
如果说有什么科技产品在被大量爆料后,依然能让人在凌晨蹲守直播,除了苹果 iPhone,就是 OpenAI 的 ChatGPT 了。
GPT-4 亮相后很长一段时间,都是 AI 友商的唯一对标。世界也开始逐渐接受一个事实:AI 正在越来越多的任务中展现出超越人类的能力。
今天,GPT-5 终于登场,把这条称作「及格线」的标准,再次抬高了一个维度。
我们也第一时间上手 GPT-5,让它给自己的生日写首诗,满分十分,你觉得可以打几分?



还是经典的天气卡片环节,GPT-5 的 UI 审美质量相当能打。

我们在 Flowith 里也实测了 GPT-5 的编程能力。
详情可点击链接前往:第一时间体验 GPT-5!人人免费可用,马斯克表示不服
OpenAI CEO 山姆·奥特曼对 GPT-5 给出了极高评价,称其是此前所有模型的巨大飞跃,在他看来,拥有 GPT-5 这样的 AI 系统,在历史上任何时候都是难以想象的。
▲(主界面)
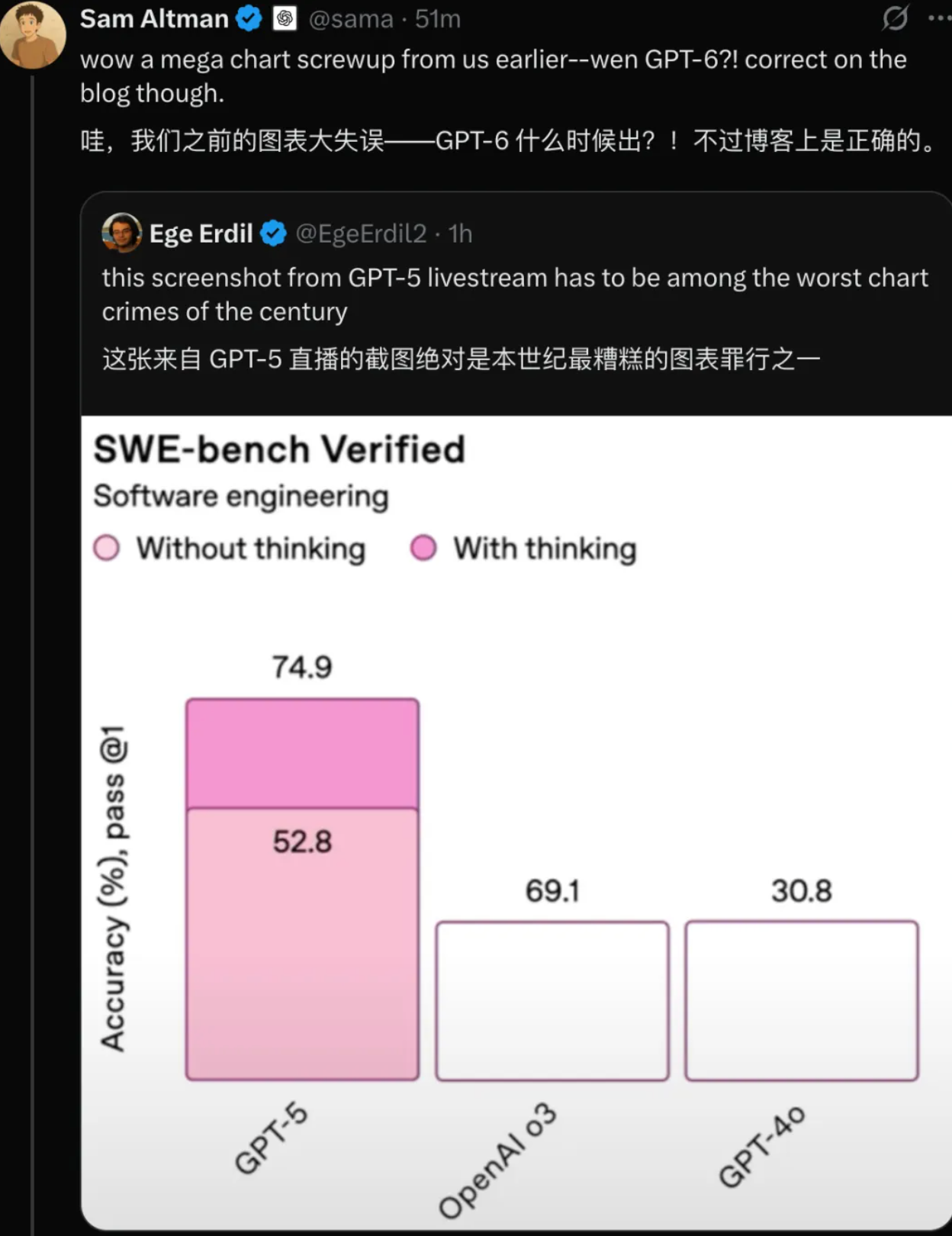
不过,发布会现场也上演了「翻车」环节,图表数据环节出现了明显「胡编乱造」的失误,连奥特曼也忍不住发文自嘲。
他表示 Grok 4 在 ARC-AGI 测试中击败了 GPT-5,还顺势拉踩一波,并剧透 Grok 5 将于今年年底前发布,预计表现将更加出色。
GPT-5 来了,编程、写作能力大提升,还要当你的 AI 医生
GPT-5 在编码、数学、写作、健康和视觉感知等多个领域都实现了显著提升,同时在减少幻觉、改进指令遵循和降低谄媚方面取得了重大进展。
