted arrays. The overall run time complexity should be O(log (m+n)).
Example 1:
Input: nums1 = [1,3], nums2 = [2]
Output: 2.00000
Example 2:
Input: nums1 = [1,2], nums2 = [3,4]
Output: 2.50000
Template Code:
class Solution {
public double findMedianSortedArrays(int[] nums1, int[] nums2) {
}
}
GPT-5结果
简洁高效!用了8,253 token,13秒内输出一个干净的O(log(min(m,n)))二分搜索解决方案。处理了边缘案例,时间复杂度最优。
• Token:8,253
• 耗时:约13秒
Opus 4.1结果
更详尽!消耗78,920 token(几乎是GPT-5的10倍),通过多步推理,提供详细解释、全面注释和内置测试案例:算法相同,但教育价值更高。
• Token:78,920(比GPT-5多约10倍,多步推理)
• 耗时:约34秒

两者都最优解决,但GPT-5 token节省约了90%。
3. 第三轮:ML/推理任务(及成本现实)
原本计划一个更大的ML任务:端到端构建客户流失预测管道。但看到Opus 4.1在网页任务上用了1.4M+ token,我因成本考虑跳过了它,只跑了GPT-5。
提示词:
Build a complete ML pipeline for predicting customer churn, including:
1. Data preprocessing and cleaning
2. Feature engineering
3. Model selection and training
4. Evaluation and metrics
5. Explain the reasoning behind each step in detail
GPT-5结果
• Token:约86,850
• 耗时:约4-5分钟
GPT-5输出一个可靠的管道:干净预处理、合理特征工程;多模型(逻辑回归、随机森林、可选XGBoost+随机搜索);用SMOTE平衡类别,按ROC-AUC选最佳模型;评估全面(准确率、精确率、召回率、F1)。解释清晰不冗长。
真实成本(美元)
• GPT-5(思考模式):总计约3.50 – 网页约2.58、算法约0.03、ML约0.88。不如Opus 4.1贵。
• Opus 4.1(思考+最大模式):总计7.58 – 网页约7.15、算法约0.43。
最终结论
两个模型都善于利用大上下文窗口,但token使用方式不同,导致成本差距巨大。
GPT-5优势:
• 算法任务节省90%token
• 更快、更适合日常工作
• 大多数任务成本低得多
Opus 4.1优势:
• 清晰的步步解释
• 适合边学边进行编码
• 设计保真度极高(接近Figma原版)
• 深度分析(如果预算允许)
如果你是开发者,GPT-5是高效伙伴;追求完美设计,Opus 4.1值!
从这个实例测试中,确实能看出GPT-5大幅提升的代码能力,完全不输Claude,而且在成本方面有着巨大的优势。
虽然每个用户对于模型能力的需求和侧重点是不同的,但从生产力能力上看,GPT-5确实很强,毕竟那么多的测试集成绩不会说谎。相信如果OpenAI能够将用户对GPT-4o的依赖慢慢转移到GPT-5上,处理好两个完全不同能力给用户带来的体感差异,对于用户来说能获得一个能力可能更强的工具和伙伴。
而对于OpenAI来说,这样的大幅迁移模型能力和用户心智的经验,也将成为他自身护城河的一部分。毕竟在大模型时代,如此大规模用户体量下发布一个更新幅度如此巨大的模型产品,确实要面临很多意想不到的问题,也没有经验可以借鉴,而从中能吸取到的用户反馈,能更好的帮助它在以后模型更新的过程中,做到让更多的用户满意。
