要进行深度学习开发和实验,您可以选择自己构建硬件平台,也可以从GPU提供商那里购买使用服务。 本文介绍了rare technologies Shiva manne对几个主要GPU平台的评估结果,希望帮助企业和开发人员选择最适合自己的平台。
最近发表了使用word2vec的大规模机器学习基准测试文章。 请参见https://goo.gl/gndD16。 本文就成本、易用性、稳定性、可扩展性、性能等实用性与几个常用的硬件供应商进行了机器学习框架的比较。 由于该基准只关注CPU,因此在GPU上再次进行了同样的机器学习基准。
平台
此次基准测试包括亚马逊网络服务AWS EC2、谷歌云引擎(GCE )、IBM软件层、以太网、纸张空间、阅读器GPU等硬件平台
由于现代机器学习任务大多使用GPU,所以了解不同GPU提供商的成本和性能之间的权衡很重要。
感谢所有这些提供商。 感谢您在测试过程中慷慨提供的基准得分和出色的支持。 详细介绍和比较所有这些平台,每个平台都有自己的相对优势和短板,GPU AAS (GPU作为服务)市场本身也非常令人兴奋和活跃。
备注:微软azure是唯一没有任何回应的主要供应商,实际上也没有从他们的官方支持频道得到任何回应。 )
在该硬件提供商的列表中,有提供虚拟实例(AWS、GCE )、裸机基础设施(Softlayer )、专用服务器)的公司,也有专注于提供比较新的GPUaaS的玩家) 根据每个平台上实例的价格,将GPU分为两类——“预算型”和“高端型”(见表1 )。 我们的目标是看高端实例是否需要那么多钱。
基准测试设定
任务
因为我们RARE Technologies经常需要解决自然语言处理(NLP )的问题,所以我为这个基准任务设定了情感分类任务。 我们必须训练双向LSTM来执行推文的二元分类任务。 算法的选择并不重要。对于这个基准,我真正追求的只是算法是计算负荷高的。 为了最大限度地提高GPU利用率,我们使用Keras的CuDNN支持的高速LSTM实现了——CuDNNLSTM。
CuDNNLSTM地址: https://keras.io /层/当前/# cudnlstm
数据集
使用了Twitter的情感分析数据集。 此数据集包含1,578,627条分类推文。 关于各行,如果感情是积极的则标记为1,如果感情是消极的则标记为0。 模型使用90%的数据(混洗)训练4 epoch,剩下的10%的残存数据用于模型评价。
推特情感分析数据集: http://think nook.com/Twitter-sentiment-analysis -培训-公司-数据集- 2012-09-22 /
解码器
为了重现性,我们创建了一个NVIDIAdocker镜像,其中包含重复执行基准任务所需的所有依赖关系和数据。 这个Dockerfile和所有必要的代码都在这个GitHub库中。 3359 github.com/rare -技术/benchmark _ GPU _平台
完全公开了设置方法和代码。 这样,任何人不仅可以再现这些结果,还可以与你自己的硬件平台和其他算法选择进行交换,从而进行你自己的基准测试。
结果

表1 )基准测试结果的总结。
* * *这些是多个GPU的实例,模型使用Keras的multi_gpu_model函数在所有GPU上进行了训练,但后来发现,该方法在使用多个GPU方面居第二位。
* * *基于上述原因,这些多GPU实例中的模型培训只使用了一个GPU。
Hetzner按月提供专用服务器。 这里给出的价格是换算成每小时的价格。
评估:订单、设置和易用性
以前的文章根据自己的经验推荐使用AWS、Softlayer和GCE。 通过LeaderGPU和Paperspace订购实例相当简单,不需要复杂的设置。 Paperspace和LeaderGPU所需的准备时间比AWS和GCE所需的几秒钟的准备时间稍长(几分钟)。
LeaderGPU、亚马逊、Paperspace提供了免费的深度学习机器镜像,其中还提供了预装了NVIDIA驱动程序和Python开发环境的免费NVIDIA坞站3354, 这可以让工作变得轻松,但是对于只是想实验机器学习模式的初学者来说,我决定使用旧的一方