GPT-5 采用了全新的统一系统设计,包含三个核心组件:一个高效的基础模型用于处理常规问题,一个具备深度推理能力的「GPT-5 thinking」模型专门应对复杂任务,以及一个实时路由器负责根据对话复杂度、工具需求等因素选择合适的模型。

这套「路由系统」会持续学习用户的切换行为、反馈偏好和答案准确性,不断优化分配策略。当用户达到使用限制时,系统会自动切换到各模型的精简版本继续服务。
据介绍,GPT‑5 是 OpenAI 迄今为止最强大的编码模型,能够处理复杂的前端开发和大型代码库调试工作。奥特曼表示:「根据需求即时生成的软件的理念将成为 GPT-5 时代的一个重要特征。」
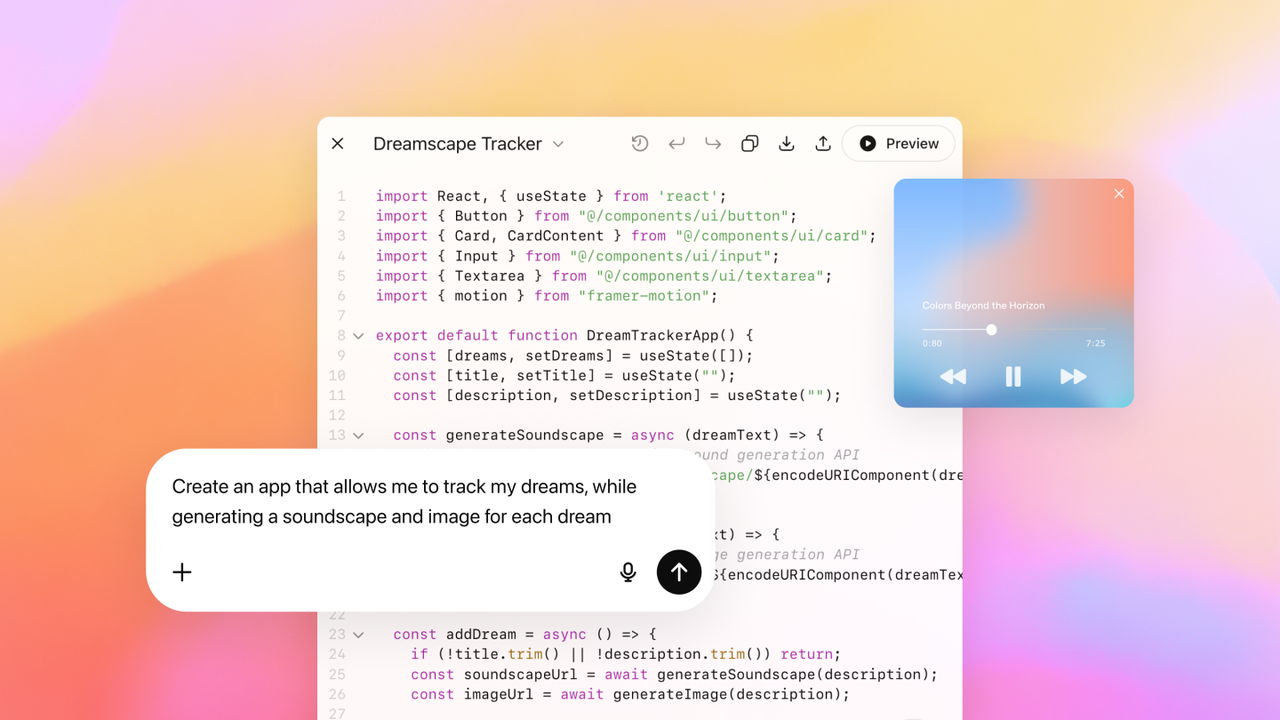
比如它能通过一个提示就创建出功能完整、设计精美的网站、应用和游戏。根据以下提示词, GPT‑5 成功创建了一个名为「跳跃球跑者」的游戏,包含速度递增、计分系统、音效和视差滚动背景等所有要求功能。
「提示: 创建一个单页应用,要求如下,且全部写在一个 HTML 文件中:
– 名称:跳跃球跑者
– 目标:跳过障碍,尽可能长时间生存。
– 特点:速度逐渐加快,高分记录,重试按钮,以及动作和事件的有趣音效。
– 角色应该看起来卡通化,观赏起来有趣。
– 游戏应该让每个人都感到愉快。」

写作方面,GPT-5 能够将粗糙想法转化为具有文学深度和节奏感的文本。
它在处理结构复杂的写作形式时更加可靠,比如能够保持格律,同时兼顾形式规范与表达清晰。这些改进让 ChatGPT 在日常文档处理、邮件撰写等任务中更加实用。

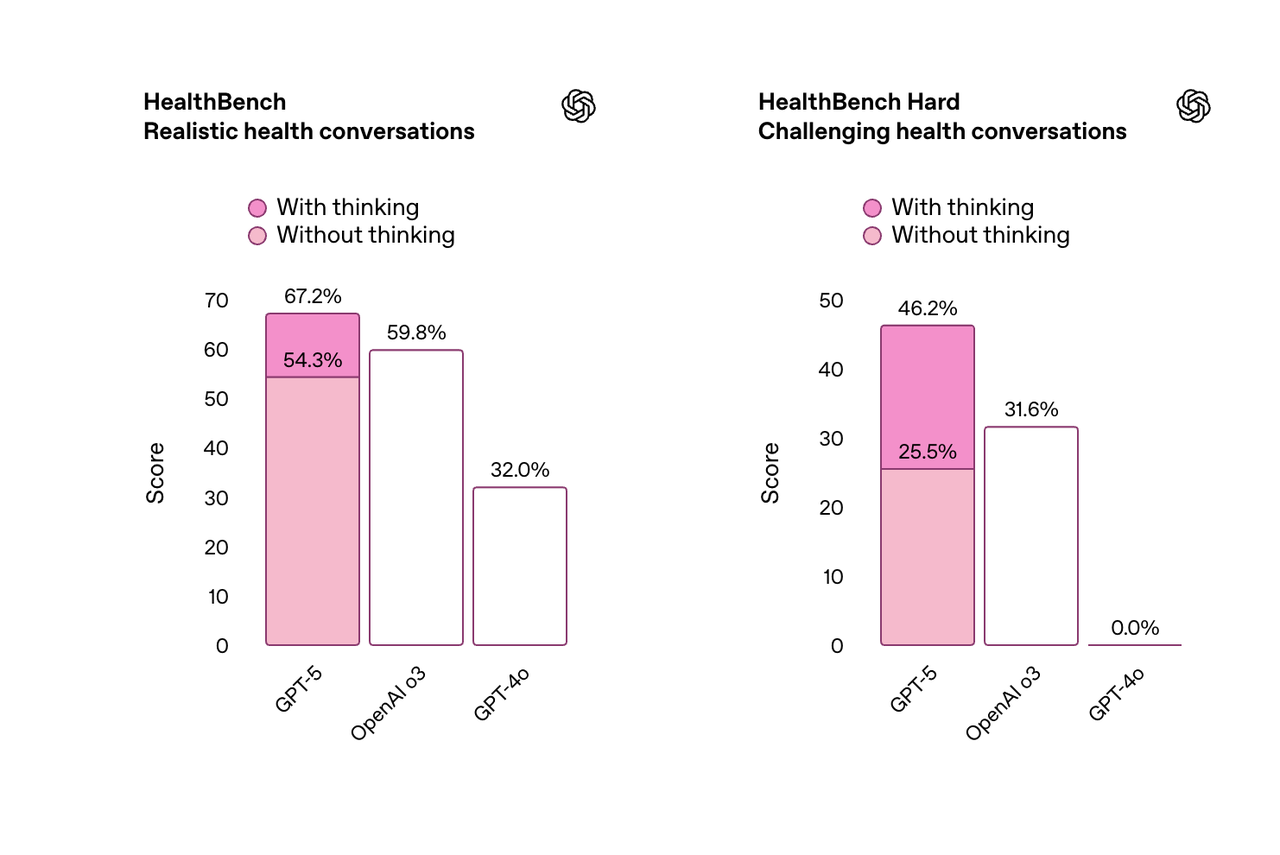
此外,GPT-5 还是 OpenAI 在健康相关问题上表现最佳的模型。
在基于真实场景和医生标准制定的 HealthBench 评估中,GPT-5 的得分远超以往所有模型。新模型能够主动发现潜在问题,提出针对性问题,并根据用户背景、知识水平和地理位置提供个性化建议。
奥特曼负责介绍 GPT-5 健康的这部分,在发布会现场,他邀请了 Carolina 和 Filipe 夫妇分享他们的亲身经历。
Carolina 曾在一周内被诊断出三种不同的癌症,在她把这些充满医学术语的报告丢给 ChatGPT 后,ChatGPT 在几秒钟内将复杂的内容,翻译成了她能理解的直白语言,帮助她更好地和医生沟通。

而在面对是否接受放射治疗,这一个连医生们的意见都没有办法统一的问题上,ChatGPT 为她详细分析了案例的细微差别、风险与收益等等,她说这比和医生聊三十分钟的收获都要更多。
当然,ChatGPT 并不能替代医疗专业人员,建议谨慎使用。
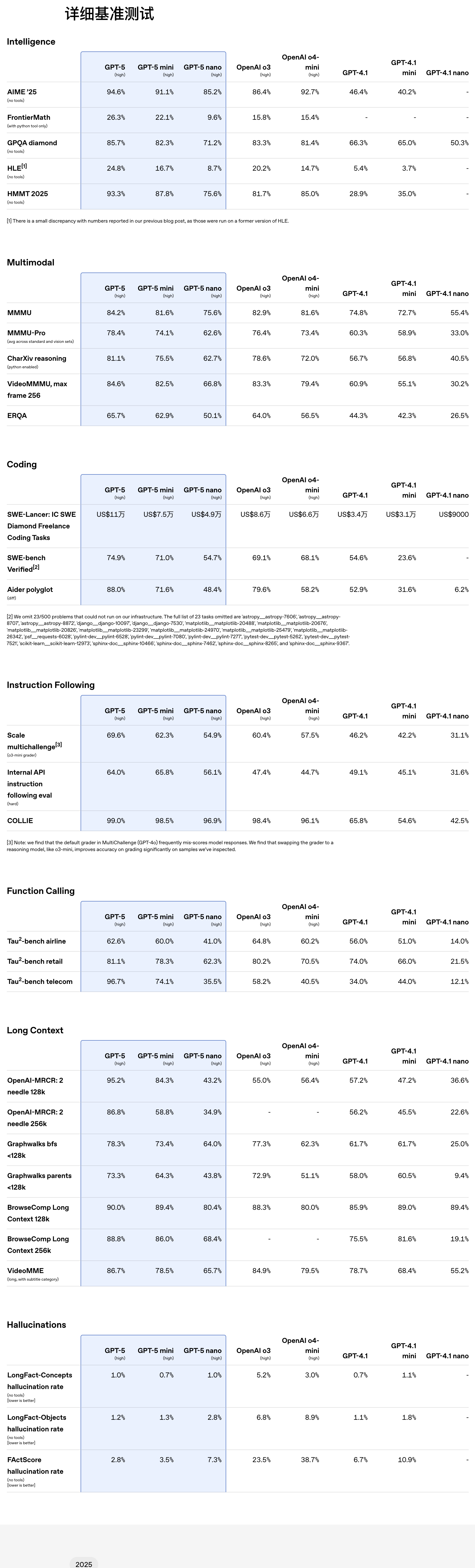
基准测试结果显示,GPT-5 在多项基准测试中刷新纪录:
数学能力:AIME 2025 (no tools)测试得分 94.6%
编程能力:SWE-bench Verified(With thinking)得分 74.9%,Aider Polyglot(With thinking)得分 88%
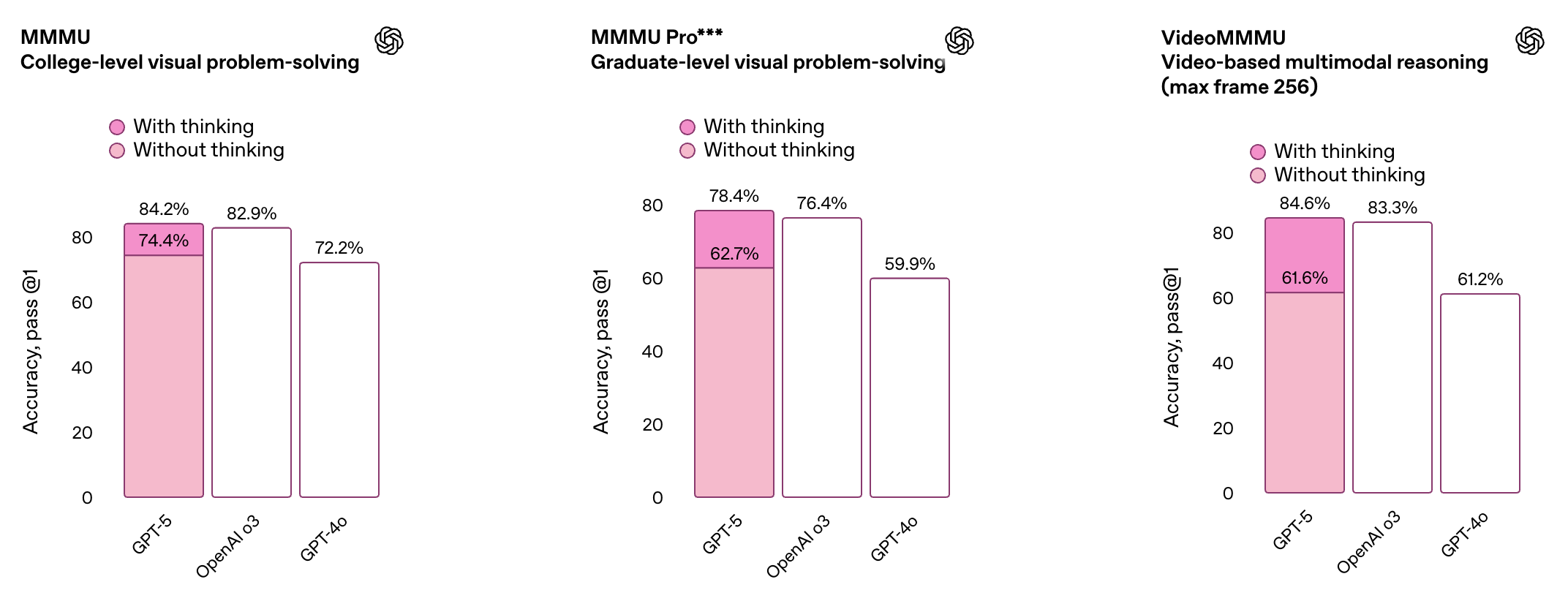