式从头开始设置一切(对 LeaderGPU 除外),以便评估为满足个体需求而定制实例的难度。在这个过程中,我遇到了在所有平台上都很常见的一些问题,比如英伟达驱动与已安装的 gcc 版本不兼容,或 GPU 使用量在安装驱动之后就达到了 100%,但又没有证据表明运行着什么进程。还有意外的情况——在 Paperspace 低端实例(P6000)上运行我的 Docker 时出现了一个错误。这个问题的原因是 Docker 上的 TensorFlow 是使用 CPU 优化(MSSE、MAVX、MFMA)从源编译的,而 Paperspace 实例不支持这些 CPU 优化。不使用这些优化再运行 Docker 就行了。
就稳定性而言,我没在这些平台上遇到任何问题。
成本
不出所料,专用服务器是控制成本的最佳选择。这是因为 Hetzner 是按月收费的,换算成每小时的价格就非常低。当然,这个数字是均摊之后的,但只要你有足够多的任务保证服务器足够繁忙,那么就能保证成本低廉。在虚拟实例提供商中,显而易见的赢家是 Paperspace。对于低端 GPU,在 Paperspace 上训练一个模型的成本只有在 AWS 上的一半。在高端 GPU 方面 Paperspace 也有类似的优势。
下图是将表 1 相应部分总结成的图表:

图 1:在各种不同的 GPU 硬件平台上为 Twitter 情绪分类任务(约 150 万条推文,4 epoch)训练一个双向 LSTM 的成本。
AWS 和 GCE 在高端和低端 GPU 上的成本优势各有不同。在低端 GPU 方面 GCE 比 AWS 便宜很多,而在高端 GPU 方面 GCE 则比 AWS 稍贵一点。这说明昂贵的 AWS GPU 的额外成本可能是值得的,能够提供物有所值的价值。
IBM Softlayer 和 LeaderGPU 看起来很贵,这主要是由于他们的多 GPU 实例使用率不足。这个基准评测是使用 Keras 框架执行的,而 Keras 框架的多 GPU 实现的效率非常低,有时候甚至还比不上在同一台机器上运行的单个 GPU。但 IBM Softlayer 和 LeaderGPU 这两个平台都不提供单个 GPU 实例。在 Softlayer 上运行的基准评测通过 Keras 的 multi_gpu_model 函数使用了所有可用的 GPU,而在 LeaderGPU 上运行的基准评测只使用了可用 GPU 中的一个。这就导致出现了资源利用不足所造成的额外成本。另外,LeaderGPU 分别以和 GTX 1080 与 Tesla P100 一样的价格提供了更强大的 GPU——GTX 1080 Ti 和 Tesla V100。在这些服务器上运行肯定能降低整体成本。考虑到这些因素,在该图中的 LeaderGPU 的低端成本实际上还是相当划算的。尤其是犹豫的犀牛计划使用能更好地利用多 GPU 的非 Keras 框架时。
另外似乎还有另一个普遍趋势——更便宜的 GPU 的性价比优于更昂贵的 GPU;这说明训练时间的减少不能抵消总体成本的增长。
关于使用 Keras 训练多 GPU 模型的备注
学术界和行业很多人都非常喜欢使用 Keras 等高级 API 来开发深度学习模型。因为这是接受度最高和开发活动最活跃的深度学习框架之一,用户期望无需额外的处理就能切换成多 GPU 模型。但实际情况肯定不是如此,如下图给出的证据。多 GPU 的加速效果是相当难以预料的——在「双 GTX 1080」服务器上多 GPU 训练有明显的加速,而在「双 P100」服务器上多 GPU 的训练速度甚至比单 GPU 还慢。在我调查这个成本问题时,我也在 GitHub 上看到了其它一些对此的博客和问题讨论。
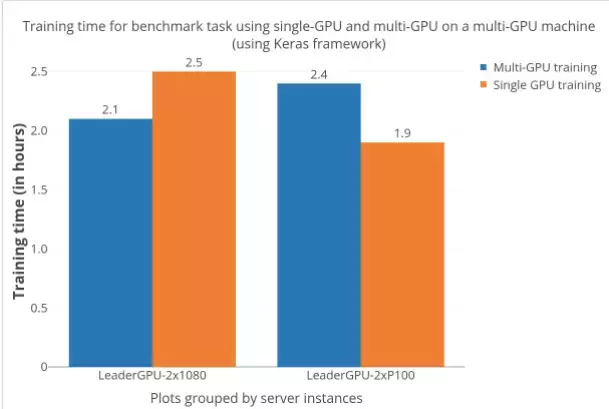
图 2:使用 Keras 在多 GPU 和单个 GPU(这些机器的其它方面完全一样)上训练所用的训练时间。
模型准确度
对于健全性测试(sanity testing),我们在训练结束时检测了最终的模型准确度。在表 1 中可以看到,没有显著的差异表明底层的硬件/平台对训练质量有影响,所以该基准评测的设置是正确的。
硬件定价