多模态理解:MMMU 得分 84.2%
健康领域:HealthBench Hard 得分 46.2%
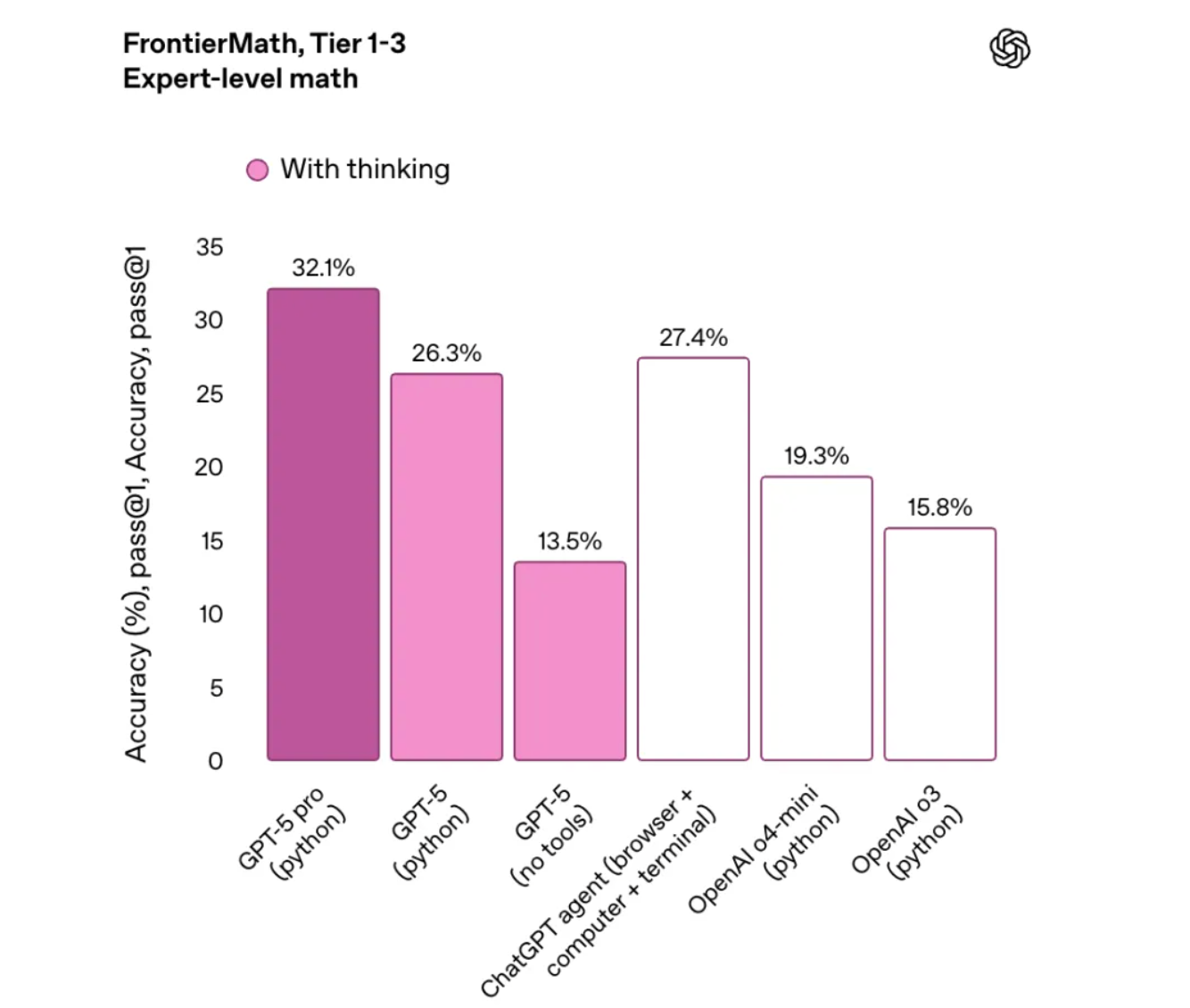
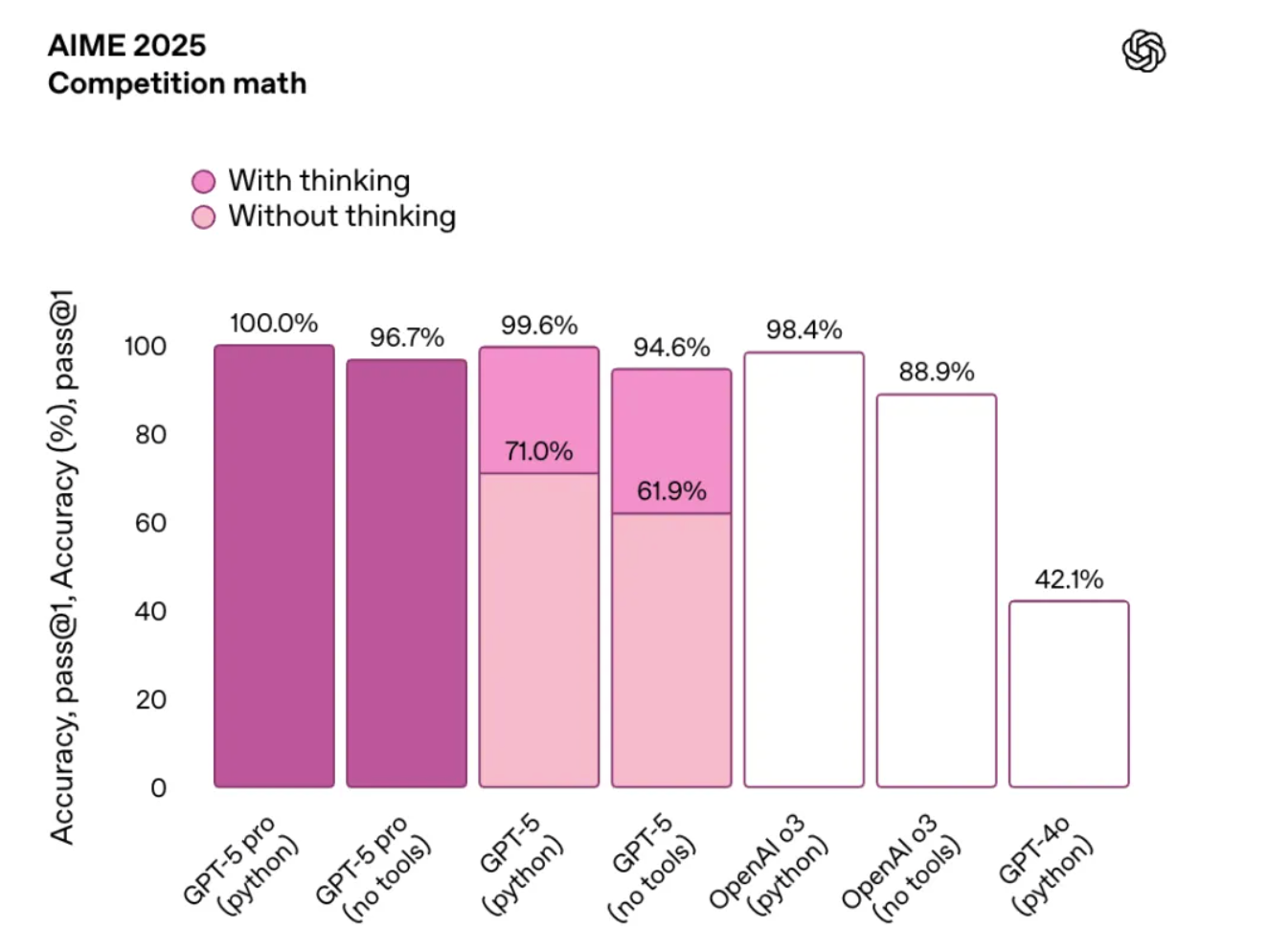
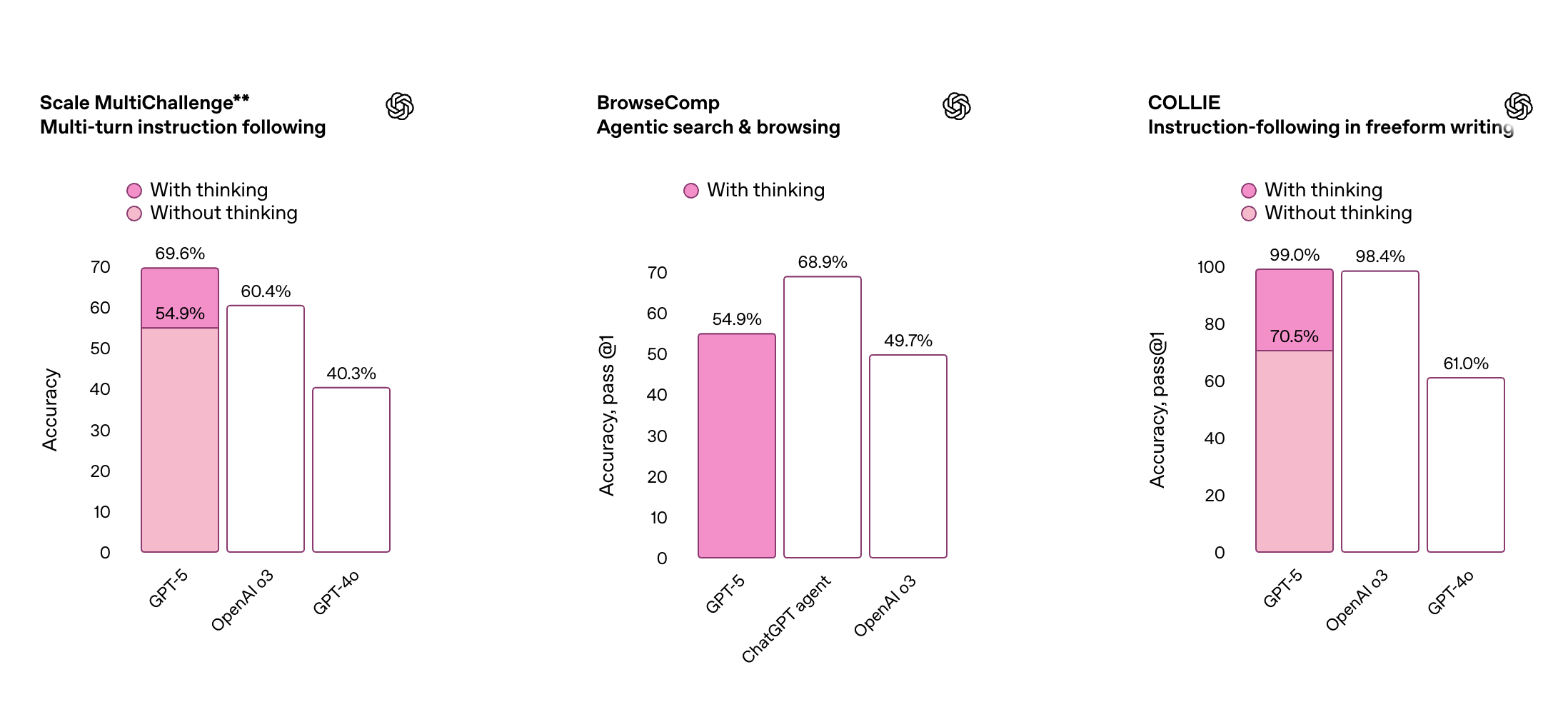
GPT-5 在指令执行和自主调用工具的能力也有所提升,能够更加稳定地完成多步骤请求,灵活协调多个工具,并根据上下文智能调整行为策略,展现出更强的任务适应能力。
同时,GPT-5 在多项多模态基准测试中同样表现亮眼,覆盖视觉识别、视频理解、空间判断及科学推理等多个维度。得益于其更强的感知与推理能力,ChatGPT 现在能更准确地处理图像及其他非文本输入内容。
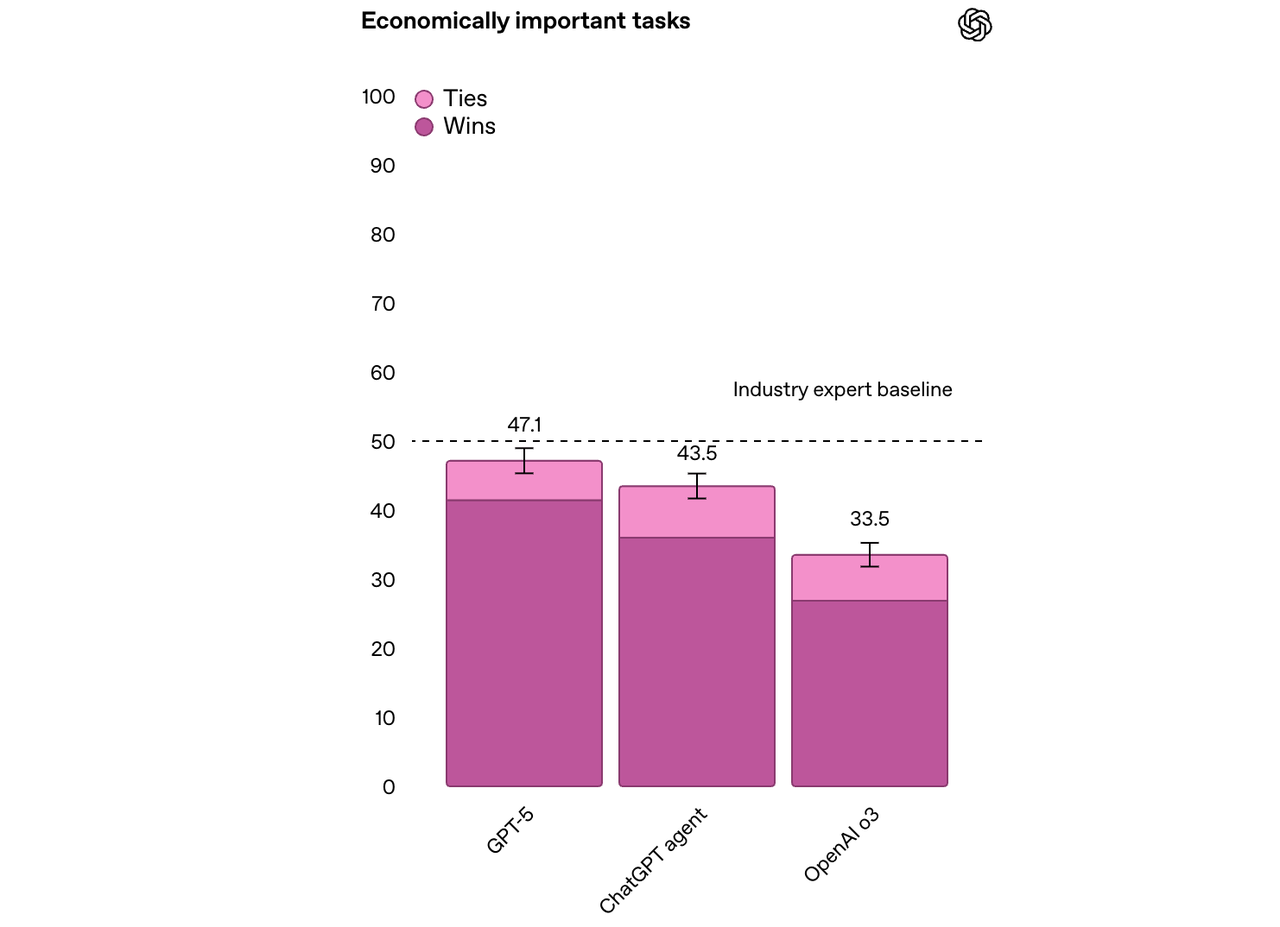
在 OpenAI 的内部基准测试中,GPT-5 在约 50% 的复杂知识工作任务中达到或超越专家水平,涵盖法律、物流、销售、工程等 40 多个职业领域,表现优于 o3 和 ChatGPT Agent。
OpenAI 特别强调,GPT-5 是在微软 Azure AI 超级计算机上训练的。
此外,GPT-5 在推理效率上也有突破。在视觉推理、编码和研究生级科学问题解决等任务中,GPT- 5的表现优于 OpenAI o3,但输出 token 数量减少了 50-80%。
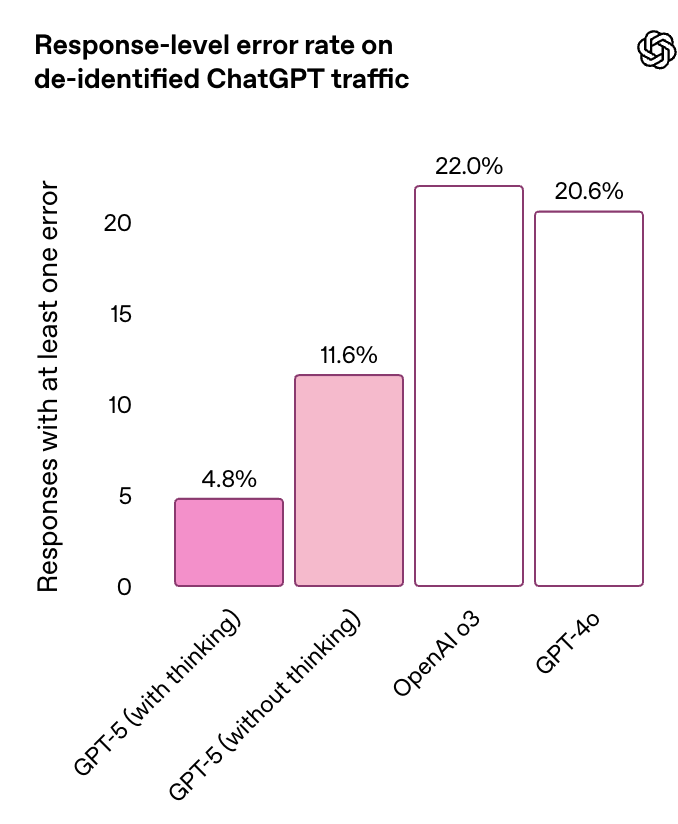
幻觉问题一直是 AI 的老大难,而与 OpenAI 之前的模型相比,GPT-5 出现幻觉的可能性有了显著降低,模型在处理复杂、开放性问题时更加得心应手。
在代表 ChatGPT 生产环境流量的匿名测试中,GPT-5 的事实错误率比 GPT-4o 降低约 45%;启用推理功能时,错误率比 OpenAI o3 降低约 80%。
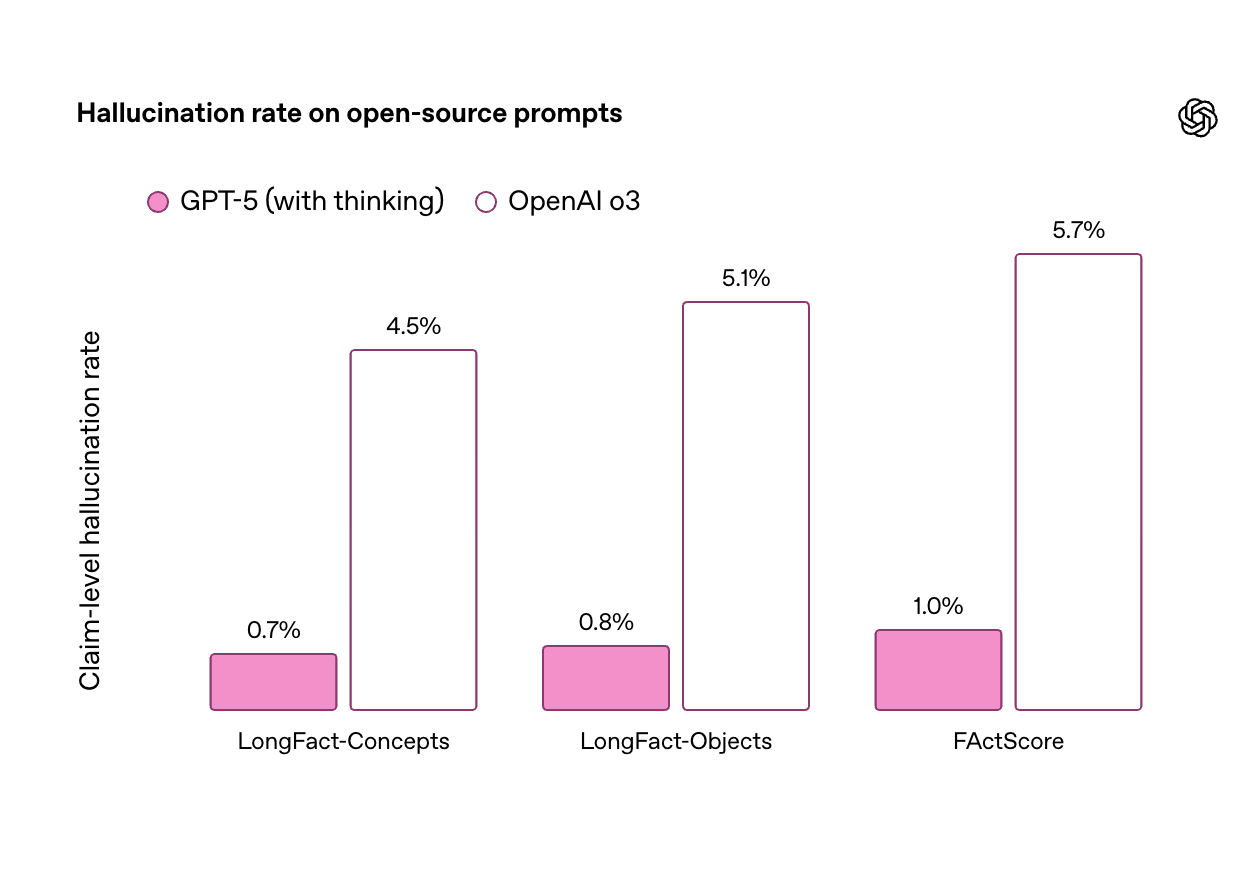
在开放性事实准确性基准 LongFact 和 FActScore 测试中,「GPT-5 thinking」的幻觉率比 o3 减少约六倍,标志着长篇内容生成准确性的显著提升。
除了事实准确性的提升,GPT-5(具备思考能力)还能更诚实地向用户传达其行为和能力。据模型安全研究负责人 Alex Beutel 称,OpenAI 对 GPT-5 进行了「超过五千小时」的测试,以了解其安全风险。
GPT-5 还引入了「安全完成(Safe Completion)」这一全新安全训练方式,让模型在保持安全边界的同时尽可能提供有用答案。当需要拒绝请求时,GPT-5 会透明地说明拒绝原因并提供安全替代方案。
在用户体验方面,GPT-5 减少了过度附和行为,在专门设计的谄媚测试中,谄媚回复率从 14.5% 降至不足 6%。新模型使用更少不必要的表情符号,回应更加细腻和深思熟虑。
此外,OpenAI 还为所有用户推出了四种预设个性:愤世嫉俗者、机器人、倾听者和书呆子,这些个性最初适用于文本聊天,晚些时候将上线语音。用户可根据个人喜好调整 ChatGPT 的交互风格。
在现场的演示中,语音交互变得非常自然且可控。