GPU 价格经常变化,但目前来看,AWS 以 0.9 美元/小时的起步价提供 K80 GPU(p2 实例),并且按使用秒数计费,而更强大和性能更高的 Tesla V100 GPU(p3 实例)的起步价为 3.06 美元/小时。其它服务还包括数据迁移、弹性 IP 地址和 EBS 优化实例,这些需要额外的成本。GCE 是一个经济实惠的选择,可以分别以 0.45 美元/小时和 1.46 美元/小时的起步价提供 Tesla K80 和 P100。这些都是按秒收费的,并且还提供了激励方案,会根据使用情况提供折扣。尽管与 AWS 不同,它们需要附加到一个 CPU 实例上(0.0475 美元/小时的 n1-standard-1)。
在低成本方面,Paperspace 和 GCE 在专用 GPU 费率上差不多,从 0.4 美元/小时的 Quadro M4000 到 2.3 美元/小时的 Tesla V100。除了通常的按小时付费,它们也有按月收费的模式(5 美元/月),其中包含存储和维护费用。Paperspace 按毫秒收费,额外付费可以购买附加服务。Hetzner 只提供了一种按月收费的使用 GTX 1080 的专用服务器,另外还需要一次额外的安装费用。
IBM Softlayer 是市场上按月和按小时提供裸机 GPU 服务器的少数几家平台之一。它提供 3 种 GPU 服务器(包含 Tesla M60 和 K80),起步价 2.8 美元/小时。这些服务器有静态配置,意味着相比于其它云提供商,其定制可能性很有限。Softlayer 的按小时收费方式更加糟糕,事实上在短期运行的任务上成本更高。
LeaderGPU 是一个相对较新的玩家,提供使用各种 GPU(P100、V100、GTX 1080、GTX 1080Ti)的专用服务器。用户可以按月、按小时或按分钟(按秒计费)选择付费方案。服务器最小的有 2 GPU,一直到 8 GPU,价格从 0.02 欧元/分到 0.08 欧元/分。
Spot/Preemptive 实例
某些平台为它们空闲的计算能力提供了很大的折扣(50%-90%)(AWS 的 spot 实例和 GCE 的 preemptive 实例),但它们可能会出人意料地终止服务。因为无法保证该实例什么时候才会再次上线,所以训练时间很难预测。对于可以应付这种中断的应用而言,这可能没什么问题,但很多任务(比如实例时间有限的项目)在这种情况下没什么好处(尤其是考虑到人力时间的浪费时)。在 preemptive/spot 实例上运行任务需要额外的代码才能很好地处理实例的中断和重启(检查点/将数据存储到永久磁盘等)。另外,价格波动(就 AWS 的情况)会导致成本随基准评测运行时的计算能力供需情况而发生变化。需要多次运行才能得到平均成本。鉴于我完成本基准评测的时间有限,所以我没有做 spot/preemptive 实例的评测。
总结点评
Paperspace 在性能和成本上似乎领先一步,对于只是想实验深度学习技术的偶尔使用一次/不经常使用的用户而言尤其如此;另一份评测报告也有类似的结果,参阅:https://goo.gl/rL02rs
专用服务器(比如 LeaderGPU 提供的那种)和裸机服务器(比如 Hetzner)很适合考虑长期使用这些资源的重度用户。注意,因为它们在服务器定制方面的灵活性较小,所以要确保你的任务是 CPU/GPU 高度密集型的,这样才能受益于定价。
不要忽视 Paperspace 和 LeaderGPU 这样更新的提供商,因为它们可以帮助减少大量成本。因为相关的惯性和平台切换成本,企业可能并不愿意更换提供商,但这些更小的平台确实值得考虑。
对于想要实现与提供商的其它服务集成整合(人工智能集成——亚马逊的 Rekognition、谷歌的 Cloud AI)的人来说,AWS 和 GCE 可能是非常棒的选择。
除非你计划运行需要数天时间才能完成的任务,否则坚持使用低端单 GPU 实例才是最好的选择(参阅:http://minimaxir.com/2017/11/benchmark-gpus)。
高端 GPU 速度快得多,但投资回报率(ROI)实际上更差。只有当更短的训练时间(更低的研发周期延迟)比更高的硬件成本更重要时,你才应该选择高端 GPU。