OpenAI 的研究员要求 GPT-5 从现在开始只用一个词回答问题,当被要求分享一句智慧之言时,GPT-5 回答:「Patience」(耐心)。发布会现场大家都笑了,主持人说这也许是模型在感谢大家耐心等待 GPT-5 的发布。

免费用户也能用,还有一款真香模型
取代 OpenAI o3-pro,OpenAI 还发布了 GPT-5 pro,这是 GPT-5 的一个变体,能够进行更长时间的思考,采用规模化但高效的并行测试时计算,能够提供最高质量和最全面的答案。
在 1000 多个具有经济价值的真实世界推理提示评估中,外部专家在 67.8 %的情况下更倾向选择 GPT-5 Pro,其重大错误率较 GPT-5 减少 22%,并且在健康、科学、数学和编码方面表现出色,获得专家们的一致好评。
GPT-5 今天开始成为 ChatGPT 的新默认模型,向所有 Plus、Pro、Team 和免费用户推出,Enterprise 和 Edu 用户将在一周后获得访问权限。
免费版用户每 5 小时可发送 10 条消息,Plus 用户每 3 小时可发送 80 条消息。

Pro 用户可无限制访问 GPT-5 及 GPT-5 Pro,免费用户达到使用限制后将自动切换到 GPT-5 mini。Pro、Plus 和 Team 用户还可以通过 ChatGPT 登录 Codex CLI,在开发环境中调用 GPT-5 来完成代码编写、调试等任务。
虽然 GPT-5 已对所有用户开放,但 ChatGPT 免费用户并不会立即获得完整的 GPT-5 使用体验。。一旦免费用户达到 GPT-5 的使用限制,他们将切换到更小、更快的精简版模型 GPT-5 mini。
面向开发者,OpenAI 还为 API 平台推出三个不同规格的版本:gpt-5、gpt-5-mini 和 gpt-5-nano,开发者可根据项目对性能、成本和响应速度的不同要求灵活选择。
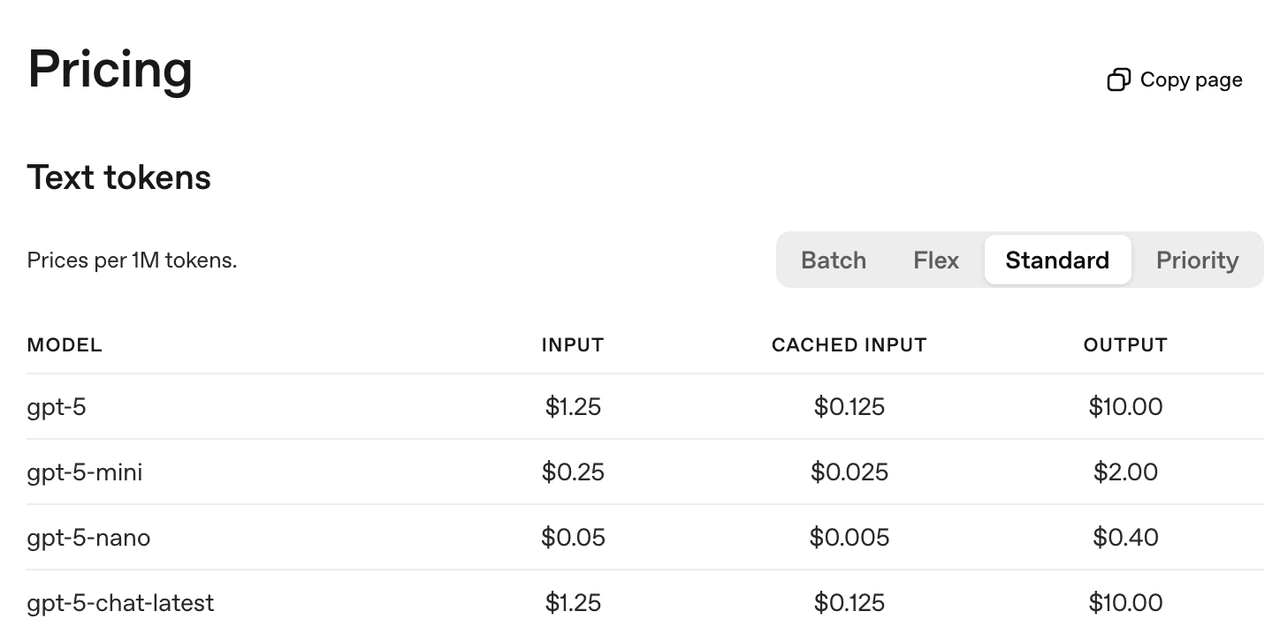
GPT-5 支持回复 API、聊天完成 API 等主流接口,同时成为 Codex CLI 的默认模型。所有版本都具备reasoning_effort 和 verbosity 参数控制能力,以及自定义工具功能。
除基础对话能力外,GPT-5 还集成了并行工具调用、内置工具(网络搜索、文件处理、图像生成)、流式处理、结构化输出等核心功能,以及提示缓存和批量 API 等成本优化特性。
GPT-5 API 还推出四项核心新功能,大幅提升开发者的使用体验。
首先,通过 reasoning_effort 参数,开发者能根据不同任务场景,在最小、低、中、高四个档位间灵活切换。简单任务用最小档快速响应,复杂问题用高档深度思考,让开发者在回答质量和响应速度间找到最佳平衡点。

在回答详细程度上,verbosity 参数支持低、中、高三档设置,帮助控制回答的详细程度。比如在「天空为什么是蓝色」这一问题上,低档回答简洁明了,高档回答则包含详细的科学解释。
在工具调用方式上,新增的自定义工具功能支持纯文本格式,彻底告别 JSON 转义字符的困扰。处理大量代码或长文档时,开发者无需再为格式错误而烦恼。
值得注意的是,整个执行过程是可追踪,GPT-5会在执行工具调用时主动输出进度更新,让开发者了解 AI 的执行计划和当前状态。
另外,区别于 ChatGPT 中的 GPT-5 系统,API 版本专门针对开发者需求优化,更适合编程和 Agent 任务场景。
包括 Windsurf、Vercel、JetBrains 等知名开发工具和平台都对 GPT- 5给出积极评价。Windsurf 指出,GPT-5 在评估中达到最先进水平,「与其他前沿模型相比,工具调用错误率仅为其一半」。
GPT-5 的发布,对 Claude 而言可能是一记直击命门的重拳。
据外媒 The Information 报道,Anthropic 当前 50 亿美元的年化收入中,有超过六成来自 API,其中仅 Cursor 和 GitHub Copilot 这两家编程客户就贡献了 14 亿美元。这种把鸡蛋放在同一个篮子里的收入结构,恰恰暴露了 Anthropic 脆弱的软肋。
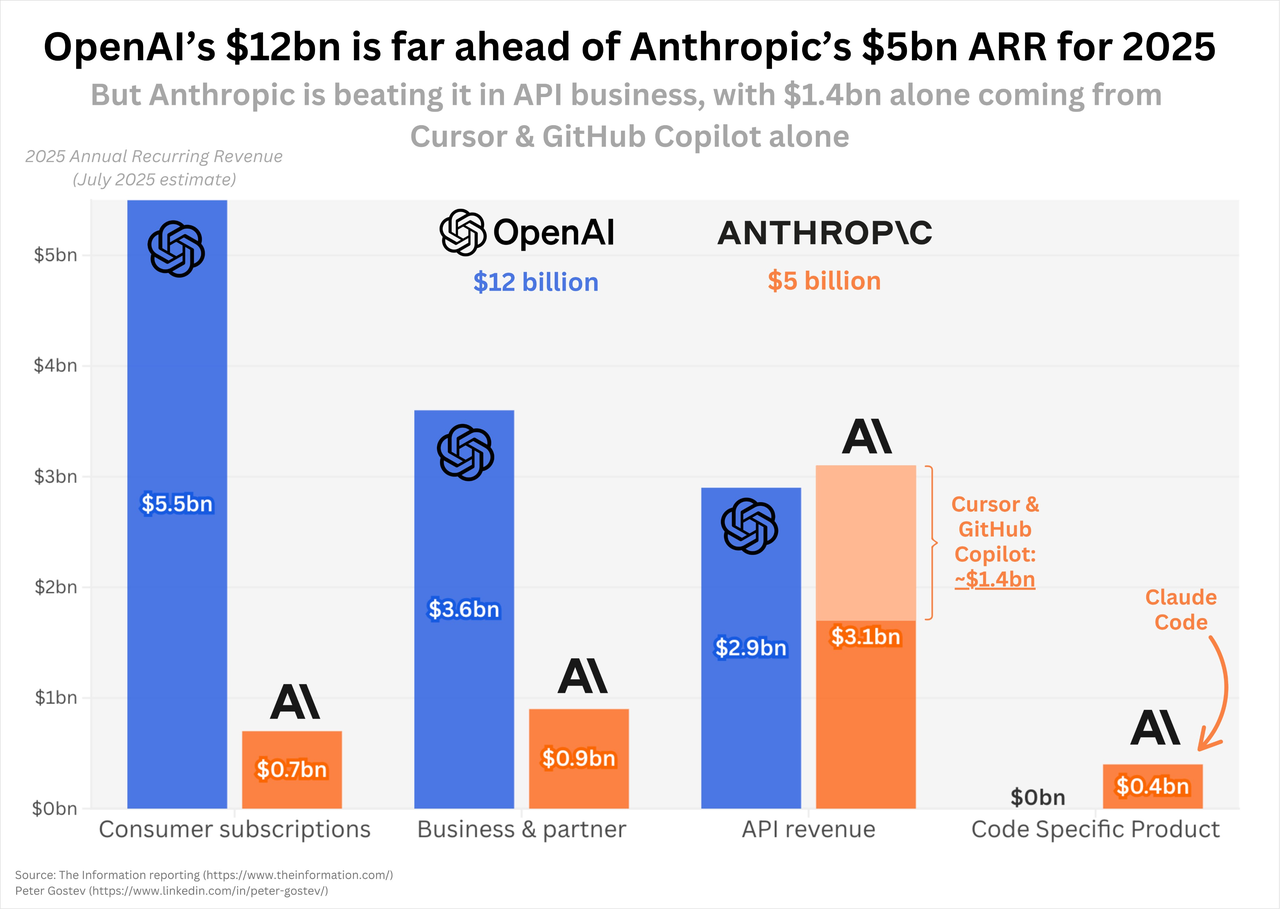
编程工具市场的残酷之处在于性能即一切,哪怕是 5% 的准确率提升,对开发者而言都意味着每天节省数小时的调试时间,过去 Claude 能在编程领域迅速崛起,很大程度上是因为 ChatGPT 在代码能力上的相对滞后。
但窗口期终有关闭的一天,伴随着 GPT-5 在代码编程任务和 Agent 能力的提升,结合 OpenAI 更强的生态绑定和产品分发渠道,一旦 Cursor 和 Copilot 回流 OpenAI,将极大撼动 Anthropic 的收入。
也许很快,我们就能看到 Claude 5 的到来。
